VerAIzon
1.0.0
Rag (검색 증강 세대) 챗봇은 Mistral-7B와 함께 Verizon 고객 서비스에 맞게 조정되었습니다.
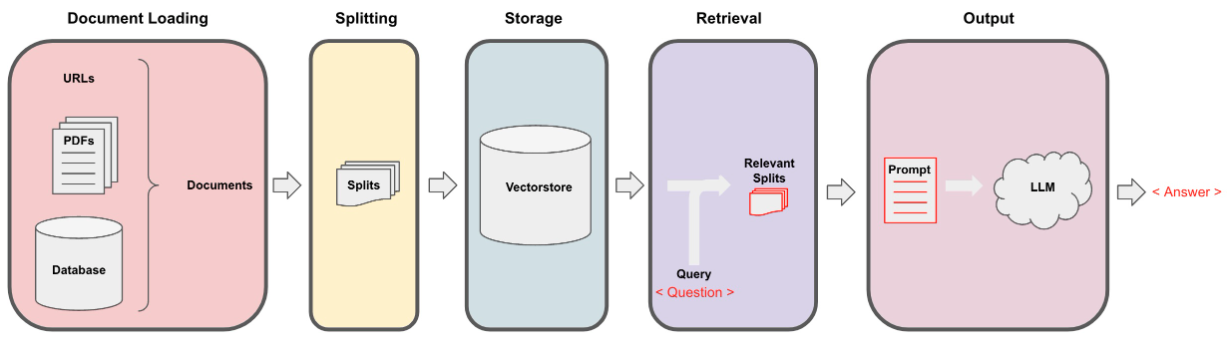
Data_Extraction.py 파일을 사용하여 반복 추출을 통해 데이터를 수집했습니다. 이 코드는 2 개의 링크로 시작합니다. 또 다른 데이터 소스는 https://www.verizon.com/about/terms-conditions/user-guides에서 사용할 수있는 사용자 guides입니다.
LLM은 전체 데이터를 처리 할 수 없으므로 데이터를 작은 부분의 텍스트로 분할해야합니다. 데이터 세트는 Langchain으로부터 분할 된 재귀 문자를 사용하여 작은 덩어리로 분할되었습니다. 작은 덩어리가 있으면 포옹 페이스 임베딩을 통해 All-Minilm-L12-V2 모델을 사용하여 임베딩을 만들 수 있습니다.
텍스트 청크에 해당하는 임베딩이 있으면 벡터 데이터베이스에 저장할 수 있습니다. 우리의 목적을 위해, 우리는 엄청난 양의 데이터에 비해 유사성을 계산할 때 매우 효율적인 Faiss (Facebook AI 유사성 검색) VectorStore를 사용했습니다.
검색 부분의 경우 사용자 질문을 입력으로 취하고 사용자 쿼리에 응답 할 수있는 FAISS 검색을 사용하여 VectorStore에 저장된 가장 일치하는 덩어리를 찾습니다.
우리가 가장 일치하는 덩어리가 있고 일단 덩어리를 컨텍스트로 표시하고 모델의 사용자 정의 프롬프트에 전달할 수 있습니다. 목적을 위해 다음 프롬프트를 사용했습니다.
[ INST ] You are a Verizon company 's chatbot, Only use the following pieces of context to answer the user' s question . If the answer is not present in context , just say that you don 't know and display the following link "https://www.verizon.com/support/residential/contact-us/contactuslanding.htm", don' t try to make up an answer .[ / INST ]
Context : { context }
Question : { question }
answer : 이제이 프롬프트가 출력을 얻기 위해 LLM으로 전달됩니다. 우리가 사용한 LLM은 Mistral-7B (현재 오픈 소스 최신 ART)입니다.


