entity_aspect_analysis
1.0.0
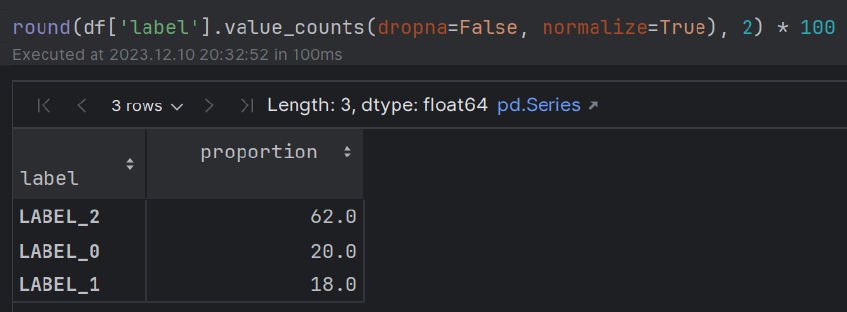
Entity + Мнение (аспект) Извлечение из обзоров обслуживания клиентов наряду с оценкой против истинных аннотированных ярлыков.
train.csvsample_review.csv (содержащий единый аннотированный обзор) для сравнения POC метелок True-VS-Pred. Этот модуль связан с извлечением объекта, которая рассматривается (например, «еда») наряду с мнением рецензента о сущности (например, «несколько вкусно»).
Этот модуль связан с оценкой извлечения кортежей сущности против наземных аннотаций правды.
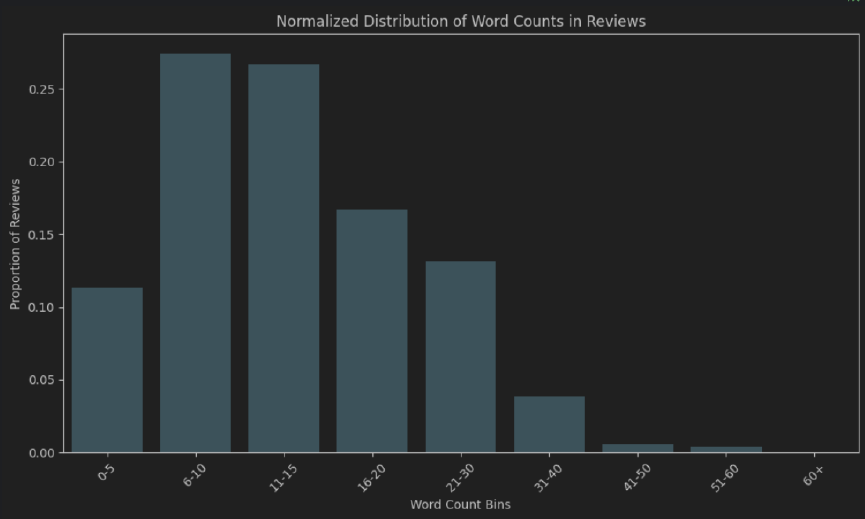
EDA.ipynb.py Modules) Запустите модуль main.py
Примечания:
.env для хранения вашего ключа API OpenAI.OPENAI_API_KEY = "your_openai_api_key"Переход от лексикосинтаксики к подходу к разделам в семантике-прагматике
Акцент был сделан на следующее:
Берт-трансформаторы предложения для измерения семантического текстового сходства с использованием сходства косинуса.
После тестирования различных лингвистических вариаций истинных VS-предсказанных сущностей и мнений (аспектов) был установлен порог 0,85 для принятия прогноза модели в производство.
Объединение сложных подходов (например, преобразователей предложений) с традиционными подходами, основанными на правилах, чтобы укрепить обоснованность результатов.
Например, решения на основе трансформаторов в сочетании с синтаксическим анализацией зависимости, POS и NER (лингвистические функции) могут помочь в том, чтобы «ресторан» и «ресторан» считались такими же (с/выходящими примером), в отличие от «вкусного» и «несколько вкусного» примера.
Более традиционные показатели классификации (отзыв, точность, F1-показатель, точность) менее актуальны в этом случае.
Многие из компонентов матрицы путаницы не имеют значения в задаче бинарной классификации только одного слова/фразы из целого обзора (один раз для распознавания сущности и один раз для аспекта). Это делает невозможным рассчитать некоторые из этих метрик.
Кроме того, эти метрики не могут полностью захватить минутную семантику под влиянием включения/удаления модификаторов прилагательных/существительных и усилителей наречия. Возьмем, к примеру, «вкусно» против «несколько вкусного».
Более того, это поднимает вопрос о том, учитывать ли учитывать, не обращают внимания на частичные совпадения, такие как они при использовании отзыва, точности, F1-показателя и точности.
Я действительно считаю, что традиционные метрики на основе N-грамма могут быть использованы для установления базовой линии:
Хотя это требует более тщательного тестирования, подход сходства косинуса, используемый для измерения семантического текстового сходства между встраиваемыми трансформаторами предложений BERT наряду с относительно строгим порогом (который должен в основном учитывать наличие/отсутствие модификаторов прилагательных/существительных и интенсивных наречие) может работать в производственной среде.
Существуют также дополнительные соображения в производственной среде, такие как задержка, время вычисления, проведение тяжелых моделей на серверах и дополнительные затраты.


