VideoMAE
1.0.0
Videomae: os autoencodentes mascarados são alunos com eficiência de dados para o vídeo auto-supervisionado pré-treinamento
Zhan Tong, música Yibing, Jue Wang, Limin Wang
Universidade de Nanjing, Tencent AI Lab
[2023.4.18] ? Todos podem baixar o Kinetics-400 , que é usado em videomae, a partir deste link.
[2023.4.18] Código e modelos pré-treinados de videomae V2 foram lançados! Verifique e aproveite este repositório!
[2023.4.17] Propomos Evad , uma estrutura de detecção de ação de vídeo de ponta a ponta .
[2023.2.28] Nossos videomae v2 são aceitos pelo CVPR 2023 ! ?
[2023.1.16] Código e modelos pré-treinados para detecção de ação em videomae estão disponíveis!
[2022.12.27] ? Todo mundo pode baixar os recursos de videoma extraído de Thumos , ActivityNet , HACs e Fineaction do InternVideo.
[2022.11.20] ? Videomae é integrado e, apoiado por @sayak Paul.
[2022.10.25] ? Videomae é integrado ao MMAction2, os resultados do Kinetics-400 podem ser reproduzidos com sucesso.
[2022.10.20] Os modelos e scripts pré-treinados de Vit-S e Vit-H estão disponíveis!
[2022.10.19] Os modelos e scripts pré-treinados no UCF101 estão disponíveis!
[2022.9.15] Videomae é aceito pelo Neurips 2022 como uma apresentação de destaque ! ?
[2022.8.8] ? Videomae está integrado ao Official ? Huggingface Transformers agora!
[2022.7.7] Atualizamos novos resultados sobre a referência AVA 2.2 a jusante. Consulte o nosso artigo para obter detalhes.
[2022.4.24] O código e os modelos pré-treinados já estão disponíveis!
[2022.3.24] Código e modelos pré-treinados serão lançados aqui. Bem -vindo ao assistir a este repositório para obter as atualizações mais recentes.
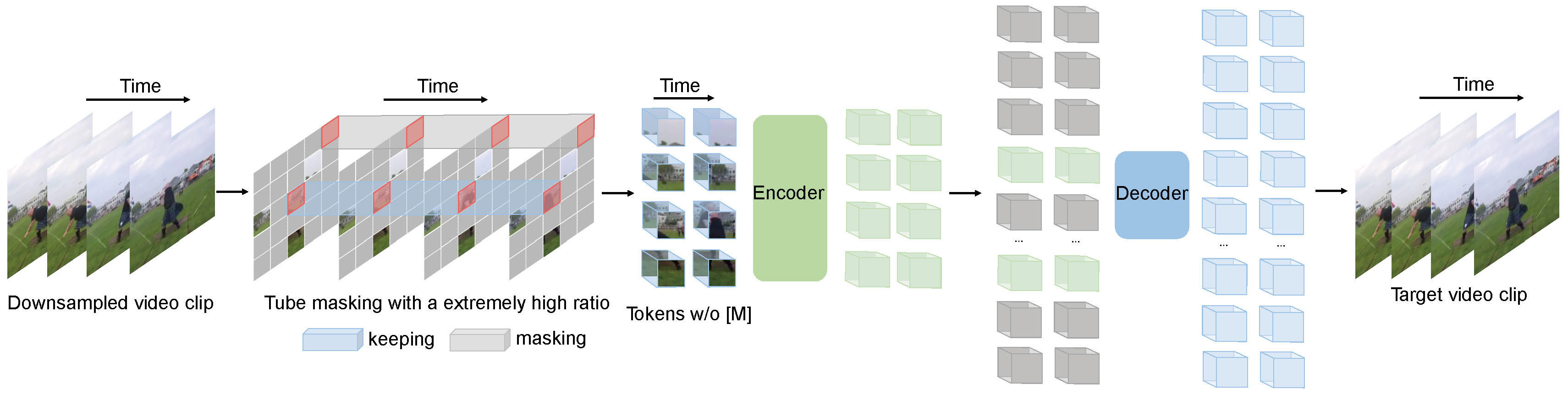
Videomae executa a tarefa de modelagem de vídeo mascarada para pré-treinamento em vídeo. Propomos a taxa de mascaramento extremamente alta (90%-95%) e a estratégia de mascaramento de tubos para criar uma tarefa desafiadora para o pré-treinamento em vídeo auto-supervisionado.
O Videomae usa o simples AutoEncoder mascarado e o backbone do Vit simples para executar o aprendizado auto-supervisionado por vídeo. Devido à taxa de mascaramento extremamente alta, o tempo de pré-treinamento das videomae é muito mais curto que os métodos de aprendizado contrastante (aceleração de 3,2x ). As videomae podem servir como uma linha de base simples, mas forte, para pesquisas futuras em pré-treinamento em vídeo auto-supervisionado.
Videomae funciona bem para conjuntos de dados de vídeo de diferentes escalas e podem atingir 87,4% nos Kinects-400, 75,4% em algo-algo v2, 91,3% no UCF101 e 62,6% no HMDB51. Para nosso melhor conhecimento, as videomae é a primeira a alcançar o desempenho de última geração nesses quatro benchmarks populares com os backbones do Vanilla VIT, enquanto não precisa de dados extras ou modelos pré-treinados.
| Método | Dados extras | Espinha dorsal | Resolução | #Frames x clipes x culturas | Top-1 | Top 5 |
|---|---|---|---|---|---|---|
| Videomae | não | Vit-S | 224x224 | 16x2x3 | 66.8 | 90.3 |
| Videomae | não | Vit-B | 224x224 | 16x2x3 | 70.8 | 92.4 |
| Videomae | não | Vit-L | 224x224 | 16x2x3 | 74.3 | 94.6 |
| Videomae | não | Vit-L | 224x224 | 32x1x3 | 75.4 | 95.2 |
| Método | Dados extras | Espinha dorsal | Resolução | #Frames x clipes x culturas | Top-1 | Top 5 |
|---|---|---|---|---|---|---|
| Videomae | não | Vit-S | 224x224 | 16x5x3 | 79.0 | 93.8 |
| Videomae | não | Vit-B | 224x224 | 16x5x3 | 81.5 | 95.1 |
| Videomae | não | Vit-L | 224x224 | 16x5x3 | 85.2 | 96.8 |
| Videomae | não | Vit-H | 224x224 | 16x5x3 | 86.6 | 97.1 |
| Videomae | não | Vit-L | 320x320 | 32x4x3 | 86.1 | 97.3 |
| Videomae | não | Vit-H | 320x320 | 32x4x3 | 87.4 | 97.6 |
Verifique o código e os pontos de verificação na detecção de videomae-ação.
| Método | Dados extras | Etiqueta extra | Espinha dorsal | #Frame x taxa de amostragem | mapa |
|---|---|---|---|---|---|
| Videomae | Cinetics-400 | ✗ | Vit-S | 16x4 | 22.5 |
| Videomae | Cinetics-400 | ✓ | Vit-S | 16x4 | 28.4 |
| Videomae | Cinetics-400 | ✗ | Vit-B | 16x4 | 26.7 |
| Videomae | Cinetics-400 | ✓ | Vit-B | 16x4 | 31.8 |
| Videomae | Cinetics-400 | ✗ | Vit-L | 16x4 | 34.3 |
| Videomae | Cinetics-400 | ✓ | Vit-L | 16x4 | 37.0 |
| Videomae | Cinetics-400 | ✗ | Vit-H | 16x4 | 36.5 |
| Videomae | Cinetics-400 | ✓ | Vit-H | 16x4 | 39.5 |
| Videomae | Kinetics-700 | ✗ | Vit-L | 16x4 | 36.1 |
| Videomae | Kinetics-700 | ✓ | Vit-L | 16x4 | 39.3 |
| Método | Dados extras | Espinha dorsal | UCF101 | HMDB51 |
|---|---|---|---|---|
| Videomae | não | Vit-B | 91.3 | 62.6 |
| Videomae | Cinetics-400 | Vit-B | 96.1 | 73.3 |
Siga as instruções no install.md.
Siga as instruções no DataSet.md para preparação de dados.
A instrução de pré-treinamento está em pré-train.md.
A instrução de ajuste fino está em Finetune.md.
Fornecemos modelos pré-treinados e ajustados em model_zoo.md.
Fornecemos o script para visualização em vis.sh O notebook Colab para uma melhor visualização está chegando em breve.
Zhan Tong: [email protected]
Graças a Ziteng Gao, Lei Chen, Chongjian GE e Zhiyu Zhao por seu apoio gentil.
Este projeto é construído sobre Mae-Pytorch e Beit. Graças aos colaboradores dessas ótimas bases de código.
A maioria deste projeto é divulgada sob a licença CC-BY-NC 4.0, conforme encontrado no arquivo de licença. Partes do projeto estão disponíveis em termos de licença separados: os modelos SlowFast e Pytorch-Image são licenciados sob a licença Apache 2.0. O BEIT está licenciado sob a licença do MIT.
Se você acha que este projeto é útil, sinta -se à vontade para deixar uma estrela e citar nosso papel:
@inproceedings{tong2022videomae,
title={Video{MAE}: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Zhan Tong and Yibing Song and Jue Wang and Limin Wang},
booktitle={Advances in Neural Information Processing Systems},
year={2022}
}
@article{videomae,
title={VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training},
author={Tong, Zhan and Song, Yibing and Wang, Jue and Wang, Limin},
journal={arXiv preprint arXiv:2203.12602},
year={2022}
}


