entity_aspect_analysis
1.0.0
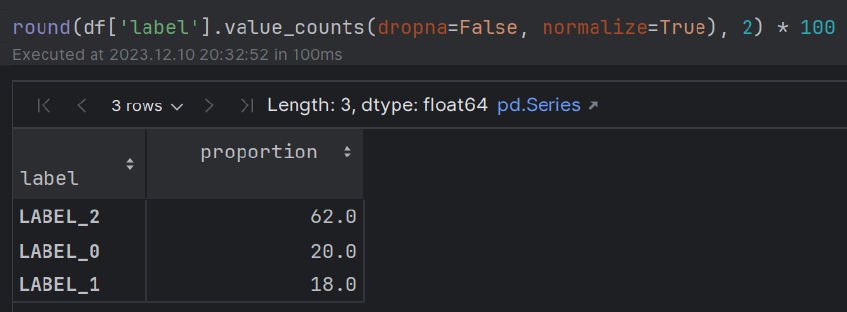
エンティティ +意見(アスペクト)カスタマーサービスレビューからの抽出は、真の注釈付きラベルに対する評価とともに。
train.csvsample_review.csvファイル(単一の注釈付きレビューを含む)が、真のVSプレッドラベルのPOC比較のために作成されました。 このモジュールは、エンティティに関するレビューアの意見(たとえば、「ややおいしい」)とともに、レビュー中のエンティティ(「食品」など)を抽出することに関係しています。
このモジュールは、グラウンドトゥルースアノテーションに対するエンティティオピニオンタプル抽出の評価に関係しています。
EDA.ipynbファイルを参照してください.pyモジュール)main.pyモジュールを実行します
注:
.envファイルを必ず作成してください。OPENAI_API_KEY = "your_openai_api_key"LexicosyntacticからSemantics-Pragmaticsインターフェイスアプローチへの移行
以下に重点が置かれました。
Cosineの類似性を使用してセマンティックテキストの類似性を測定するためのBert Sente-Transformers。
真のVS予測エンティティと意見(アスペクト)のさまざまな言語バリエーションをテストした後、モデルの生産への予測を受け入れるために0.85のしきい値が設定されました。
結果の妥当性を強化するために、洗練されたアプローチ(文の変換者など)を従来のルールベースのアプローチと組み合わせます。
たとえば、構文の依存関係解析と組み合わされたトランスベースのソリューション、POSおよびNER(言語的特徴)は、「レストラン」と「レストラン」が、上からの「おいしい」と「やや美味しい」例とは対照的に、同じ(決定的な」と見なされることを確認するのに役立ちます。
この場合、より従来の分類メトリック(リコール、精度、F1スコア、精度)はあまり関連していません。
混乱マトリックスコンポーネントの多くは、レビュー全体から1つの単語/フレーズのみのバイナリ分類タスクとは無関係です(エンティティ認識の場合は1回、アスペクトに対して1回)。これにより、これらのメトリックの一部を計算することが不可能になります。
さらに、これらのメトリックは、形容詞/名詞修飾子および副詞強化剤の包含/除去の影響を受けた微小なセマンティクスを完全にキャプチャできません。たとえば、「おいしい」対「やや美味しい」。
さらに、これは、リコール、精度、F1スコア、および精度を使用する場合、これらのような部分的な一致を無視するかどうかを考慮すべきかどうかという問題を提起します。
しかし、私は、従来のN-Gramベースのメトリックをベースラインを確立するために採用できると信じています。
より徹底的なテストが必要ですが、BERT文と変換の埋め込みと比較的厳格なしきい値を測定するための意味テキストの類似性を測定するために使用されるコサイン類似性アプローチ(これは、主に形容詞/名詞修飾子および副詞強化剤の存在/欠如を考慮に入れる必要があります)は、生産環境で機能する可能性があります。
また、レイテンシ、計算時間、サーバーでの重いモデルのホスト、追加コストなど、生産環境には追加の考慮事項があります。


