VideoMAE
1.0.0
Videomae: los autoencoders enmascarados son alumnos de eficiencia de datos para la capacitación de video auto-supervisado
Zhan Tong, Yibing Song, Jue Wang, Limin Wang
Universidad de Nanjing, Tencent Ai Lab
[2023.4.18] ? Todos pueden descargar Kinetics-400 , que se usa en Videomae, desde este enlace.
[2023.4.18] ¡Se han lanzado el código y los modelos previamente capacitados de Videomae V2! ¡Compruebe y disfrute de este repositorio!
[2023.4.17] Proponemos EVAD , un marco de detección de acción de video de extremo a extremo .
[2023.2.28] ¡ Our CVPR 2023 acepta nuestras videoma V2! ?
[2023.1.16] El código y los modelos previamente capacitados para la detección de acción en Videomae están disponibles!
[2022.12.27] ? Todos pueden descargar las características de videoma extraídas de Thumos , ActivityNet , HACS y Fineaction de Internvideo.
[2022.11.20] ? Videomae está integrado y respaldado por @sayak Paul.
[2022.10.25] ? Videomae se integra en MMACTION2, los resultados en Kinetics-400 se pueden reproducir con éxito.
[2022.10.20] ¡Están disponibles los modelos y scripts previamente capacitados de VIT-S y VIT-H !
[2022.10.19] ¡Están disponibles los modelos y scripts previamente capacitados en UCF101 !
[2022.9.15] ¡ Las videoma son aceptadas por Neurips 2022 como una presentación de foco ! ?
[2022.8.8] ? Videomae está integrado en Oficial ? ¡Huggingface Transformers ahora!
[2022.7.7] Hemos actualizado nuevos resultados en el punto de referencia AVA 2.2 aguas abajo. Consulte nuestro artículo para obtener más detalles.
[2022.4.24] ¡ El código y los modelos previamente capacitados están disponibles ahora!
[2022.3.24] El código y los modelos previamente capacitados se lanzarán aquí. Bienvenido a ver este repositorio para obtener las últimas actualizaciones.
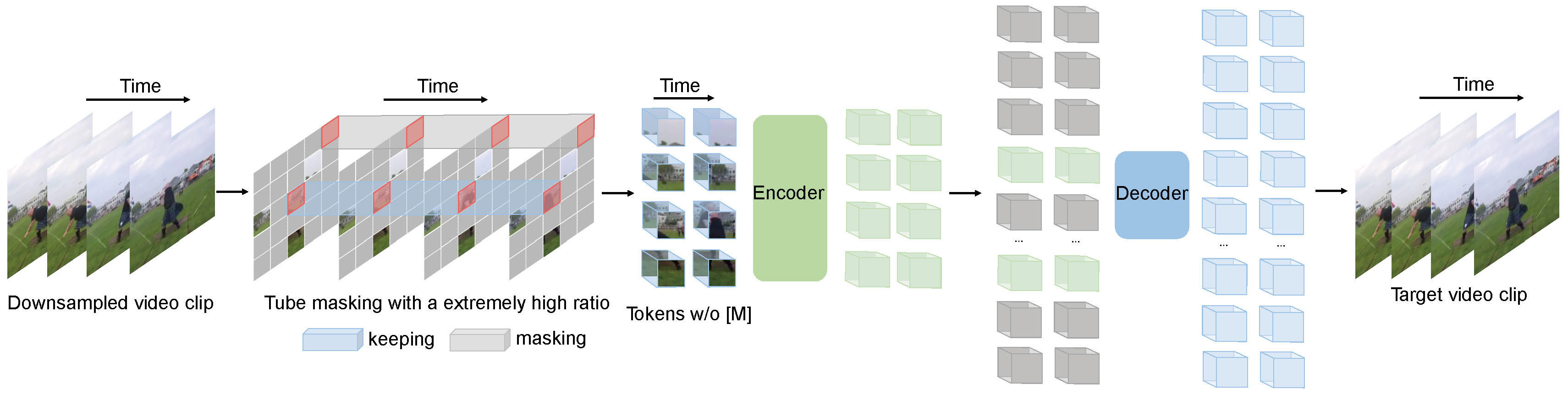
Videomae realiza la tarea del modelado de video enmascarado para la pretrabenamiento de video. Proponemos la relación de enmascaramiento extremadamente alta (90%-95%) y la estrategia de enmascaramiento de tubos para crear una tarea desafiante para el pretraben de videos auto-supervisado.
Videomae utiliza el autoencoder enmascarado simple y la columna vertebral de Vit Plain para realizar el aprendizaje auto-supervisado de video. Debido a la relación de enmascaramiento extremadamente alta, el tiempo previo a la capacitación de las videoma es mucho más corto que los métodos de aprendizaje contrastante ( 3,2x aceleración). Videomae puede servir como una línea de base simple pero fuerte para futuras investigaciones en la capacitación de video auto-supervisada.
Videomae funciona bien para conjuntos de datos de video de diferentes escalas y puede lograr un 87.4% en Kinects-400, 75.4% en algo y tantos V2, 91.3% en UCF101 y 62.6% en HMDB51. Hasta nuestro mejor conocimiento, Videomae es la primera en lograr el rendimiento de vanguardia en estos cuatro puntos de referencia populares con las troncal de Vanilla Vit, mientras que no necesitan datos adicionales o modelos previamente capacitados.
| Método | Datos adicionales | Columna vertebral | Resolución | #Frames x clips x cultivos | Top-1 | Top-5 |
|---|---|---|---|---|---|---|
| Videomas | No | VIT-S | 224x224 | 16x2x3 | 66.8 | 90.3 |
| Videomas | No | VIT-B | 224x224 | 16x2x3 | 70.8 | 92.4 |
| Videomas | No | Vit-l | 224x224 | 16x2x3 | 74.3 | 94.6 |
| Videomas | No | Vit-l | 224x224 | 32x1x3 | 75.4 | 95.2 |
| Método | Datos adicionales | Columna vertebral | Resolución | #Frames x clips x cultivos | Top-1 | Top-5 |
|---|---|---|---|---|---|---|
| Videomas | No | VIT-S | 224x224 | 16x5x3 | 79.0 | 93.8 |
| Videomas | No | VIT-B | 224x224 | 16x5x3 | 81.5 | 95.1 |
| Videomas | No | Vit-l | 224x224 | 16x5x3 | 85.2 | 96.8 |
| Videomas | No | VIT-H | 224x224 | 16x5x3 | 86.6 | 97.1 |
| Videomas | No | Vit-l | 320x320 | 32x4x3 | 86.1 | 97.3 |
| Videomas | No | VIT-H | 320x320 | 32x4x3 | 87.4 | 97.6 |
Verifique el código y los puntos de control en la detección de videomae-acción.
| Método | Datos adicionales | Etiqueta extra | Columna vertebral | #Frame x frecuencia de muestreo | mapa |
|---|---|---|---|---|---|
| Videomas | Cinética-400 | ✗ | VIT-S | 16x4 | 22.5 |
| Videomas | Cinética-400 | ✓ | VIT-S | 16x4 | 28.4 |
| Videomas | Cinética-400 | ✗ | VIT-B | 16x4 | 26.7 |
| Videomas | Cinética-400 | ✓ | VIT-B | 16x4 | 31.8 |
| Videomas | Cinética-400 | ✗ | Vit-l | 16x4 | 34.3 |
| Videomas | Cinética-400 | ✓ | Vit-l | 16x4 | 37.0 |
| Videomas | Cinética-400 | ✗ | VIT-H | 16x4 | 36.5 |
| Videomas | Cinética-400 | ✓ | VIT-H | 16x4 | 39.5 |
| Videomas | Cinética-700 | ✗ | Vit-l | 16x4 | 36.1 |
| Videomas | Cinética-700 | ✓ | Vit-l | 16x4 | 39.3 |
| Método | Datos adicionales | Columna vertebral | UCF101 | HMDB51 |
|---|---|---|---|---|
| Videomas | No | VIT-B | 91.3 | 62.6 |
| Videomas | Cinética-400 | VIT-B | 96.1 | 73.3 |
Siga las instrucciones en install.md.
Siga las instrucciones en DataSet.md para la preparación de datos.
La instrucción previa a la capacitación está en el pretrin.md.
La instrucción de ajuste fino está en Finetune.md.
Proporcionamos modelos previamente capacitados y ajustados en model_zoo.md.
Proporcionamos el script para la visualización en vis.sh El cuaderno de Colab para una mejor visualización llegará pronto.
Zhan Tong: [email protected]
Gracias a Ziteng Gao, Lei Chen, Chongjian Ge y Zhiyu Zhao por su amable apoyo.
Este proyecto se basa en Mae-Pytorch y Beit. Gracias a los contribuyentes de estas grandes bases de código.
La mayoría de este proyecto se publica bajo la licencia CC-by-NC 4.0 como se encuentra en el archivo de licencia. Las porciones del proyecto están disponibles en términos de licencia separados: Slowfast y los modelos de imagen Pytorch tienen licencia bajo la licencia Apache 2.0. Beit tiene licencia bajo la licencia MIT.
Si cree que este proyecto es útil, no dude en dejar una estrella y citar nuestro artículo:
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{videomae,
title={VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
journal={arXiv preprint arXiv:2203.12602},
year={2022}
}


