entity_aspect_analysis
1.0.0
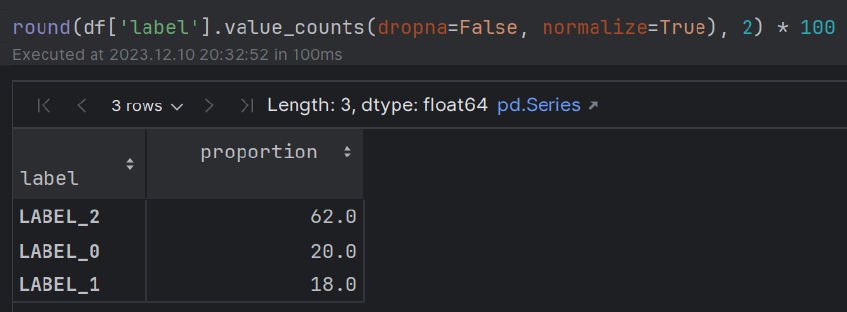
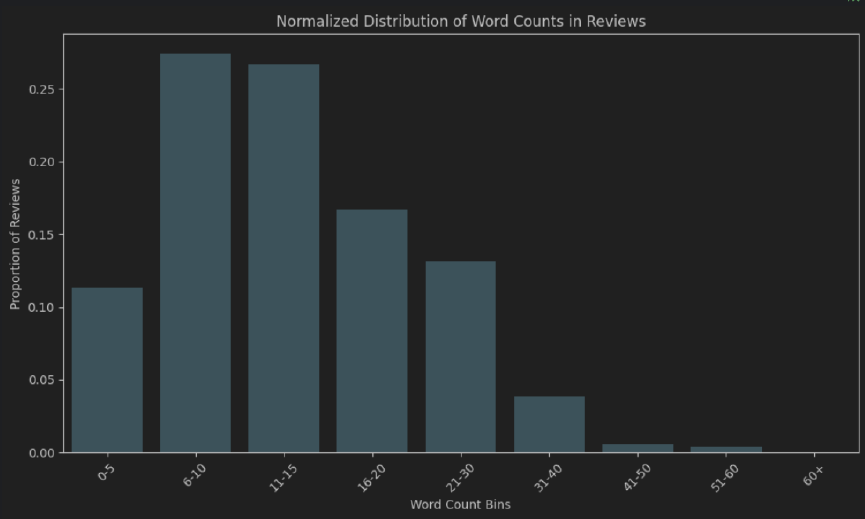
Entity + Opinion (Aspect) 실제 주석이 달린 레이블에 대한 평가와 함께 고객 서비스 검토에서 추출.
train.csvsample_review.csv 파일 (단일 주석 검토 포함)이 작성되었습니다. 이 모듈은 엔터티 (예 : '다소 맛있는')에 관한 검토 자의 의견과 함께 검토 된 엔티티 (예 : 'Food')를 추출하는 것과 관련이 있습니다.
이 모듈은 지상 진실 주석에 대한 엔티티-오피니언 튜플 추출의 평가와 관련이 있습니다.
EDA.ipynb 파일을 참조하십시오.py 모듈) main.py 모듈을 실행하십시오
참고 :
.env 파일을 작성하십시오.OPENAI_API_KEY = "your_openai_api_key"Lexicosyntactic에서 Semantics-Pragmatics 인터페이스 접근법으로 이동합니다
다음에 중점을 두었습니다.
코사인 유사성을 사용하여 시맨틱 텍스트 유사성을 측정하기위한 Bert 문장 변환기.
진정한 VS 예측 엔티티와 의견 (측면)의 다양한 언어 적 변형을 테스트 한 후 모델의 프로덕션에 대한 예측을 수용하기 위해 0.85의 임계 값이 설정되었습니다.
결과의 유효성을 강화하기 위해 정교한 접근 방식 (문장 변환 자와 같은)을 전통적인 규칙 기반 접근 방식과 결합합니다.
예를 들어, 구문 의존성 구문 분석과 결합 된 변압기 기반 솔루션, POS 및 NER (언어 기능)은“식당”과“식당”이 위의“맛있는”및“다소 맛있는”예제와 반대되는 것과 동일하게 (결정자와 함께) 동일하게 간주되는지 확인하는 데 도움이 될 수 있습니다.
보다 전통적인 분류 메트릭 (리콜, 정밀, F1- 점수, 정확도) 은이 경우 관련성이 떨어집니다.
혼란 매트릭스 구성 요소의 많은 부분은 전체 검토에서 한 단어/문구의 이진 분류 작업과 관련이 없습니다 (한 번 엔터티 인식 및 한 번). 이로 인해 이러한 메트릭 중 일부를 계산할 수 없습니다.
또한, 이러한 메트릭은 형용사/명사 수정 자 및 부사 강화제의 포함/제거에 의해 영향을받는 미세한 의미를 완전히 포착하지 못한다. 예를 들어, "맛있는"대 "다소 맛있는"것입니다.
또한, 이는 리콜, 정밀, F1 스코어 및 정확도를 사용할 때 이와 같은 부분 일치를 무시할 것인지에 대한 의문을 제기합니다.
그러나 기준을 설정하는 데 전통적인 N- 그램 기반 메트릭이 사용될 수 있다고 생각합니다.
더 철저한 테스트가 필요하지만, 비교적 엄격한 임계 값 (대부분 형용사/명사 수정 자 및 사상 복잡한 강제 자의 존재/부재를 고려해야하는)과 함께 Bert 문장 변환기 임베딩 사이의 의미 론적 텍스트 유사성을 측정하는 데 사용되는 코사인 유사성 접근법은 생산 환경에서 작동 할 수 있습니다.
대기 시간, 계산 시간, 서버에서 무거운 모델 호스팅 및 추가 비용과 같은 생산 환경에 대한 추가 고려 사항도 있습니다.


