VideoMAE
1.0.0
Videomae: AutoEncoders в масках-это эффективные данные для самоотверженного видео перед тренировкой
Zhan Tong, Yibing Song, Jue Wang, Limin Wang
Университет Нанкин, Tencent AI Lab
[2023.4.18] ? Каждый может скачать Kinetics-400 , которая используется в Videomae, по этой ссылке.
[2023.4.18] были выпущены код и предварительно обученные модели Videomae v2! Проверьте и наслаждайтесь этим репо!
[2023.4.17] Мы предлагаем Эвада , сквозной структуры обнаружения видео .
[2023.2.28] Наши Videomae v2 приняты CVPR 2023 ! ?
[2023.1.16] Доступны код и предварительно обученные модели для обнаружения действий в Videomae!
[2022.12.27] ? Каждый может скачать извлеченные функции Videomae Thumos , ActivityNet , HACS и Fineaction из Internvideo.
[2022.11.20] ? Videomae интегрируется и, поддерживается @Sayak Paul.
[2022.10.25] ? Videomae интегрированы в MMAction2, результаты Kinetics-400 могут быть успешно воспроизведены.
[2022.10.20] Доступны предварительно обученные модели и сценарии Vit-S и Vit-H !
[2022.10.19] Доступны предварительно обученные модели и сценарии на UCF101 !
[2022.9.15] Videomae принимается Neurips 2022 в качестве презентации в центре внимания ! ?
[2022.8.8] ? Videomae интегрирована в официальные ?
[2022.7.7] Мы обновили новые результаты на нижнем этаже AVA 2.2. Пожалуйста, обратитесь к нашей статье для получения подробной информации.
[2022.4.24] Код и предварительно обученные модели теперь доступны!
[2022.3.24] Код и предварительно обученные модели будут выпущены здесь. Добро пожаловать, чтобы посмотреть этот репозиторий для последних обновлений.
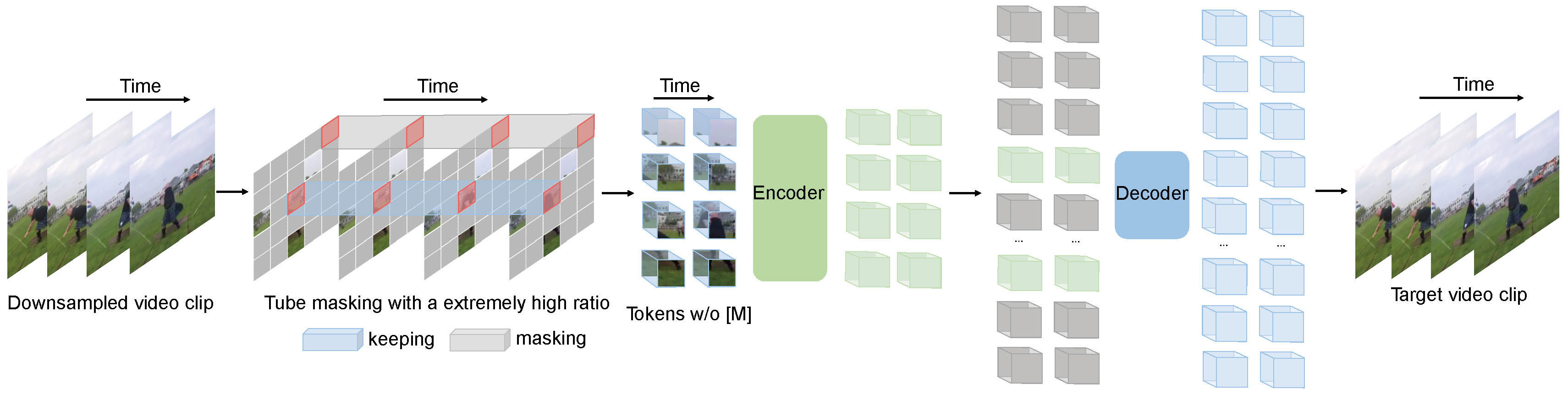
Videomae выполняет задачу моделирования видео в масках для предварительного обучения видео. Мы предлагаем чрезвычайно высокий коэффициент маскировки (90%-95%) и стратегию маскировки труб , чтобы создать сложную задачу для самоотверженного видео предварительного обучения.
Videomae использует простой маскированный автопододер и простые основы Vit для выполнения видео самоуверенного обучения. Из-за чрезвычайно высокого коэффициента маскировки время предварительного обучения видеомам намного короче, чем методы контрастного обучения ( 3,2X ускорения). Videomae может служить простым, но сильным базовым уровнем для будущих исследований в самоупреждении видео предварительной тренировки.
Videomae хорошо работает для видеобаттов видео различных масштабов и может достичь 87,4% на Kinects-400, 75,4% на чем-то с чем-то, что V2, 91,3% на UCF101 и 62,6% на HMDB51. Насколько нам известно, Videomae является первым , кто достиг современной производительности на этих четырех популярных тестах с основополагающими костями Vitilly Vit, в то время как не нужны дополнительные данные или предварительно обученные модели.
| Метод | Дополнительные данные | Магистраль | Разрешение | #Frames x Clips x культуры | Топ-1 | Топ-5 |
|---|---|---|---|---|---|---|
| Видеомат | нет | Vit-S. | 224x224 | 16x2x3 | 66.8 | 90.3 |
| Видеомат | нет | Vit-b | 224x224 | 16x2x3 | 70.8 | 92.4 |
| Видеомат | нет | Vit-l | 224x224 | 16x2x3 | 74.3 | 94.6 |
| Видеомат | нет | Vit-l | 224x224 | 32x1x3 | 75,4 | 95.2 |
| Метод | Дополнительные данные | Магистраль | Разрешение | #Frames x Clips x культуры | Топ-1 | Топ-5 |
|---|---|---|---|---|---|---|
| Видеомат | нет | Vit-S. | 224x224 | 16x5x3 | 79,0 | 93,8 |
| Видеомат | нет | Vit-b | 224x224 | 16x5x3 | 81.5 | 95.1 |
| Видеомат | нет | Vit-l | 224x224 | 16x5x3 | 85,2 | 96.8 |
| Видеомат | нет | Vit-H | 224x224 | 16x5x3 | 86.6 | 97.1 |
| Видеомат | нет | Vit-l | 320x320 | 32x4x3 | 86.1 | 97.3 |
| Видеомат | нет | Vit-H | 320x320 | 32x4x3 | 87.4 | 97.6 |
Пожалуйста, проверьте код и контрольные точки в обнаружении Videomae-Action.
| Метод | Дополнительные данные | Дополнительная этикетка | Магистраль | #Frame x Скорость дискретизации | карта |
|---|---|---|---|---|---|
| Видеомат | Кинетика-400 | ✗ | Vit-S. | 16x4 | 22.5 |
| Видеомат | Кинетика-400 | ✓ | Vit-S. | 16x4 | 28.4 |
| Видеомат | Кинетика-400 | ✗ | Vit-b | 16x4 | 26.7 |
| Видеомат | Кинетика-400 | ✓ | Vit-b | 16x4 | 31.8 |
| Видеомат | Кинетика-400 | ✗ | Vit-l | 16x4 | 34.3 |
| Видеомат | Кинетика-400 | ✓ | Vit-l | 16x4 | 37.0 |
| Видеомат | Кинетика-400 | ✗ | Vit-H | 16x4 | 36.5 |
| Видеомат | Кинетика-400 | ✓ | Vit-H | 16x4 | 39,5 |
| Видеомат | Кинетика-700 | ✗ | Vit-l | 16x4 | 36.1 |
| Видеомат | Кинетика-700 | ✓ | Vit-l | 16x4 | 39,3 |
| Метод | Дополнительные данные | Магистраль | UCF101 | HMDB51 |
|---|---|---|---|---|
| Видеомат | нет | Vit-b | 91.3 | 62,6 |
| Видеомат | Кинетика-400 | Vit-b | 96.1 | 73,3 |
Пожалуйста, следуйте инструкциям в install.md.
Пожалуйста, следуйте инструкциям в DataSet.md для подготовки данных.
Инструкция перед тренировкой находится в предварительном.
Инструкция с тонкой настройкой находится в Finetune.md.
Мы предоставляем предварительно обученные и тонкие модели в Model_zoo.md.
Мы предоставляем сценарий для визуализации в vis.sh Колаб ноутбук для лучшей визуализации скоро появится.
Zhan Tong: [email protected]
Благодаря Ziteng Gao, Lei Chen, Chongjian GE и Zhiyu Zhao за их любезную поддержку.
Этот проект построен на Mae-Pytorch и Beit. Спасибо участникам этих великих кодовых баз.
Большая часть этого проекта выпускается по лицензии CC-BY-NC 4.0, как это было найдено в файле лицензии. Части проекта доступны в соответствии с отдельными условиями лицензии: медленные и пирожные модели лицензированы по лицензии Apache 2.0. Бейт лицензирован по лицензии MIT.
Если вы думаете, что этот проект полезен, пожалуйста, не стесняйтесь оставить звезду и цитировать нашу газету:
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{videomae,
title={VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
journal={arXiv preprint arXiv:2203.12602},
year={2022}
}


