entity_aspect_analysis
1.0.0
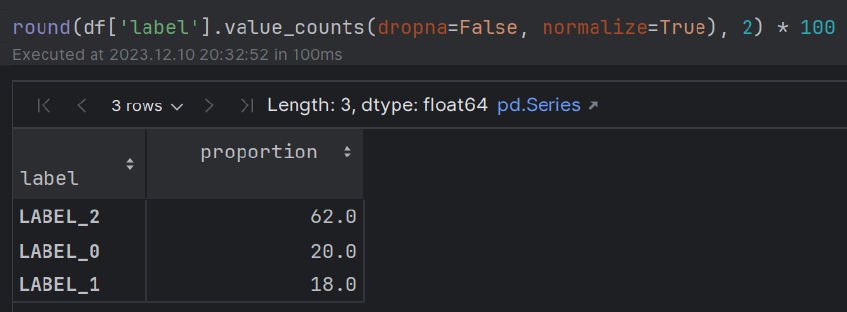
实体 +意见(方面)从客户服务评论中提取,以及针对真实带注释的标签的评估。
train.csvsample_review.csv文件(包含单个带注释的审查),以比较true-vs-pred标签。 该模块关注的是提取被审查的实体(例如,“食物”)以及审稿人对实体的看法(例如,“有点好吃”)。
该模块与对地面真相注释的实体开放元组提取的评估有关。
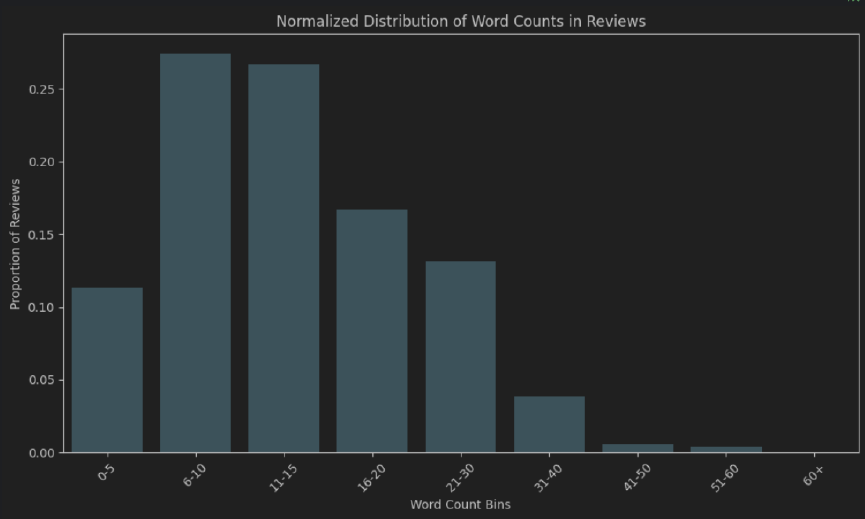
EDA.ipynb文件.py模块)运行main.py模块
笔记:
.env文件以存储您的OpenAI API密钥。OPENAI_API_KEY = "your_openai_api_key"从词典句法转变为语义 - 语法界面方法
重点是以下内容:
BERT句子转换器使用余弦相似性测量语义文本相似性。
在测试了真实VS预测的实体和观点(方面)的各种语言变化之后,设定了0.85的阈值,以接受该模型的预测到生产中。
将复杂的方法(例如句子转换者)与传统的基于规则的方法相结合,以增强结果的有效性。
例如,基于变压器的解决方案与句法依赖解析,POS和NER(语言特征)相结合,可以帮助确保“餐厅”和“餐厅”被认为是相同的(与确定者/确定者)相同,而不是上面的“美味”和“有点美味的”示例。
在这种情况下,更传统的分类指标(召回,精度,F1得分,准确性)的相关性较小。
许多混乱的矩阵组件与整个综述中的一个单词/短语的二进制分类任务无关(一次是用于实体识别,一次是在方面)。这使得无法计算其中一些指标。
此外,这些指标无法完全捕获受形容词/名词修饰符和副词强化器的包含/去除的影响的微小语义。以“美味”与“有点好吃”。
此外,这提出了一个问题,即在使用召回,精度,F1得分和准确性时是否要考虑到诸如此类的部分匹配。
但是,我确实相信,可以使用基于N-Gram的传统指标来建立基准:
尽管它确实需要进行更彻底的测试,但是用于测量Bert句子转换器嵌入语义文本相似性以及相对严格的阈值(应该大多应考虑到形容词/名词修饰符和副词强度的存在)之间的余弦相似性方法可能在生产环境中起作用。
生产环境也有其他考虑因素,例如延迟,计算时间,在服务器上托管重型模型以及额外的成本。


