نظرة عامة على المشروع
الكيان + الرأي (الجانب) استخراج من مراجعات خدمة العملاء جنبا إلى جنب مع التقييم ضد الملصقات المشروحة الحقيقية.
مجموعة البيانات:
- الوصف: مراجعات مطعم خدمة العملاء
- الاسم:
train.csv - المحتوى: يحتوي ملف CSV على عمودين (مراجعة ، ملصق رأي/رأي/جانب)
- ملاحظة: تم تحليل المراجعات الخام فقط. تم تجاهل ملصق المشاعر/الرأي لأن الغرض من الكود هو إيجاد طرق محسنة لاستخراجها.
- ملاحظة: تم استخدام هذا الملف فقط لأغراض EDA.
تسميات حقيقية
- لم تخضع مجموعة البيانات إلى شرح إنساني لتوليد علامات حقيقية.
- تم إنشاء ملف
sample_review.csv (يحتوي على مراجعة مشروحة واحدة) لمقارنة POC من الملصقات الحقيقية لـ VS.
أجزاء المشروع:
الجزء الأول - EDA
الجزء الثاني - الرأي الكيان استخراج tuple
تهتم هذه الوحدة باستخراج الكيان الذي يتم مراجعته (على سبيل المثال ، "الغذاء") إلى جانب رأي المراجع فيما يتعلق بالكيان (على سبيل المثال ، "لذيذ إلى حد ما").
الجزء الثالث - التقييم
تهتم هذه الوحدة بتقييم استخراج Tuple-Opinion الكيان ضد التعليقات التوضيحية للحقيقة الأرضية.
EDA: الرؤى الأولية والعامة
- NUM من المراجعة: 1121
- المشاعر: ~ 60 ٪ (POS) ؛ ~ 20 ٪ (محايد) ؛ ~ 20 ٪ (neg) يظهر معظم الناس مشاعر إيجابية فيما يتعلق بتجربة تناول الطعام.
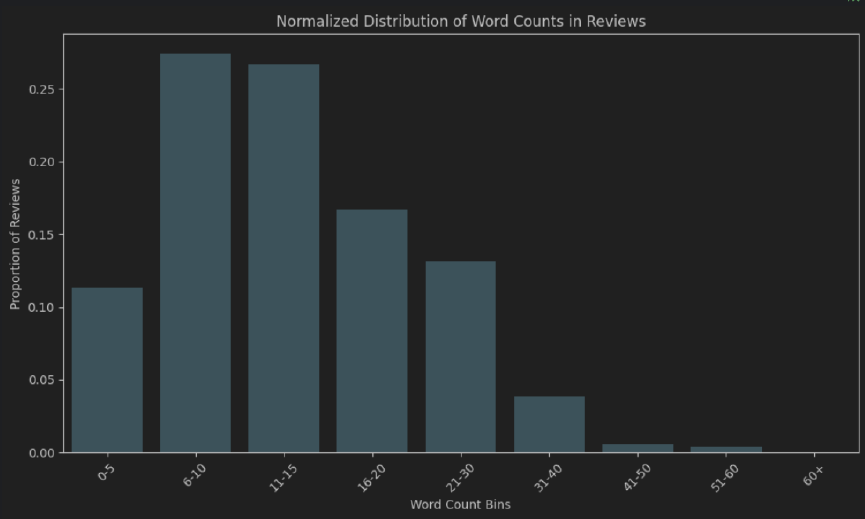
- طول الكلمة: تقريبا. 50 ٪ من المراجعات هي 6-15 الرموز الطويلة. معظم الناس لا يأخذون الوقت الكافي لكتابة مراجعة "شاملة للغاية".
- Eda Eda - تقنيات NLP إضافية يمكن استخدامها لاكتساب رؤى: نموذج أسئلة وأجوبة ، WordCloud ، عدد الترددات n -gram (بعد إزالة الكلمات المتوقفة) ، المطابقة الغامضة ، المطابقة الدقيقة/الجزئية (كلمات التوقف ، والموجودات المورفولوجية ، والمعدنة ، والمشتركة ، والمشتركة ، والرسائل ، والرسائل ، والرسائل ، والرسائل ، والرسائل ، والرسالة ، والرسالة ، والرسالة ، والرسالة ، والرسالة ، والرسالة ، والرسالة المرسلة ، الطعام/المشروبات ، التمييز في أنواع الوجبات (الإفطار ، الغداء ، العشاء) ، التمييز الثنائي القائم على نقاط البيع للرموز (الصفات مقابل الراحة) ، تحليل المكثف الظرفي ، تحليل التبعية النحوية ، توزيع الترقيم (الأنواع ، ثنائي ، الجمع بين المشاعر).
شفرة
- EDA - انظر ملف
EDA.ipynb - استخراج الرأي الكيان + eval-pred-pred true-vs. - المشروع (وحدات
.py )
تعليمات
قم بتشغيل وحدة main.py
ملحوظات:
- تأكد من إنشاء ملف
.env لتخزين مفتاح API Openai. - استخدم التنسيق التالي:
OPENAI_API_KEY = "your_openai_api_key"
التنفيذ والبدائل:
eda
النهج التبسيطية (سريعة ، توفر مجرد عرض ماكرو أولي للبيانات)
- توزيع عدد الكلمات (المطلق والطبيع) لقياس المدة الإجمالية للمراجعات.
- كلمة سحابة
فهم أكثر تعمقا
الانتقال من المعاقين إلى نهج واجهة الدلالات-البراخيات
- نمذجة الموضوع مع bertopic
استخراج الكيان-أوبنيون
- تقتصر نماذج NER على مجموعة من الكيانات المدربة التي لا تعكس الطيف الكامل للكيانات الممكنة في جميع المجالات (على سبيل المثال ، مراجعات المطاعم). أنها تتطلب عملية شاقة من التعليقات التوضيحية والمراجعة والتدريب.
- يتم تدريب طرز أسئلة وأجوبة في الغالب على مجموعة محددة من الأسئلة ومجموعات البيانات ويمكن أن يكون لها أخطاء من النوع الأول والثاني أكثر من LLMs.
الهندسة الفورية
تم التركيز على ما يلي:
- سرير سرير (سلسلة من الفكر)
- تعلم القليل من اللقطة
- النظام/المستخدم/مساعد التمييز دور
- طمأنة النموذج
نهج التقييم: استخراج LLM ضد تعليقات الحقيقة الأرضية
محولات جملة بيرت لقياس التشابه النصي الدلالي باستخدام تشابه جيب التمام.
بعد اختبار مختلف الاختلافات اللغوية في الكيانات والآراء التي تم تنشيطها الحقيقي (الجوانب) ، تم تعيين عتبة 0.85 لقبول تنبؤ النموذج في الإنتاج.
بدائل التقييم
محولات الجملة إلى جانب الحلول القائمة على القواعد
الجمع بين الأساليب المتطورة (مثل محولات الجملة) مع الأساليب التقليدية القائمة على القواعد من أجل تعزيز صحة النتائج.
على سبيل المثال ، يمكن أن تساعد الحلول المستندة إلى المحولات إلى جانب تحليل التبعية النحوية ، و POS و NER (الميزات اللغوية) في التأكد من أن "المطعم" و "المطعم" يعتبران نفس مثال "لذيذ" و "لذيذ إلى حد ما" من الأعلى.
مقاييس التصنيف التقليدية (الاستدعاء ، الدقة ، درجة F1 ، الدقة)
تعد مقاييس التصنيف التقليدية (استدعاء ، دقة ، درجة F1 ، الدقة) أقل أهمية في هذه الحالة.
العديد من مكونات مصفوفة الارتباك غير ذات صلة في مهمة تصنيف ثنائية تتمثل في كلمة/عبارة واحدة فقط من مراجعة كاملة (مرة واحدة للتعرف على الكيان ومرة واحدة للجوانب). هذا يجعل من المستحيل حساب بعض هذه المقاييس.
بالإضافة إلى ذلك ، تفشل هذه المقاييس في التقاط دلالات دقيقة بالكامل تتأثر بإدراج/إزالة المعدلات/الاسم والتكثيف الضيقة. خذ على سبيل المثال ، "لذيذ" مقابل "لذيذ إلى حد ما".
علاوة على ذلك ، يثير هذا مسألة ما إذا كان يجب مراعاة المباريات الجزئية مقابل تجاهل مثل هذه المباريات الجزئية عند استخدام الاستدعاء والدقة ونتيجة F1 ودقة.
مقاييس N-Gram التقليدية (التشابه المعجم)
ومع ذلك ، أعتقد أن المقاييس التقليدية القائمة على N-Gram يمكن استخدامها لإنشاء خط أساس:
- بلو (تركز على الدقة)
- روج (يركز على الاستدعاء)
- النيزك (يحسب الوسط التوافقي للدقة والاستدعاء جنبا إلى جنب مع العقوبات على ترتيب الكلمات واختلافات العبارات)
حلول الحل في الإنتاج
على الرغم من أنه يتطلب اختبارًا أكثر شمولاً ، إلا أن نهج تشابه جيب التمام المستخدم لقياس التشابه النصي الدلالي بين محولات جملة Bert-Transformers إلى جانب عتبة صارمة نسبيًا (يجب أن تأخذ في الغالب أن تأخذ في الاعتبار وجود/عدم وجود معدلات الصفة/الاسم وتكثيف الضيقة) ، في بيئة إنتاجية.
هناك أيضًا اعتبارات إضافية لبيئة الإنتاج ، مثل الكمون ، ووقت الحساب ، واستضافة نماذج ثقيلة على الخوادم ، وتكاليف إضافية.


