VideoMAE
1.0.0
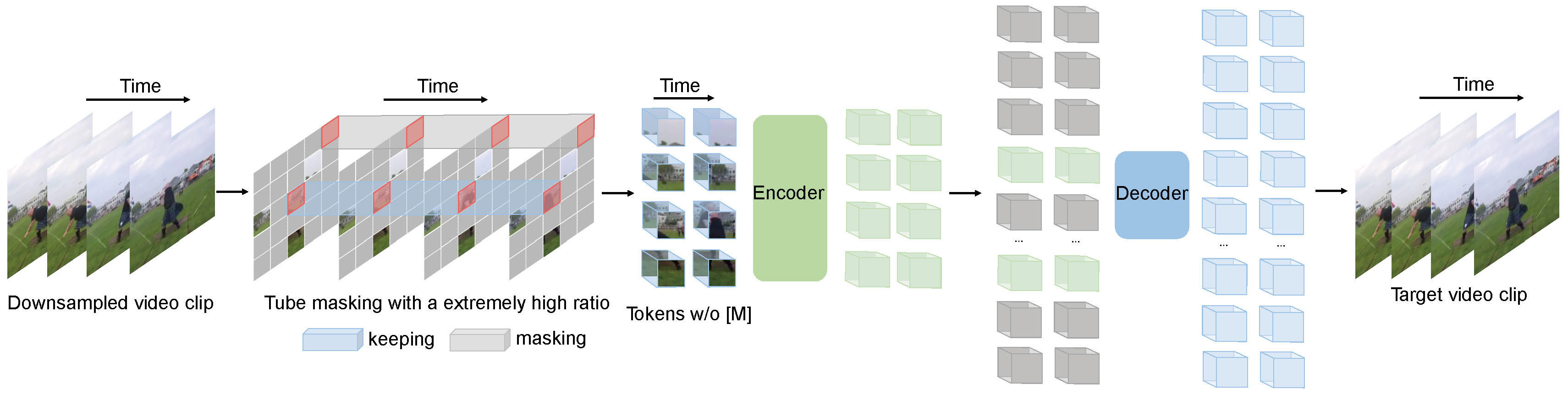
Videomae : 마스킹 된 자동 인코더는 자체 감독 비디오 사전 훈련을위한 데이터 효율적인 학습자입니다.
Zhan Tong, Yibing Song, Jue Wang, Limin Wang
Nanjing University, Tencent AI Lab
[2023.4.18] ? 모든 사람은이 링크에서 Videomae에서 사용되는 Kinetics-400을 다운로드 할 수 있습니다.
[2023.4.18] Videomae V2의 코드 및 미리 훈련 된 모델이 출시되었습니다! 이 저장소를 확인하고 즐기십시오!
[2023.4.17] 우리는 엔드 투 엔드 비디오 액션 감지 프레임 워크 인 Evad를 제안합니다.
[2023.2.28] 우리의 Videomae V2는 CVPR 2023 에 의해 받아 들여집니다! ?
[2023.1.16] Videomae의 행동 감지를 위한 코드 및 미리 훈련 된 모델이 가능합니다!
[2022.12.27] ? 모든 사람은 Internvideo에서 Thumos , Activitynet , HAC 및 Fineaction 의 추출 된 Videomae 기능을 다운로드 할 수 있습니다.
[2022.11.20] ? Videomae는 @Sayak Paul에 의해 통합되고 지원됩니다.
[2022.10.25] ? Videomae는 MMAction2에 통합되며 Kinetics-400의 결과는 성공적으로 재현 될 수 있습니다.
[2022.10.20] 미리 훈련 된 모델과 VIT-S 및 VIT-H 스크립트를 사용할 수 있습니다!
[2022.10.19] UCF101 의 미리 훈련 된 모델과 스크립트를 사용할 수 있습니다!
[2022.9.15] Videomae는 Neurips 2022 에 의해 스포트라이트 프레젠테이션으로 받아 들여집니다! ?
[2022.8.8] ? Videomae는 공식적인 ? Huggingface Transformers에 통합되어 있습니다!
[2022.7.7] 다운 스트림 AVA 2.2 벤치 마크에서 새로운 결과를 업데이트했습니다. 자세한 내용은 논문을 참조하십시오.
[2022.4.24] 코드와 미리 훈련 된 모델이 현재 사용할 수 있습니다!
[2022.3.24] 코드 및 미리 훈련 된 모델이 여기에서 출시됩니다. 최신 업데이트를 위해이 저장소를 보고 오신 것을 환영합니다.
Videomae는 비디오 사전 훈련을 위해 마스킹 된 비디오 모델링 작업을 수행합니다. 우리는 매우 높은 마스킹 비율 (90%-95%)과 튜브 마스킹 전략을 제안하여 자체 감독 비디오 사전 훈련을위한 도전적인 작업을 만듭니다.
Videomae는 간단한 마스크 된 자동 코더와 일반 Vit 백본을 사용하여 비디오 자체 감독 학습을 수행합니다. 마스킹 비율이 매우 높기 때문에 Videomae의 사전 훈련 시간은 대조 학습 방법 ( 3.2 배 속도)보다 훨씬 짧습니다 . Videomae는 자체 감독 비디오 사전 훈련에 대한 향후 연구를위한 간단하지만 강력한 기준 으로 사용될 수 있습니다.
Videomae는 다양한 규모의 비디오 데이터 세트에 적합하며 Kinects-400에서 87.4% , v2에서 75.4% , UCF101의 경우 91.3% , HMDB51에서 62.6%를 달성 할 수 있습니다. 우리가 아는 한, Videomae는 바닐라 vit 백본을 사용 하여이 인기있는 4 가지 벤치 마크에서 최신 성능을 달성 한 최초 의 데이터 또는 미리 훈련 된 모델이 필요하지 않습니다 .
| 방법 | 추가 데이터 | 등뼈 | 해결 | #Frames X Clips X 작물 | 1 위 | 상위 5 |
|---|---|---|---|---|---|---|
| 비디오 | 아니요 | vit-s | 224x224 | 16x2x3 | 66.8 | 90.3 |
| 비디오 | 아니요 | Vit-B | 224x224 | 16x2x3 | 70.8 | 92.4 |
| 비디오 | 아니요 | vit-l | 224x224 | 16x2x3 | 74.3 | 94.6 |
| 비디오 | 아니요 | vit-l | 224x224 | 32x1x3 | 75.4 | 95.2 |
| 방법 | 추가 데이터 | 등뼈 | 해결 | #Frames X Clips X 작물 | 1 위 | 상위 5 |
|---|---|---|---|---|---|---|
| 비디오 | 아니요 | vit-s | 224x224 | 16x5x3 | 79.0 | 93.8 |
| 비디오 | 아니요 | Vit-B | 224x224 | 16x5x3 | 81.5 | 95.1 |
| 비디오 | 아니요 | vit-l | 224x224 | 16x5x3 | 85.2 | 96.8 |
| 비디오 | 아니요 | VIT-H | 224x224 | 16x5x3 | 86.6 | 97.1 |
| 비디오 | 아니요 | vit-l | 320x320 | 32x4x3 | 86.1 | 97.3 |
| 비디오 | 아니요 | VIT-H | 320x320 | 32x4x3 | 87.4 | 97.6 |
Videomae-Action-Detection에서 코드 및 체크 포인트를 확인하십시오.
| 방법 | 추가 데이터 | 추가 레이블 | 등뼈 | #프레임 X 샘플 속도 | 지도 |
|---|---|---|---|---|---|
| 비디오 | 동역학 -400 | ✗ | vit-s | 16x4 | 22.5 |
| 비디오 | 동역학 -400 | ✓ | vit-s | 16x4 | 28.4 |
| 비디오 | 동역학 -400 | ✗ | Vit-B | 16x4 | 26.7 |
| 비디오 | 동역학 -400 | ✓ | Vit-B | 16x4 | 31.8 |
| 비디오 | 동역학 -400 | ✗ | vit-l | 16x4 | 34.3 |
| 비디오 | 동역학 -400 | ✓ | vit-l | 16x4 | 37.0 |
| 비디오 | 동역학 -400 | ✗ | VIT-H | 16x4 | 36.5 |
| 비디오 | 동역학 -400 | ✓ | VIT-H | 16x4 | 39.5 |
| 비디오 | 동역학 -700 | ✗ | vit-l | 16x4 | 36.1 |
| 비디오 | 동역학 -700 | ✓ | vit-l | 16x4 | 39.3 |
| 방법 | 추가 데이터 | 등뼈 | UCF101 | HMDB51 |
|---|---|---|---|---|
| 비디오 | 아니요 | Vit-B | 91.3 | 62.6 |
| 비디오 | 동역학 -400 | Vit-B | 96.1 | 73.3 |
install.md의 지침을 따르십시오.
데이터 준비는 Dataset.md의 지침을 따르십시오.
사전 훈련 명령은 pretrain.md에 있습니다.
미세 조정 지침은 Finetune.md에 있습니다.
Model_zoo.md에서 미리 훈련 된 미세 조정 모델을 제공합니다.
우리는 vis.sh 에서 시각화를위한 스크립트를 제공합니다. 더 나은 시각화를위한 Colab 노트북이 곧 출시 될 예정입니다.
Zhan Tong : [email protected]
Ziteng Gao, Lei Chen, Chongjian Ge 및 Zhiyu Zhao에게 친절한 지원을 주셔서 감사합니다.
이 프로젝트는 Mae-Pytorch와 Beit에 기반을두고 있습니다. 이 훌륭한 코드베이스의 기고자들에게 감사합니다.
이 프로젝트의 대부분은 라이센스 파일에있는 CC-By-NC 4.0 라이센스에 따라 릴리스됩니다. 프로젝트의 일부는 별도의 라이센스 용어로 제공됩니다. 슬로우스 및 파이터-이미지 모델은 Apache 2.0 라이센스에 따라 라이센스가 부여됩니다. BEIT는 MIT 라이센스에 따라 라이센스가 부여됩니다.
이 프로젝트가 도움이된다고 생각되면 자유롭게 Starel을 남겨두고 논문을 인용하십시오.
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{videomae,
title={VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
journal={arXiv preprint arXiv:2203.12602},
year={2022}
}


