VerAIzon
1.0.0
抹布(检索增强一代)聊天机器人伴随Mistral-7B,专门针对Verizon客户服务量身定制。
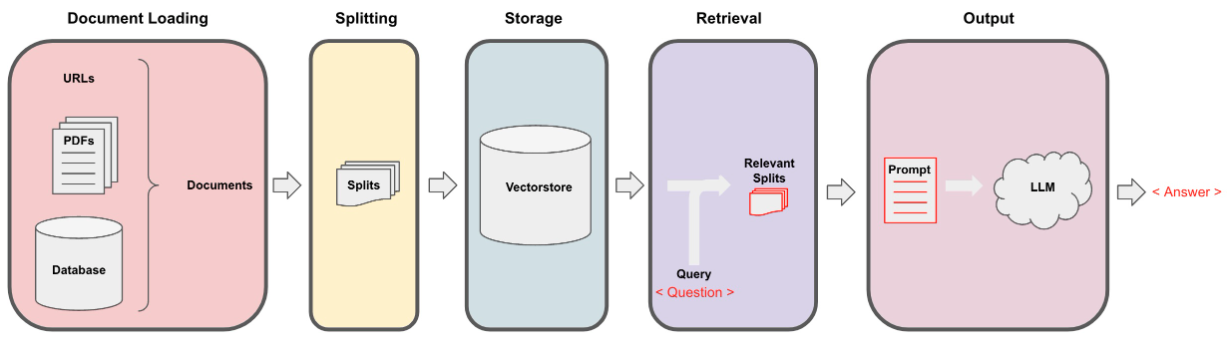
使用data_extraction.py文件通过迭代提取来收集数据。该代码仅以2个链接开头 - [https://www.verizon.com/home/internet/',https:/'https://community.verizon.com/'],然后在运行时,它删除了这两个网页中的所有链接,并在这两个网页中进行了所有链接,并创建了大约一个数据集的数据,大约是1000 pages的数据。另一个数据来源是https://www.verizon.com/about/terms-conditions/user-guides上可用的用户加油站。
LLMS无法处理整个数据,因此我们需要将数据分为一小部分文本。使用Langchain分裂的递归字符将数据集拆分为小块。一旦有了小块,我们就可以通过HuggingFace Embeddings使用All-Minilm-L12-V2模型来创建其嵌入。
一旦我们将嵌入与文本块相对应,我们就可以将其存储在矢量数据库中。出于我们的目的,我们使用了FAISS(Facebook AI相似性搜索)矢量店,因为在计算大量数据时相似性时,它是高效的。
对于检索部分,我们将用户问题作为输入,并使用FAISS搜索可能会回答用户查询的FAISS搜索中找到最匹配的块。
一旦我们拥有最匹配的块,我们就可以将它们标记为上下文,并将其传递到模型的自定义提示中。出于目的,我们使用了以下提示 -
[ INST ] You are a Verizon company 's chatbot, Only use the following pieces of context to answer the user' s question . If the answer is not present in context , just say that you don 't know and display the following link "https://www.verizon.com/support/residential/contact-us/contactuslanding.htm", don' t try to make up an answer .[ / INST ]
Context : { context }
Question : { question }
answer : 现在,此提示将传递给LLM以获取输出。我们使用的LLM是Mistral-7b(当前的开源状态)。


