VideoMAE
1.0.0
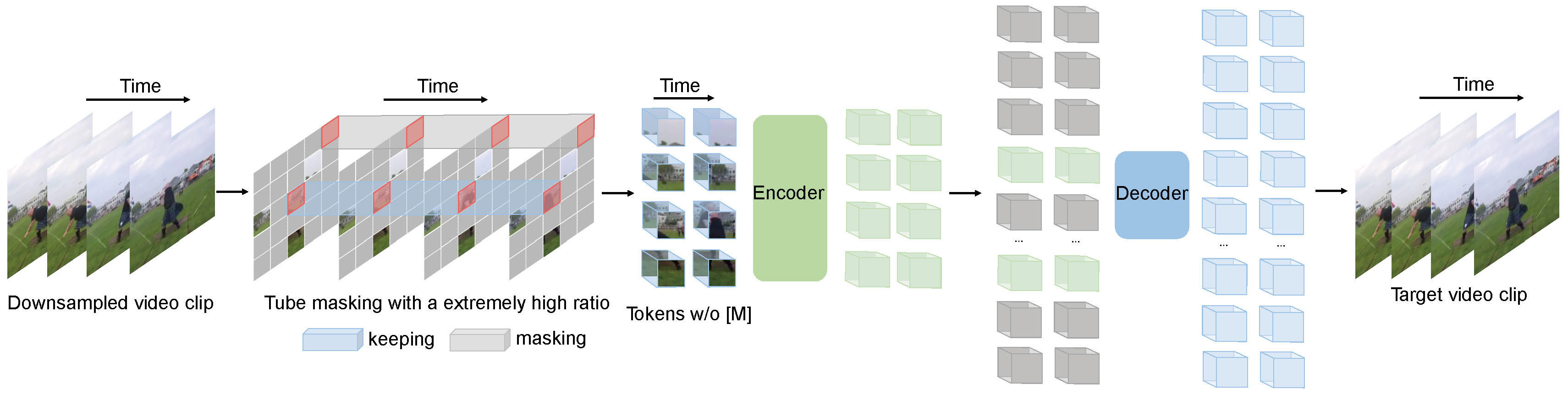
Videomae: Autoencoder bertopeng adalah pelajar yang hemat data untuk video pra-pelatihan yang di-swadaya
Zhan Tong, lagu Yibing, Jue Wang, Limin Wang
Universitas Nanjing, Tencent AI Lab
[2023.4.18] ? Semua orang dapat mengunduh Kinetics-400 , yang digunakan dalam videomae, dari tautan ini.
[2023.4.18] Kode dan model Videomae V2 yang sudah terlatih telah dirilis! Periksa dan nikmati repo ini!
[2023.4.17] Kami mengusulkan EVAD , kerangka kerja deteksi aksi video ujung ke ujung .
[2023.2.28] Videomae V2 kami diterima oleh CVPR 2023 ! ?
[2023.1.16] Kode dan model pra-terlatih untuk deteksi tindakan di videomae tersedia!
[2022.12.27] ? Semua orang dapat mengunduh fitur videomae yang diekstraksi dari Thumos , ActivityNet , HACS, dan Finalction dari Internvideo.
[2022.11.20] ? Videomae diintegrasikan ke dalam dan, didukung oleh @sayak Paul.
[2022.10.25] ? Videomae diintegrasikan ke dalam MMACTION2, hasil pada kinetika-400 dapat direproduksi dengan sukses.
[2022.10.20] Model dan skrip pra-terlatih dari VIT-S dan VIT-H tersedia!
[2022.10.19] Model dan skrip pra-terlatih pada UCF101 tersedia!
[2022.9.15] Videomae diterima oleh Neurips 2022 sebagai presentasi sorotan ! ?
[2022.8.8] ? Videomae diintegrasikan ke dalam resmi ? Transformator Huggingface Sekarang!
[2022.7.7] Kami telah memperbarui hasil baru pada benchmark AVA 2.2 hilir. Silakan merujuk ke makalah kami untuk detailnya.
[2022.4.24] Kode dan model pra-terlatih tersedia sekarang!
[2022.3.24] Kode dan model pra-terlatih akan dirilis di sini. Selamat datang untuk menonton repositori ini untuk pembaruan terbaru.
Videomae melakukan tugas pemodelan video bertopeng untuk pra-pelatihan video. Kami mengusulkan rasio masking yang sangat tinggi (90%-95%) dan strategi masking tube untuk menciptakan tugas yang menantang untuk pra-pelatihan video yang di-swadaya.
Videomae menggunakan autoencoder bertopeng sederhana dan backbone vit polos untuk melakukan pembelajaran yang di-swise-invised video. Karena rasio masking yang sangat tinggi, waktu pra-pelatihan videomae jauh lebih pendek daripada metode pembelajaran kontras (speedup 3,2x ). Videomae dapat berfungsi sebagai garis dasar yang sederhana namun kuat untuk penelitian di masa depan dalam pra-pelatihan video yang di-swadaya.
Videomae bekerja dengan baik untuk set data video dari skala yang berbeda dan dapat mencapai 87,4% pada Kinect-400, 75,4% pada sesuatu-sesuatu V2, 91,3% pada UCF101, dan 62,6% pada HMDB51. Sepengetahuan kami, Videomae adalah yang pertama mencapai kinerja canggih pada empat tolok ukur populer ini dengan backbones vanilla vit sementara tidak memerlukan data tambahan atau model pra-terlatih.
| Metode | Data tambahan | Tulang punggung | Resolusi | #Frames x klip x tanaman | Top-1 | Top-5 |
|---|---|---|---|---|---|---|
| Videomae | TIDAK | Vit-s | 224x224 | 16x2x3 | 66.8 | 90.3 |
| Videomae | TIDAK | Vit-b | 224x224 | 16x2x3 | 70.8 | 92.4 |
| Videomae | TIDAK | Vit-l | 224x224 | 16x2x3 | 74.3 | 94.6 |
| Videomae | TIDAK | Vit-l | 224x224 | 32x1x3 | 75.4 | 95.2 |
| Metode | Data tambahan | Tulang punggung | Resolusi | #Frames x klip x tanaman | Top-1 | Top-5 |
|---|---|---|---|---|---|---|
| Videomae | TIDAK | Vit-s | 224x224 | 16x5x3 | 79.0 | 93.8 |
| Videomae | TIDAK | Vit-b | 224x224 | 16x5x3 | 81.5 | 95.1 |
| Videomae | TIDAK | Vit-l | 224x224 | 16x5x3 | 85.2 | 96.8 |
| Videomae | TIDAK | Vit-H | 224x224 | 16x5x3 | 86.6 | 97.1 |
| Videomae | TIDAK | Vit-l | 320x320 | 32x4x3 | 86.1 | 97.3 |
| Videomae | TIDAK | Vit-H | 320x320 | 32x4x3 | 87.4 | 97.6 |
Silakan periksa kode dan pos pemeriksaan dalam deteksi videomae-action.
| Metode | Data tambahan | Label tambahan | Tulang punggung | #Frame x laju sampel | peta |
|---|---|---|---|---|---|
| Videomae | Kinetics-400 | ✗ | Vit-s | 16x4 | 22.5 |
| Videomae | Kinetics-400 | ✓ | Vit-s | 16x4 | 28.4 |
| Videomae | Kinetics-400 | ✗ | Vit-b | 16x4 | 26.7 |
| Videomae | Kinetics-400 | ✓ | Vit-b | 16x4 | 31.8 |
| Videomae | Kinetics-400 | ✗ | Vit-l | 16x4 | 34.3 |
| Videomae | Kinetics-400 | ✓ | Vit-l | 16x4 | 37.0 |
| Videomae | Kinetics-400 | ✗ | Vit-H | 16x4 | 36.5 |
| Videomae | Kinetics-400 | ✓ | Vit-H | 16x4 | 39.5 |
| Videomae | Kinetics-700 | ✗ | Vit-l | 16x4 | 36.1 |
| Videomae | Kinetics-700 | ✓ | Vit-l | 16x4 | 39.3 |
| Metode | Data tambahan | Tulang punggung | UCF101 | HMDB51 |
|---|---|---|---|---|
| Videomae | TIDAK | Vit-b | 91.3 | 62.6 |
| Videomae | Kinetics-400 | Vit-b | 96.1 | 73.3 |
Harap ikuti instruksi di install.md.
Harap ikuti instruksi dalam dataset.md untuk persiapan data.
Instruksi pra-pelatihan ada di pretrain.md.
Instruksi fine-tuning ada di finetune.md.
Kami menyediakan model pra-terlatih dan disesuaikan di model_zoo.md.
Kami menyediakan skrip untuk visualisasi di vis.sh Colab Notebook untuk visualisasi yang lebih baik akan segera hadir.
Zhan Tong: [email protected]
Terima kasih kepada Ziteng Gao, Lei Chen, Chongjian GE, dan Zhiyu Zhao atas dukungan baik mereka.
Proyek ini dibangun di atas Mae-Pytorch dan Beit. Terima kasih kepada kontributor basis kode yang hebat ini.
Mayoritas proyek ini dirilis di bawah lisensi CC-by-NC 4.0 seperti yang ditemukan dalam file lisensi. Porsi proyek tersedia di bawah ketentuan lisensi terpisah: SlowFast dan model-model-model dilisensikan di bawah lisensi Apache 2.0. Beit dilisensikan di bawah lisensi MIT.
Jika menurut Anda proyek ini bermanfaat, jangan ragu untuk meninggalkan Star️ dan mengutip kertas kami:
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{videomae,
title={VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
journal={arXiv preprint arXiv:2203.12602},
year={2022}
}


