entity_aspect_analysis
1.0.0
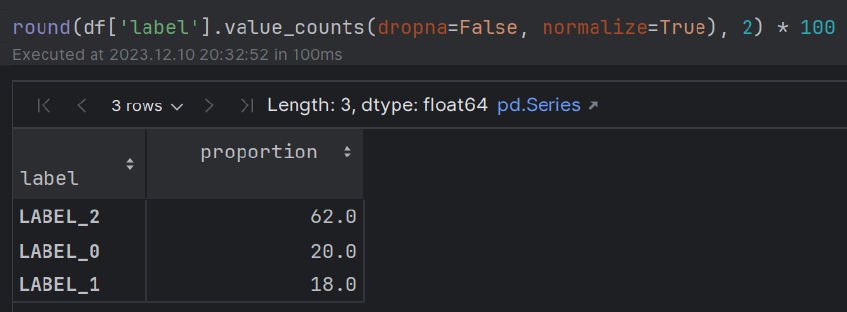
Entité + Opinion (aspect) Extraction des avis sur le service client ainsi qu'une évaluation contre de véritables étiquettes annotées.
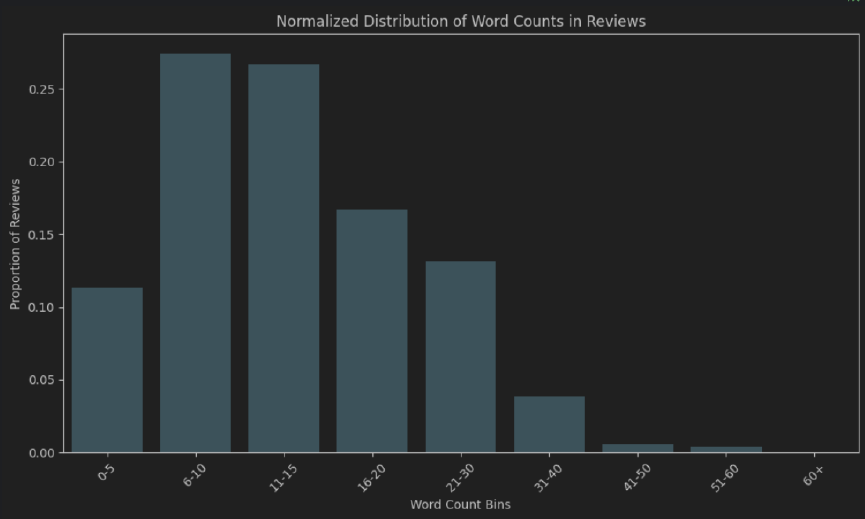
train.csvsample_review.csv (contenant une seule revue annotée) a été créé pour une comparaison POC des étiquettes True-VS-Pred. Ce module concerne l'extraction de l'entité en cours d'examen (par exemple, «nourriture») parallèlement à l'opinion du réviseur concernant l'entité (par exemple, «quelque peu savoureuse»).
Ce module s'intéresse à l'évaluation de l'extraction de tuple entité-opinion contre les annotations de vérité au sol.
EDA.ipynb.py Modules) Exécutez le module main.py
Notes:
.env pour stocker votre clé API OpenAI.OPENAI_API_KEY = "your_openai_api_key"Passer du lexosyntactique à une approche d'interface sémantique-pragmatique
L'accent a été mis sur ce qui suit:
Transformateurs de phrases Bert pour mesurer la similitude textuelle sémantique en utilisant la similitude du cosinus.
Après avoir testé diverses variations linguistiques des entités et des opinions prédites à VRS (aspects), un seuil de 0,85 a été défini pour accepter la prédiction du modèle dans la production.
Combiner des approches sophistiquées (comme les transformateurs de phrases) avec des approches traditionnelles basées sur des règles afin de renforcer la validité des résultats.
Par exemple, des solutions basées sur les transformateurs combinées à l'analyse de dépendance syntaxique, POS et NER (caractéristiques linguistiques) pourraient aider à s'assurer que le «restaurant» et «le restaurant» sont considérés comme les mêmes (avec / out le déterminant) par opposition à l'exemple «savoureux» et «quelque peu savoureux» d'en haut.
Des mesures de classification plus traditionnelles (rappel, précision, score F1, précision) sont moins pertinentes dans ce cas.
De nombreux composants de la matrice de confusion ne sont pas pertinents dans une tâche de classification binaire d'un seul mot / phrase par rapport à une revue entière (une fois pour la reconnaissance de l'entité et une fois pour l'aspect). Cela rend impossible de calculer certaines de ces mesures.
De plus, ces mesures ne parviennent pas à capturer pleinement la sémantique minutieuse influencée par l'inclusion / l'élimination des modificateurs adjectivaux / noms et des intensificateurs adverbiaux. Prenez par exemple, «savoureux» vs «quelque peu savoureux».
De plus, cela soulève la question de savoir s'il faut prendre en compte par rapport aux matchs partiels tels que ceux-ci lors de l'utilisation du rappel, de la précision, du score F1 et de la précision.
Je crois cependant que des mesures traditionnelles basées sur le N-Gram pourraient être utilisées pour établir une base de référence:
Bien qu'il nécessite des tests plus approfondis, l'approche de similitude en cosinus était utilisée pour mesurer la similitude textuelle sémantique entre les intérêts de phrase Bert intégrés aux côtés d'un seuil relativement strict (qui devrait surtout prendre en compte la présence / absence de modificateurs d'adjectival / nom et d'intensificateurs adverbiaux), pourrait fonctionner dans un environnement de production.
Il existe également des considérations supplémentaires dans un environnement de production, telles que la latence, le temps de calcul, l'hébergement de modèles lourds sur les serveurs et les coûts supplémentaires.


