entity_aspect_analysis
1.0.0
Entity + Opinion (Aspekt) Extraktion aus Kundendienstüberprüfungen sowie eine Bewertung gegen echte kommentierte Etiketten.
train.csvsample_review.csv Datei (mit einer einzigen kommentierten Überprüfung enthält) wurde für einen POC-Vergleich von true-vs-geprezierten Labels erstellt. Dieses Modul befasst sich mit der Extraktion des Unternehmens (z. B. "Food") zusammen mit der Meinung des Rezensenten über die Entität (z. B. "etwas lecker").
Dieses Modul befasst sich mit der Bewertung der Entitäts-Opinion-Tupel-Extraktion gegen die Annotationen der Grundwahrheit.
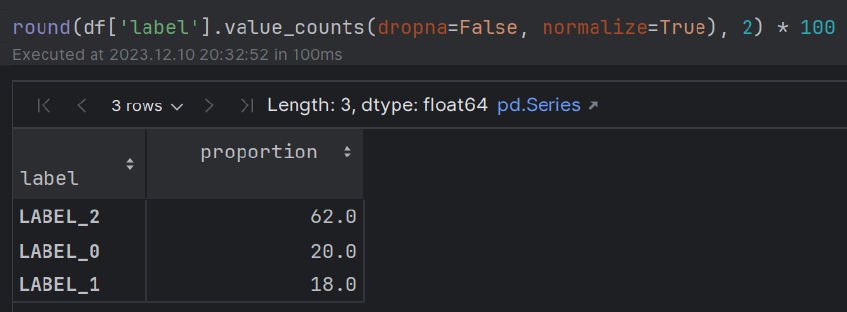
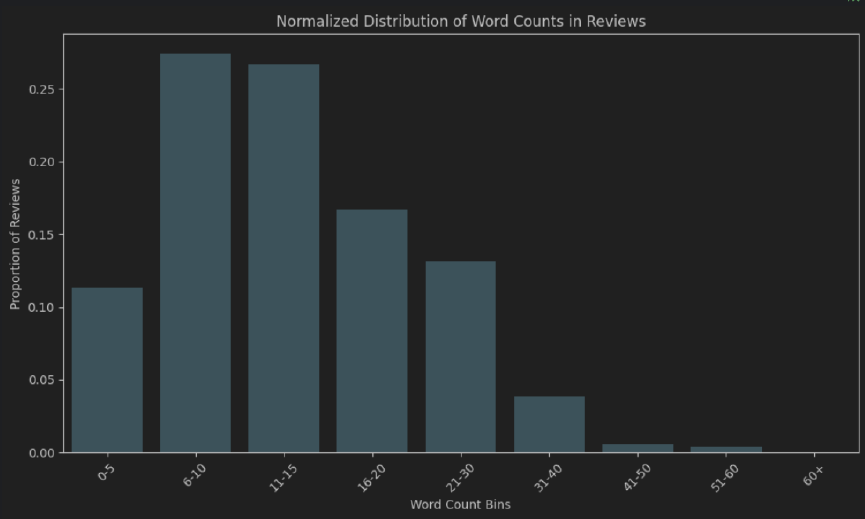
EDA.ipynb -Datei.py -Module) Führen Sie das main.py -Modul aus
Anmerkungen:
.env -Datei zum Speichern Ihres OpenAI -API -Schlüssels erstellen.OPENAI_API_KEY = "your_openai_api_key"Übergang von Lexikosyntaktisch zu einem Semantics-Pragmatics-Schnittstellenansatz
Der Schwerpunkt wurde auf Folgendes gelegt:
Bert-Satztransformer zur Messung der semantischen textuellen Ähnlichkeit mithilfe der Kosinusähnlichkeit.
Nach dem Testen verschiedener sprachlicher Variationen von echten VS-vorgesehenen Unternehmen und Meinungen (Aspekten) wurde ein Schwellenwert von 0,85 für die Annahme der Vorhersage des Modells in die Produktion eingestellt.
Kombinieren Sie ausgefeilte Ansätze (wie Satztransformer) mit traditionellen, regelbasierten Ansätzen, um die Gültigkeit der Ergebnisse zu stärken.
Zum Beispiel könnten transformatorbasierte Lösungen in Kombination mit syntaktischer Abhängigkeitsanalyse, POS und NER (Sprachfunktionen) dazu beitragen, sicherzustellen, dass „Restaurant“ und „das Restaurant“ als das gleiche (mit/aus dem Bestimmer) im Gegensatz zu „The Lasty“ und „etwas leckeres“ Beispiel von oben angesehen werden.
In diesem Fall sind traditionellere Klassifizierungsmetriken (Rückruf, Präzision, F1-Score, Genauigkeit) weniger relevant.
Viele der Verwirrungsmatrixkomponenten sind in einer binären Klassifizierungsaufgabe von nur einem Wort/einer Phrase aus einer ganzen Übersicht irrelevant (einmal zur Erkennung von Entität und einmal für Aspekt). Dies macht es unmöglich, einige dieser Metriken zu berechnen.
Darüber hinaus können diese Metriken die winzige Semantik nicht vollständig erfassen, die durch die Einbeziehung/Entfernung von Adjektiv-/Substantivmodifikatoren und Adverbialstärkern beeinflusst wird. Nehmen Sie zum Beispiel „lecker“ gegen „etwas lecker“.
Darüber hinaus wirft die Frage auf, ob dies bei der Verwendung von Abrechnung, Präzision, F1-Score und Genauigkeit zu berücksichtigen ist, als wenn sie diese ignorieren.
Ich glaube jedoch, dass traditionelle Kennzahlen auf N-Grammbasis für die Einrichtung einer Grundlinie eingesetzt werden könnten:
Obwohl es eine gründlichere Prüfung erfordert, wird der Ansatz der Cosinus-Ähnlichkeit zur Messung der semantischen textuellen Ähnlichkeit zwischen Bert-Satztransformern zusammen mit einem relativ strengen Schwellenwert (die das Vorhandensein/Fehlen von Adjektiv-/Substantivmodifikatoren und Adverbialstärkern berücksichtigen) und könnte in einer Produktionsumgebung berücksichtigt werden.
Es gibt auch zusätzliche Überlegungen zu einer Produktionsumgebung, wie Latenz, Berechnungszeit, hohe Modelle auf Servern und zusätzliche Kosten.


