VideoMAE
1.0.0
VideoMAMEE:マスクされた自動エンコーダーは、自己監視されたビデオ事前トレーニングのためのデータ効率の高い学習者です
Zhan Tong、Yibing Song、Jue Wang、Limin Wang
南京大学、テンセントAIラボ
[2023.4.18] ?このリンクから、VideOMAEで使用されるKinetics-400を誰でもダウンロードできます。
[2023.4.18] VideoMAMOMAE V2のコードと事前に訓練されたモデルがリリースされました!このレポをチェックしてお楽しみください!
[2023.4.17]エンドツーエンドのビデオアクション検出フレームワークであるEvadを提案します。
[2023.2.28]私たちのVideoMomae V2はCVPR 2023によって受け入れられています! ?
[2023.1.16] VideOMAMEEでのアクション検出のためのコードと事前に訓練されたモデルが利用可能です!
[2022.12.27] ? Thumos 、 ActivityNet 、 HACS、およびFineActionの抽出されたVideOMAMAE機能をInternvideoからダウンロードできます。
[2022.11.20] ? VideoMomaeは、@sayak Paulによって統合され、サポートされています。
[2022.10.25] ? VideOMAMEはMMACTION2に統合されており、Kinetics-400の結果は正常に再現できます。
[2022.10.20] VIT-SとVIT-Hの事前に訓練されたモデルとスクリプトが利用可能です!
[2022.10.19] UCF101の事前に訓練されたモデルとスクリプトが利用可能です!
[2022.9.15] VideoMomaeは、 SpotlightプレゼンテーションとしてNeurips 2022に受け入れられています! ?
[2022.8.8] ? VideoMomaeは、公式のFace Transformersに公式に統合されています!
[2022.7.7]ダウンストリームAVA 2.2ベンチマークで新しい結果を更新しました。詳細については、私たちの論文を参照してください。
[2022.4.24]コードと事前に訓練されたモデルが現在入手可能です!
[2022.3.24]コードと事前に訓練されたモデルはここからリリースされます。最新のアップデートについては、このリポジトリをご覧ください。
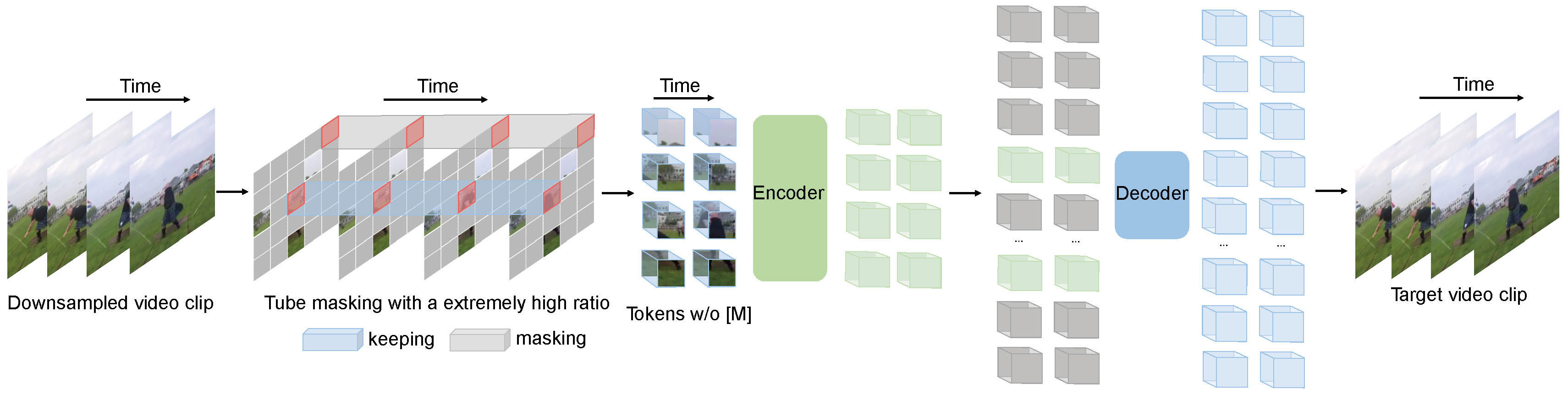
VideoMomaeは、ビデオプリトレーニングのためにマスクされたビデオモデリングのタスクを実行します。非常に高いマスキング比(90%-95%)とチューブマスキング戦略を提案して、自己補助的なビデオのトレーニングのための挑戦的なタスクを作成します。
VideOMAMEは、シンプルなマスクされた自動エンコーダーとプレーンVITバックボーンを使用して、ビデオスルーパーバイザーの学習を実行します。マスキング比が非常に高いため、VideOMAMEEのトレーニング前の時間は、対照的な学習方法よりもはるかに短くなっています( 3.2倍のスピードアップ)。 VideoMomaeは、自己監視されたビデオの事前トレーニングにおける将来の研究のためのシンプルだが強力なベースラインとして機能します。
VideoMomaeは、さまざまなスケールのビデオデータセットに適しており、Kinects-400で87.4% 、V2で75.4% 、UCF101で91.3% 、HMDB51で62.6%を達成できます。私たちの最高の知識のために、VideMomaeは、これらの4つの人気のあるベンチマークでバニラvitバックボーンで最先端のパフォーマンスを達成した最初の人物ですが、追加のデータや事前に訓練されたモデルは必要ありません。
| 方法 | 追加データ | バックボーン | 解決 | #フレームxクリップx作物 | Top-1 | トップ5 |
|---|---|---|---|---|---|---|
| Videmomae | いいえ | vit-s | 224x224 | 16x2x3 | 66.8 | 90.3 |
| Videmomae | いいえ | vit-b | 224x224 | 16x2x3 | 70.8 | 92.4 |
| Videmomae | いいえ | vit-l | 224x224 | 16x2x3 | 74.3 | 94.6 |
| Videmomae | いいえ | vit-l | 224x224 | 32x1x3 | 75.4 | 95.2 |
| 方法 | 追加データ | バックボーン | 解決 | #フレームxクリップx作物 | Top-1 | トップ5 |
|---|---|---|---|---|---|---|
| Videmomae | いいえ | vit-s | 224x224 | 16x5x3 | 79.0 | 93.8 |
| Videmomae | いいえ | vit-b | 224x224 | 16x5x3 | 81.5 | 95.1 |
| Videmomae | いいえ | vit-l | 224x224 | 16x5x3 | 85.2 | 96.8 |
| Videmomae | いいえ | vit-h | 224x224 | 16x5x3 | 86.6 | 97.1 |
| Videmomae | いいえ | vit-l | 320x320 | 32x4x3 | 86.1 | 97.3 |
| Videmomae | いいえ | vit-h | 320x320 | 32x4x3 | 87.4 | 97.6 |
VideoMomae-action-edtectionのコードとチェックポイントを確認してください。
| 方法 | 追加データ | 追加ラベル | バックボーン | #frame xサンプルレート | 地図 |
|---|---|---|---|---|---|
| Videmomae | 速度論-400 | ✗ | vit-s | 16x4 | 22.5 |
| Videmomae | 速度論-400 | ✓✓ | vit-s | 16x4 | 28.4 |
| Videmomae | 速度論-400 | ✗ | vit-b | 16x4 | 26.7 |
| Videmomae | 速度論-400 | ✓✓ | vit-b | 16x4 | 31.8 |
| Videmomae | 速度論-400 | ✗ | vit-l | 16x4 | 34.3 |
| Videmomae | 速度論-400 | ✓✓ | vit-l | 16x4 | 37.0 |
| Videmomae | 速度論-400 | ✗ | vit-h | 16x4 | 36.5 |
| Videmomae | 速度論-400 | ✓✓ | vit-h | 16x4 | 39.5 |
| Videmomae | 速度論-700 | ✗ | vit-l | 16x4 | 36.1 |
| Videmomae | 速度論-700 | ✓✓ | vit-l | 16x4 | 39.3 |
| 方法 | 追加データ | バックボーン | UCF101 | HMDB51 |
|---|---|---|---|---|
| Videmomae | いいえ | vit-b | 91.3 | 62.6 |
| Videmomae | 速度論-400 | vit-b | 96.1 | 73.3 |
install.mdの指示に従ってください。
データの準備については、dataset.mdの指示に従ってください。
トレーニング前の指導はpretrain.mdです。
微調整命令はFinetune.mdです。
Model_zoo.mdで事前に訓練された微調整モデルを提供します。
vis.shで視覚化のためのスクリプトを提供します。より良い視覚化のためのコラブノートブックはまもなく登場します。
Zhan Tong:[email protected]
Ziteng Gao、Lei Chen、Chongjian GE、およびZhiyu Zhaoの親切なサポートに感謝します。
このプロジェクトは、Mae-PytorchとBeitに基づいて構築されています。これらの素晴らしいコードベースの貢献者に感謝します。
このプロジェクトの大部分は、ライセンスファイルにあるように、CC-NC 4.0ライセンスの下でリリースされます。プロジェクトの一部は、個別のライセンス条件で入手できます:SlowfastおよびPytorch-Image-Modelsは、Apache 2.0ライセンスに基づいてライセンスされています。 BeitはMITライセンスに基づいてライセンスされています。
このプロジェクトが役立つと思われる場合は、星のままにしてお気軽にお問い合わせください。
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{videomae,
title={VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
journal={arXiv preprint arXiv:2203.12602},
year={2022}
}


