entity_aspect_analysis
1.0.0
Ekstraksi entitas + opini (aspek) dari ulasan layanan pelanggan di samping evaluasi terhadap label beranotasi sejati.
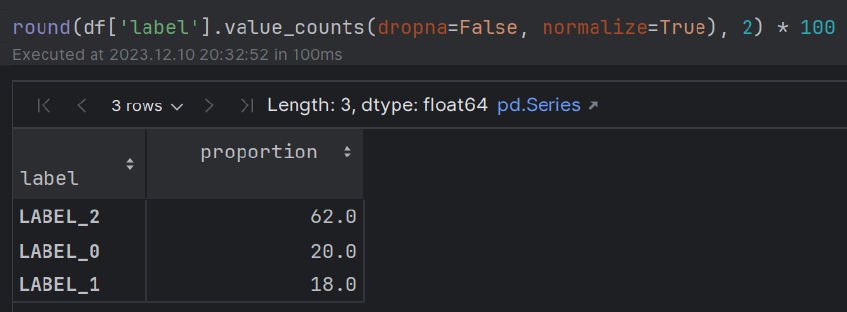
train.csvsample_review.csv (berisi ulasan beranotasi tunggal) dibuat untuk perbandingan POC label True-VS-Pred. Modul ini berkaitan dengan mengekstraksi entitas yang ditinjau (misalnya, 'makanan') bersama pendapat pengulas tentang entitas (misalnya, 'agak lezat').
Modul ini berkaitan dengan evaluasi ekstraksi tuple entitas-opinion terhadap anotasi kebenaran dasar.
EDA.ipynb.py ) Jalankan Modul main.py
Catatan:
.env untuk menyimpan kunci API openai Anda.OPENAI_API_KEY = "your_openai_api_key"Pindah dari leksikosintaksis ke pendekatan antarmuka semantik-pragmatik
Penekanan ditempatkan pada yang berikut:
Bert kalimat-transformer untuk mengukur kesamaan tekstual semantik menggunakan kesamaan cosinus.
Setelah menguji berbagai variasi linguistik dari entitas dan opini (aspek) yang diprediksi-VS, ambang batas 0,85 ditetapkan untuk menerima prediksi model dalam produksi.
Menggabungkan pendekatan canggih (seperti kalimat kalimat) dengan pendekatan tradisional berbasis aturan untuk memperkuat validitas hasil.
Sebagai contoh, solusi berbasis transformator yang dikombinasikan dengan penguraian ketergantungan sintaksis, POS dan NER (fitur linguistik) dapat membantu memastikan bahwa "restoran" dan "restoran" dianggap sama (tanpa/keluar dari penentu) sebagai lawan dari contoh "The Tasty" dan "SyMathat Tasty" dari atas.
Metrik klasifikasi yang lebih tradisional (recall, precision, f1-score, akurasi) kurang relevan dalam kasus ini.
Banyak komponen matriks kebingungan tidak relevan dalam tugas klasifikasi biner hanya satu kata/frasa dari seluruh ulasan (sekali untuk pengakuan entitas dan sekali untuk aspek). Ini membuat tidak mungkin untuk menghitung beberapa metrik ini.
Selain itu, metrik ini gagal untuk sepenuhnya menangkap semantik menit yang dipengaruhi oleh inklusi/penghapusan pengubah kata sifat/kata benda dan intensifier adverbial. Ambil contoh, "lezat" vs "agak lezat".
Selain itu, ini menimbulkan pertanyaan apakah akan memperhitungkan vs mengabaikan kecocokan parsial seperti ini saat menggunakan penarikan, presisi, skor F1, dan akurasi.
Saya percaya, bagaimanapun, bahwa metrik berbasis N-gram tradisional dapat digunakan untuk membangun garis dasar:
Meskipun memang membutuhkan pengujian yang lebih menyeluruh, pendekatan kesamaan cosinus yang digunakan untuk mengukur kesamaan tekstual semantik antara embedding transformer kalimat Bert di samping ambang batas yang relatif ketat (yang sebagian besar harus mempertimbangkan ada/tidak adanya pengubah kata sifat/kata benda dan penasihat intensifier), dapat bekerja di lingkungan produksi.
Ada juga pertimbangan tambahan untuk lingkungan produksi, seperti latensi, waktu perhitungan, hosting model berat pada server, dan biaya tambahan.


