entity_aspect_analysis
1.0.0
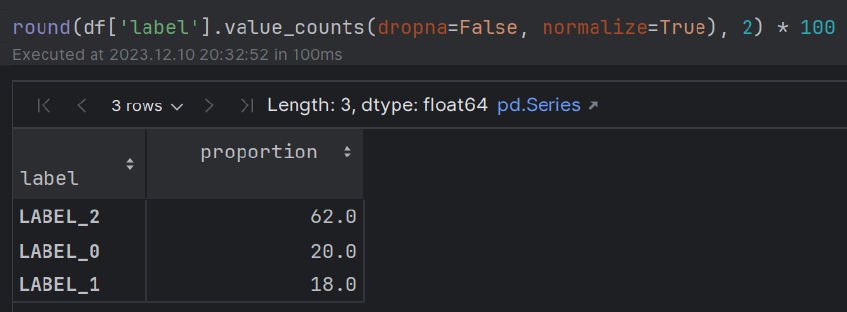
เอนทิตี + ความคิดเห็น (แง่มุม) การสกัดจากการทบทวนการบริการลูกค้าควบคู่ไปกับการประเมินผลกับป้ายกำกับที่มีคำอธิบายประกอบที่แท้จริง
train.csvsample_review.csv (มีการตรวจสอบคำอธิบายประกอบเดียว) ถูกสร้างขึ้นสำหรับการเปรียบเทียบ POC ของฉลาก TRUE-VS-PRED โมดูลนี้เกี่ยวข้องกับการสกัดเอนทิตีที่ได้รับการตรวจสอบ (เช่น 'อาหาร') ควบคู่ไปกับความคิดเห็นของผู้ตรวจสอบที่เกี่ยวข้องกับเอนทิตี (เช่น 'ค่อนข้างอร่อย')
โมดูลนี้เกี่ยวข้องกับการประเมินผลการสกัด tuple ของเอนทิตี-ตัวเลือกกับคำอธิบายประกอบความจริงภาคพื้นดิน
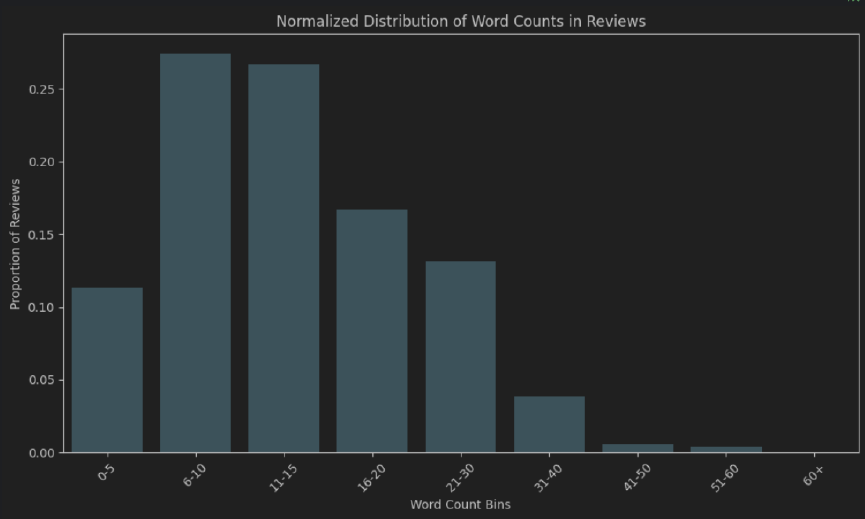
EDA.ipynb.py โมดูล) เรียกใช้โมดูล main.py
หมายเหตุ:
.env สำหรับการจัดเก็บคีย์ OpenAI API ของคุณOPENAI_API_KEY = "your_openai_api_key"การย้ายจาก lexicosyntactic ไปยังวิธีการเชื่อมต่อแบบ semantics-pragmatics
เน้นไปที่สิ่งต่อไปนี้:
Bert Sensent-Transformers สำหรับการวัดความคล้ายคลึงกันของข้อความความหมายโดยใช้ความคล้ายคลึงกันของโคไซน์
หลังจากทดสอบการเปลี่ยนแปลงทางภาษาศาสตร์ต่าง ๆ ของหน่วยงานและความคิดเห็นที่คาดการณ์ด้วย VS-VS (แง่มุม) นั้นมีการตั้งค่าเกณฑ์ 0.85 สำหรับการยอมรับการทำนายของแบบจำลองในการผลิต
การรวมวิธีการที่ซับซ้อน (เช่นการเปลี่ยนประโยค) เข้ากับวิธีการแบบดั้งเดิมตามกฎเพื่อเสริมสร้างความถูกต้องของผลลัพธ์
ตัวอย่างเช่นโซลูชันที่ใช้หม้อแปลงรวมกับการแยกวิเคราะห์การพึ่งพาวากยสัมพันธ์ POS และ NER (คุณสมบัติทางภาษา) สามารถช่วยในการทำให้แน่ใจว่า "ร้านอาหาร" และ "ร้านอาหาร" ได้รับการยกย่องว่าเป็นตัวอย่างเดียวกัน
ตัวชี้วัดการจำแนกประเภทแบบดั้งเดิมมากขึ้น (การเรียกคืนความแม่นยำ F1 คะแนนความแม่นยำ) มีความเกี่ยวข้องน้อยกว่าในกรณีนี้
ส่วนประกอบเมทริกซ์ความสับสนจำนวนมากไม่เกี่ยวข้องในงานการจำแนกแบบไบนารีของคำ/วลีเดียวจากการตรวจสอบทั้งหมด (ครั้งเดียวสำหรับการจดจำเอนทิตีและอีกครั้งสำหรับแง่มุม) สิ่งนี้ทำให้เป็นไปไม่ได้ที่จะคำนวณตัวชี้วัดเหล่านี้
นอกจากนี้ตัวชี้วัดเหล่านี้ไม่สามารถจับความหมายนาทีได้อย่างเต็มที่ได้รับอิทธิพลจากการรวม/การลบคำคุณศัพท์/คำนามตัวดัดแปลงและคำวิเศษณ์ ยกตัวอย่างเช่น“ อร่อย” เทียบกับ“ ค่อนข้างอร่อย”
ยิ่งกว่านั้นสิ่งนี้ทำให้เกิดคำถามว่าจะคำนึงถึงการไม่สนใจการจับคู่บางส่วนเช่นนี้เมื่อใช้การเรียกคืนความแม่นยำคะแนน F1 และความแม่นยำ
อย่างไรก็ตามฉันเชื่อว่าตัวชี้วัดที่ใช้ N-Gram แบบดั้งเดิมสามารถใช้เพื่อสร้างพื้นฐาน:
แม้ว่าจะต้องมีการทดสอบอย่างละเอียดมากขึ้น แต่วิธีการที่คล้ายคลึงกันของโคไซน์ที่ใช้ในการวัดความคล้ายคลึงกันของข้อความความหมายระหว่างการฝังตัวของประโยคเบิร์ตที่ฝังอยู่ข้างๆเกณฑ์ที่ค่อนข้างเข้มงวด (ซึ่งส่วนใหญ่ควรคำนึงถึงการมี/ไม่มีคำคุณศัพท์/คำนาม
นอกจากนี้ยังมีข้อควรพิจารณาเพิ่มเติมเกี่ยวกับสภาพแวดล้อมการผลิตเช่นเวลาแฝงเวลาในการคำนวณโฮสติ้งโมเดลหนักบนเซิร์ฟเวอร์และค่าใช้จ่ายเพิ่มเติม


