VideoMAE
1.0.0
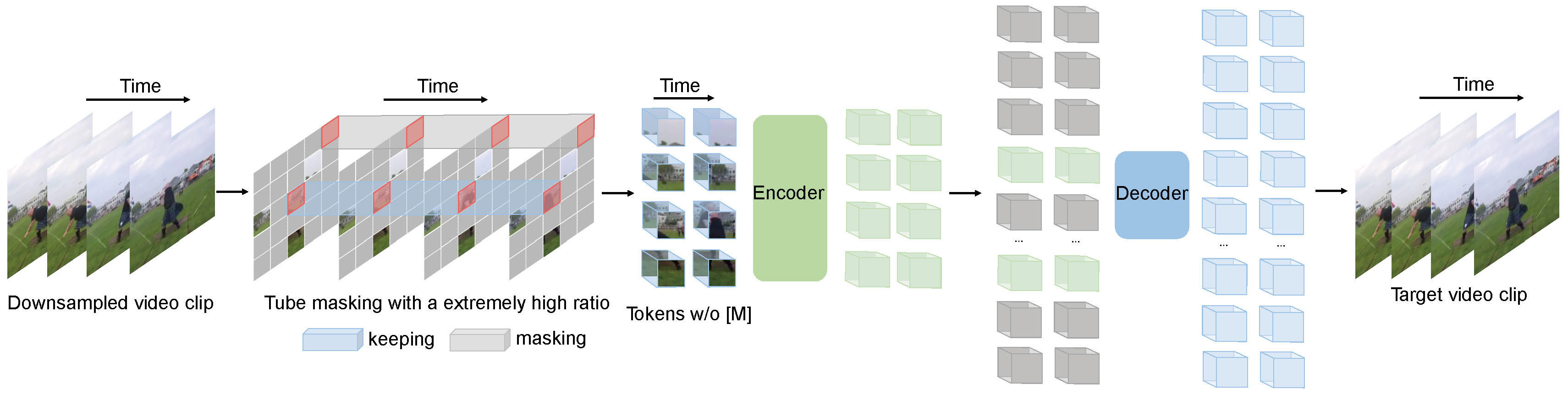
Videomae: les autoencodeurs masqués sont des apprenants économes en matière de données pour la pré-formation vidéo auto-supervisée
Zhan Tong, Song Yibing, Jue Wang, Limin Wang
Université Nanjing, Tencent Ai Lab
[2023.4.18] ? Tout le monde peut télécharger Kinetics-400 , qui est utilisé dans Videomae, à partir de ce lien.
[2023.4.18] Le code et les modèles pré-formés de Videomae v2 ont été publiés! Vérifiez et profitez de ce dépôt!
[2023.4.17] Nous proposons EVAD , un cadre de détection d'action vidéo de bout en bout .
[2023.2.28] Notre Videomae v2 est acceptée par CVPR 2023 ! ?
[2023.1.16] Le code et les modèles pré-formés pour la détection d'action dans Videomae sont disponibles!
[2022.12.27] ? Tout le monde peut télécharger des fonctionnalités videomae extraites de Thumos , ActivityNet , HACS et FineAction de InternVideo.
[2022.11.20] ? Videomae est intégré et, soutenu par @sayak Paul.
[2022.10.25] ? Videomae est intégré dans MMAction2, les résultats sur la cinétique-400 peuvent être reproduits avec succès.
[2022.10.20] Les modèles et scripts pré-formés de Vit-S et Vit-H sont disponibles!
[2022.10.19] Les modèles et scripts pré-formés sur UCF101 sont disponibles!
[2022.9.15] Videomae est accepté par les Neirips 2022 comme présentation des projecteurs ! ?
[2022.8.8] ? Videomae est intégrée dans les transformateurs officiels ? HuggingFace maintenant!
[2022.7.7] Nous avons mis à jour de nouveaux résultats sur la référence AVA 2.2 en aval. Veuillez vous référer à notre article pour plus de détails.
[2022.4.24] Le code et les modèles pré-formés sont disponibles maintenant!
[2022.3.24] Le code et les modèles pré-formés seront publiés ici. Bienvenue pour regarder ce référentiel pour les dernières mises à jour.
Videomae effectue la tâche de la modélisation vidéo masquée pour la pré-formation vidéo. Nous proposons le rapport de masquage extrêmement élevé (90% -95%) et la stratégie de masquage de tube pour créer une tâche difficile pour la pré-formation vidéo auto-supervisée.
Videomae utilise l'autoencodeur masqué simple et la squelette Vit simple pour effectuer un apprentissage vidéo auto-supervisé vidéo. En raison du rapport de masquage extrêmement élevé, le temps de pré-formation des vidéomae est beaucoup plus court que les méthodes d'apprentissage contrastives (accélération de 3,2x ). Videomae peut servir de base simple mais forte pour les recherches futures en pré-formation vidéo auto-supervisée.
Videomae fonctionne bien pour les ensembles de données vidéo de différentes échelles et peut atteindre 87,4% sur Kinects-400, 75,4% sur quelque chose de V2 quelque chose, 91,3% sur UCF101 et 62,6% sur HMDB51. À notre meilleure connaissance, Videomae est la première à atteindre les performances de pointe de ces quatre références populaires avec les épine dorsales Vanilla Vit tout en ne nécessitant pas de données supplémentaires ou de modèles pré-formés.
| Méthode | Données supplémentaires | Colonne vertébrale | Résolution | #Frames x clips x cultures | Top-1 | Top 5 |
|---|---|---|---|---|---|---|
| Videomae | Non | Vit-s | 224x224 | 16x2x3 | 66.8 | 90.3 |
| Videomae | Non | Vit-b | 224x224 | 16x2x3 | 70.8 | 92.4 |
| Videomae | Non | Vit-l | 224x224 | 16x2x3 | 74.3 | 94.6 |
| Videomae | Non | Vit-l | 224x224 | 32x1x3 | 75.4 | 95.2 |
| Méthode | Données supplémentaires | Colonne vertébrale | Résolution | #Frames x clips x cultures | Top-1 | Top 5 |
|---|---|---|---|---|---|---|
| Videomae | Non | Vit-s | 224x224 | 16x5x3 | 79.0 | 93.8 |
| Videomae | Non | Vit-b | 224x224 | 16x5x3 | 81.5 | 95.1 |
| Videomae | Non | Vit-l | 224x224 | 16x5x3 | 85.2 | 96.8 |
| Videomae | Non | Vit-h | 224x224 | 16x5x3 | 86.6 | 97.1 |
| Videomae | Non | Vit-l | 320x320 | 32x4x3 | 86.1 | 97.3 |
| Videomae | Non | Vit-h | 320x320 | 32x4x3 | 87.4 | 97.6 |
Veuillez cocher le code et les points de contrôle dans la détection de l'action VideoMae.
| Méthode | Données supplémentaires | Étiquette supplémentaire | Colonne vertébrale | #Frame x Taux d'échantillon | carte |
|---|---|---|---|---|---|
| Videomae | Cinétique-400 | ✗ | Vit-s | 16x4 | 22.5 |
| Videomae | Cinétique-400 | ✓ | Vit-s | 16x4 | 28.4 |
| Videomae | Cinétique-400 | ✗ | Vit-b | 16x4 | 26.7 |
| Videomae | Cinétique-400 | ✓ | Vit-b | 16x4 | 31.8 |
| Videomae | Cinétique-400 | ✗ | Vit-l | 16x4 | 34.3 |
| Videomae | Cinétique-400 | ✓ | Vit-l | 16x4 | 37.0 |
| Videomae | Cinétique-400 | ✗ | Vit-h | 16x4 | 36.5 |
| Videomae | Cinétique-400 | ✓ | Vit-h | 16x4 | 39.5 |
| Videomae | Cinétique-700 | ✗ | Vit-l | 16x4 | 36.1 |
| Videomae | Cinétique-700 | ✓ | Vit-l | 16x4 | 39.3 |
| Méthode | Données supplémentaires | Colonne vertébrale | UCF101 | HMDB51 |
|---|---|---|---|---|
| Videomae | Non | Vit-b | 91.3 | 62.6 |
| Videomae | Cinétique-400 | Vit-b | 96.1 | 73.3 |
Veuillez suivre les instructions dans install.md.
Veuillez suivre les instructions dans DataSet.MD pour la préparation des données.
L'instruction de pré-formation est dans Pretrain.md.
L'instruction de réglage fin est dans finetune.md.
Nous fournissons des modèles pré-formés et affinés dans Model_zoo.md.
Nous fournissons le script pour la visualisation dans vis.sh Colab Notebook pour une meilleure visualisation arrive bientôt.
Zhan Tong: [email protected]
Merci à Ziteng Gao, Lei Chen, Chongjian GE et Zhiyu Zhao pour leur aimable soutien.
Ce projet est construit sur Mae-Pytorch et Beit. Grâce aux contributeurs de ces grandes bases de code.
La majorité de ce projet est publié dans le cadre de la licence CC-BY-NC 4.0 comme dans le fichier de licence. Des parties du projet sont disponibles selon des termes de licence séparés: SlowFast et Pytorch-Image-Models sont concédés sous licence Apache 2.0. Beit est concédé sous licence MIT.
Si vous pensez que ce projet est utile, n'hésitez pas à quitter une étoile et citer notre article:
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{videomae,
title={VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
journal={arXiv preprint arXiv:2203.12602},
year={2022}
}


