Descripción general del proyecto
Entity + Opinión (aspecto) Extracción de las revisiones de servicio al cliente junto con una evaluación contra las verdaderas etiquetas anotadas.
Conjunto de datos:
- Descripción: Revisiones de restaurantes de servicio al cliente de Yelp
- Nombre:
train.csv - Contenido: el archivo CSV contiene dos columnas (revisión, etiqueta de sentimiento/opinión/aspecto)
- Nota: Solo se analizaron las revisiones sin procesar. La etiqueta de sentimiento/opinión se ignoró como el propósito del código era encontrar formas mejoradas de extraerla.
- Nota: Este archivo se usó solo para fines EDA.
Verdaderas etiquetas
- El conjunto de datos no se sometió a una anotación humana para generar etiquetas verdaderas.
- Se creó un archivo
sample_review.csv (que contiene una sola revisión anotada) para una comparación POC de las etiquetas True-VS-Pred.
Partes del proyecto:
Parte I - EDA
Parte II - Entidad Opinión de extracción de tupla
Este módulo se refiere a extraer la entidad que se está revisando (por ejemplo, 'alimento') junto con la opinión del revisor sobre la entidad (por ejemplo, 'algo sabrosa').
Parte III - Evaluación
Este módulo se refiere a la evaluación de la extracción de la tupla de la entidad-opinión contra las anotaciones de la verdad del suelo.
EDA: ideas iniciales y generales
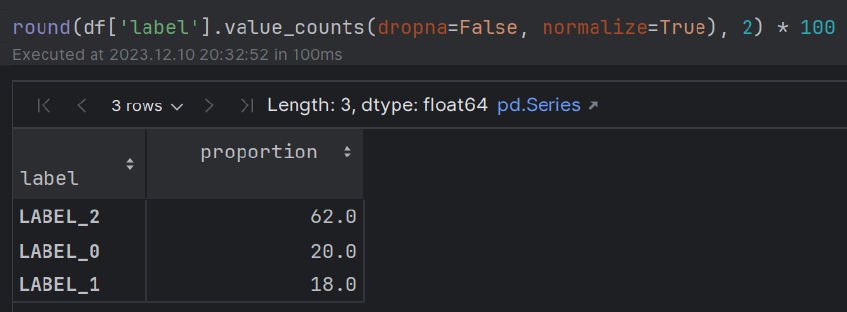
- Número de revisión: 1121
- Sentimiento: ~ 60% (pos); ~ 20% (neutral); ~ 20% (neg) La mayoría de las personas muestran emociones positivas con respecto a su experiencia gastronómica.
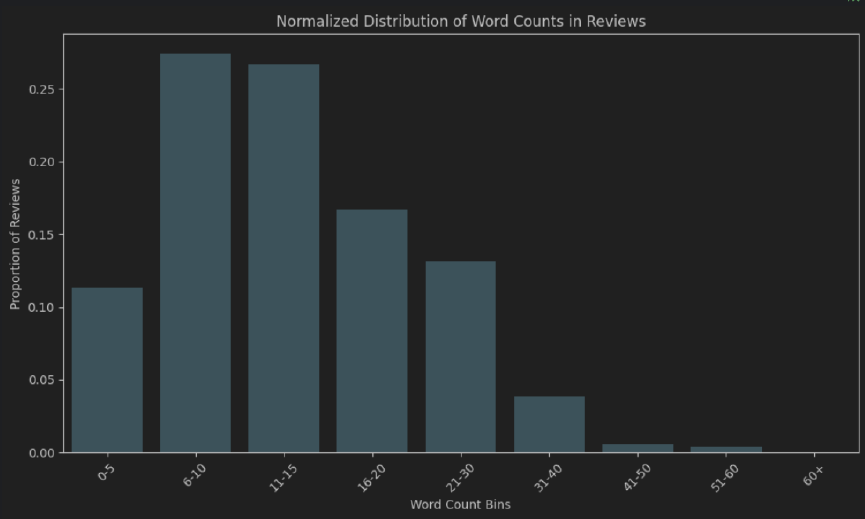
- Longitud de la palabra: aprox. El 50% de las revisiones tienen 6-15 tokens de largo. La mayoría de las personas no se toman el tiempo para escribir una revisión "muy exhaustiva".
- Extended EDA - Additional NLP techniques that can be used for gaining insights: Q&A model, WordCloud, N-gram frequency count (after stopwords removal), fuzzy matching, exact/partial matching (stopwords, morphological prefixes and suffixes), clustering algorithms (lexicosyntactic, semantic), sentiment, polarity, aspect and sentiment combined, NER, distinction En alimentos/bebidas, distinción en tipos de comidas (desayuno, almuerzo, cena), distinción binaria de tokens (adjetivos versus reposo), análisis de intensificadores adverbiales, análisis de dependencia sintáctica, distribución de puntuaciones (tipos, binarios, combinación con sentimiento).
Código
- EDA - Ver archivo
EDA.ipynb - Extracción de opinión de la entidad + Eval True-VS-Pred. - Proyecto (módulos
.py )
Instrucciones
Ejecute el módulo main.py
Notas:
- Asegúrese de crear un archivo
.env para almacenar su tecla API OpenAI. - Use el siguiente formato:
OPENAI_API_KEY = "your_openai_api_key"
Implementación y alternativas:
EDA
Enfoques simplistas (rápido, proporcionan simplemente una vista macro inicial de los datos)
- Distribución del recuento de palabras (tanto absoluto como normalizado) para medir la duración total de las revisiones.
- Nube de palabras
Una comprensión más profunda
Pasando de lexicosyntactic a un enfoque de interfaz semántica-pracmática
- Modelado de temas con Bertópica
Extracción de entidad-opinion
- Los modelos NER se limitan a un conjunto de entidades capacitadas que no reflejan el espectro completo de posibles entidades en todos los dominios (por ejemplo, reseñas de restaurantes). Requieren un tedioso proceso de anotaciones, revisión y capacitación.
- Los modelos de preguntas y respuestas se capacitan principalmente en un conjunto específico de preguntas y conjuntos de datos y pueden tener más errores tipo I y II que LLM.
Ingeniería rápida
Se puso énfasis en lo siguiente:
- Cot (cadena de pensamiento)
- Aprendizaje de pocos disparos
- Sistema/Usuario/Asistente Distinción de roles
- Tranquilizando al modelo
Enfoque de evaluación: extracción de LLM contra anotaciones de verdad terrestre
Bert-transformadores de oraciones para medir la similitud textual semántica utilizando similitud de coseno.
Después de probar varias variaciones lingüísticas de las entidades y opiniones (aspectos) predictos verdaderos, se estableció un umbral de 0.85 para aceptar la predicción del modelo en la producción.
Alternativas de evaluación
Transformadores de oraciones junto con soluciones basadas en reglas
Combinando enfoques sofisticados (como transformadores de oraciones) con enfoques tradicionales basados en reglas para fortalecer la validez de los resultados.
Por ejemplo, las soluciones basadas en transformadores combinadas con el análisis de dependencia sintáctica, POS y NER (características lingüísticas) podrían ayudar a asegurarse de que el "restaurante" y el "restaurante" se consideren los mismos (con/fuera del determinante) en lugar de "lo sabroso" y "algo sabroso" de arriba de arriba.
Métricas de clasificación tradicionales (recuerdo, precisión, puntaje F1, precisión)
Las métricas de clasificación más tradicionales (retiro, precisión, puntaje F1, precisión) son menos relevantes en este caso.
Muchos de los componentes de la matriz de confusión son irrelevantes en una tarea de clasificación binaria de una sola palabra/frase de una revisión completa (una vez para el reconocimiento de entidades y una vez para el aspecto). Esto hace imposible calcular algunas de estas métricas.
Además, estas métricas no logran capturar completamente la semántica minuciosa influenciada por la inclusión/eliminación de modificadores adjetivos/sustantivos e intensificadores adverbiales. Tomemos, por ejemplo, "sabroso" frente a "algo sabroso".
Además, esto plantea la cuestión de si se debe tener en cuenta vs ignorar coincidencias parciales como estas cuando se usa recuerdo, precisión, puntaje F1 y precisión.
Métricas tradicionales basadas en N-Gram (similitud lexicosisintáctica)
Sin embargo, creo que las métricas tradicionales basadas en N-gram podrían emplearse para establecer una línea de base:
- Bleu (centrado en la precisión)
- Rouge (centrado en el recuerdo)
- Meteor (calcula la media armónica de precisión y retira junto con las penalizaciones para el orden de las palabras y las diferencias de frases)
Viabilidad de la solución en la producción
Aunque requiere pruebas más exhaustivas, el enfoque de similitud de coseno utilizado para medir la similitud textual semántica entre los incrustaciones de transformadores de oraciones Bert junto con un umbral relativamente estricto (que debería tener en cuenta la presencia/ausencia de modificadores adjetivos/sustantivos e intensificadores adverbiales), podría trabajar en un entorno de producción.
También hay consideraciones adicionales para un entorno de producción, como latencia, tiempo de cálculo, alojamiento de modelos pesados en servidores y costos adicionales.


