VideoMAE
1.0.0
Videomae: Maskierte Autoencodierer sind dateneffiziente Lernende für selbstüberwachende Video-Vor-Training
Zhan Tong, Yibing -Lied, Jue Wang, Limin Wang
Nanjing University, Tencent AI Lab
[2023.4.18] ? Jeder kann Kinetics-400 , das in Videomae verwendet wird, von diesem Link herunterladen.
[2023.4.18] Code und vorgebildete Modelle von Videomae V2 wurden veröffentlicht! Überprüfen Sie und genießen Sie dieses Repo!
[2023.4.17] Wir schlagen EVAD vor, ein End-to-End-Video-Aktionserkennungsrahmen .
[2023.2.28] Unser Videomae V2 wird von CVPR 2023 akzeptiert! ?
[2023.1.16] Code und vorgebildete Modelle zur Aktionserkennung in Videomae sind verfügbar!
[2022.12.27] ? Jeder kann extrahierte Videomae -Funktionen von Thumos , Activitynet , HACs und Finection von Internvideo herunterladen.
[2022.11.20] ? Videomae ist in integriert und unterstützt von @sayak Paul.
[2022.10.25] ? Videomae ist in MMACTION2 integriert, die Ergebnisse in Kinetics-400 können erfolgreich reproduziert werden.
[2022.10.20] Die vorgebauten Modelle und Skripte von VIT-S und VIT-H sind erhältlich!
[2022.10.19] Die vorgebildeten Modelle und Skripte auf UCF101 sind verfügbar!
[2022.9.15] Videomae wird von Neurips 2022 als Spotlight -Präsentation akzeptiert! ?
[2022.8.8] ? Videomae ist jetzt in offizielle ? Huggingface -Transformatoren integriert!
[2022.7.7] Wir haben neue Ergebnisse auf dem nachgelagerten AVA 2.2 -Benchmark aktualisiert. Weitere Informationen finden Sie in unserem Artikel.
[2022.4.24] Code und vorgeborene Modelle sind ab sofort verfügbar!
[2022.3.24] Hier werden Code und vorgeborene Modelle veröffentlicht. Willkommen, dieses Repository für die neuesten Updates zu sehen .
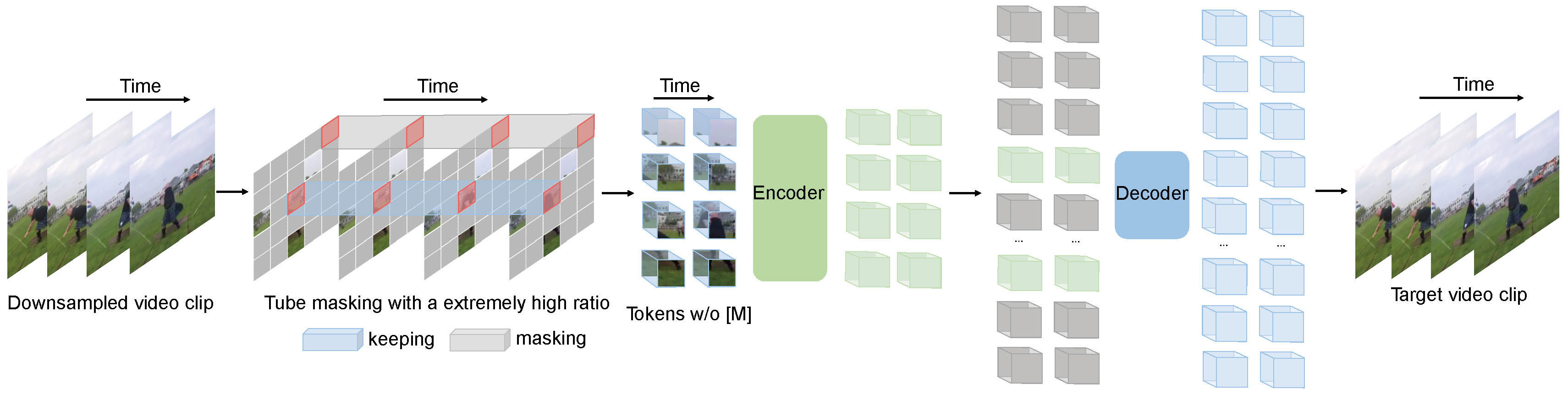
Videomae führt die Aufgabe der maskierten Videomodellierung für Video-Voraussetzungen aus. Wir schlagen die extrem hohe Maskierungsverhältnis (90%-95%) und die Röhrenmaskierungsstrategie vor, um eine herausfordernde Aufgabe für selbst überprüfte Video-Voraussetzungen zu erstellen.
Videomae verwendet das einfache maskierte AutoCoder und das einfache VIT- Rückgrat, um das selbstbewertete Video mit Videos durchzuführen. Aufgrund des extrem hohen Maskierungsverhältnisses ist die Zeit vor dem Training von Videomae viel kürzer als kontrastive Lernmethoden ( 3,2-fache Beschleunigung). Videomae können als einfache, aber starke Grundlinie für zukünftige Forschungsergebnisse in selbst überprüften Videos vor dem Training dienen.
Videomae eignet sich gut für Video-Datensätze verschiedener Skalen und kann 87,4% für Kinects-400, 75,4% auf etwas V2, 91,3% auf UCF101 und 62,6% auf HMDB51 erreichen. Zu unserem besten Wissen ist Videomae als erster, das die hochmoderne Leistung dieser vier beliebten Benchmarks mit den Vanilla-Vit- Rückgratern erzielt, während keine zusätzlichen Daten oder vorgeborenen Modelle erforderlich sind .
| Verfahren | Zusätzliche Daten | Rückgrat | Auflösung | #Frames x Clips x Pflanzen | Top-1 | Top-5 |
|---|---|---|---|---|---|---|
| Videomae | NEIN | Vit-S | 224x224 | 16x2x3 | 66,8 | 90.3 |
| Videomae | NEIN | Vit-B | 224x224 | 16x2x3 | 70,8 | 92.4 |
| Videomae | NEIN | Vit-L | 224x224 | 16x2x3 | 74.3 | 94.6 |
| Videomae | NEIN | Vit-L | 224x224 | 32x1x3 | 75,4 | 95.2 |
| Verfahren | Zusätzliche Daten | Rückgrat | Auflösung | #Frames x Clips x Pflanzen | Top-1 | Top-5 |
|---|---|---|---|---|---|---|
| Videomae | NEIN | Vit-S | 224x224 | 16x5x3 | 79,0 | 93.8 |
| Videomae | NEIN | Vit-B | 224x224 | 16x5x3 | 81,5 | 95.1 |
| Videomae | NEIN | Vit-L | 224x224 | 16x5x3 | 85.2 | 96,8 |
| Videomae | NEIN | Vit-H | 224x224 | 16x5x3 | 86.6 | 97.1 |
| Videomae | NEIN | Vit-L | 320x320 | 32x4x3 | 86.1 | 97.3 |
| Videomae | NEIN | Vit-H | 320x320 | 32x4x3 | 87,4 | 97.6 |
Bitte überprüfen Sie den Code und Checkpoints in der Videomae-Action-Detektion.
| Verfahren | Zusätzliche Daten | Zusätzliches Etikett | Rückgrat | #Frame x Beispielrate | Karte |
|---|---|---|---|---|---|
| Videomae | Kinetik-400 | ✗ | Vit-S | 16x4 | 22.5 |
| Videomae | Kinetik-400 | ✓ | Vit-S | 16x4 | 28.4 |
| Videomae | Kinetik-400 | ✗ | Vit-B | 16x4 | 26.7 |
| Videomae | Kinetik-400 | ✓ | Vit-B | 16x4 | 31.8 |
| Videomae | Kinetik-400 | ✗ | Vit-L | 16x4 | 34.3 |
| Videomae | Kinetik-400 | ✓ | Vit-L | 16x4 | 37.0 |
| Videomae | Kinetik-400 | ✗ | Vit-H | 16x4 | 36,5 |
| Videomae | Kinetik-400 | ✓ | Vit-H | 16x4 | 39,5 |
| Videomae | Kinetik-700 | ✗ | Vit-L | 16x4 | 36.1 |
| Videomae | Kinetik-700 | ✓ | Vit-L | 16x4 | 39.3 |
| Verfahren | Zusätzliche Daten | Rückgrat | UCF101 | HMDB51 |
|---|---|---|---|---|
| Videomae | NEIN | Vit-B | 91.3 | 62.6 |
| Videomae | Kinetik-400 | Vit-B | 96.1 | 73.3 |
Bitte befolgen Sie die Anweisungen in install.md.
Bitte befolgen Sie die Anweisungen in Dataset.md für die Datenvorbereitung.
Die Anweisung vor dem Training findet in pretrain.md statt.
Die Feinabstimmung befindet sich in finetune.md.
Wir bieten vorab ausgebildete und fein abgestimmte Modelle in model_zoo.md.
Wir bieten das Skript zur Visualisierung in vis.sh Colab Notebook für eine bessere Visualisierung kommt in Kürze.
Zhan Tong: [email protected]
Vielen Dank an Ziteng Gao, Lei Chen, Chongjian GE und Zhiyu Zhao für ihre freundliche Unterstützung.
Dieses Projekt basiert auf Mae-Pytorch und Beit. Vielen Dank an die Mitwirkenden dieser großartigen Codebasen.
Der Großteil dieses Projekts wird unter der CC-by-NC 4.0-Lizenz veröffentlicht, wie in der Lizenzdatei gefunden. Teile des Projekts sind unter separaten Lizenzbedingungen verfügbar: SlowFast und Pytorch-Image-Modelle werden unter der Apache 2.0-Lizenz lizenziert. Beit ist unter der MIT -Lizenz lizenziert.
Wenn Sie der Meinung sind, dass dieses Projekt hilfreich ist, verlassen Sie bitte einen Stern und zitieren unser Papier:
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{videomae,
title={VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
journal={arXiv preprint arXiv:2203.12602},
year={2022}
}


