VerAIzon
1.0.0
RAG (الجيل المعزز للاسترجاع) chatbot مصحوبة بـ MISTRAL-7B ، مصممة خصيصًا لخدمات عملاء Verizon.
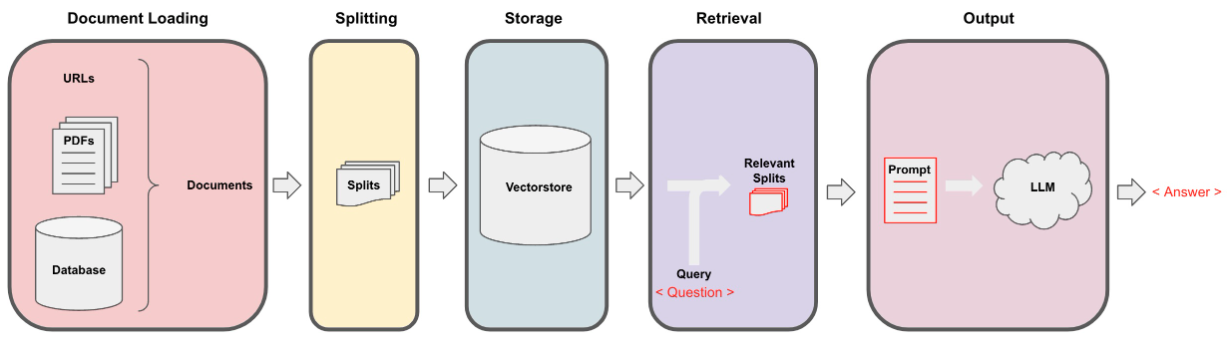
تم جمع البيانات من خلال الاستخراج التكراري باستخدام ملف data_extraction.py. يبدأ الرمز بشكل ارتباط مع رابطين فقط-['https://www.verizon.com/home/internet/''https://community.verizon.com/'] ثم في وقت التشغيل ، تدوم جميع الروابط في هاتين الرقصتين على الويب ، وتستمر هذه العملية ، مما يقيم حوالي 1000 صفحات. مصدر آخر للبيانات هو دليل المستخدم المتاح على https://www.verizon.com/about/terms-conditions/user-guides.
لا يمكن لـ LLMs معالجة البيانات بأكملها ، وبالتالي نحتاج إلى تقسيم البيانات إلى أجزاء صغيرة من النصوص. تم تقسيم مجموعة البيانات إلى قطع صغيرة باستخدام الحرف العودية المقسمة من Langchain. بمجرد أن يكون لدينا قطع صغيرة ، يمكننا إنشاء تضميناتها باستخدام طراز All-Minilm-L12-V2 عبر تضمينات Huggingface.
بمجرد أن يكون لدينا التضمينات المقابلة للقطع النصية ، يمكننا تخزينها في قاعدة بيانات المتجهات. لغرضنا ، استخدمنا VectorStore Faiss (Facebook AI التشابه) لأنه فعال للغاية عند حساب التشابه على كمية هائلة من البيانات.
بالنسبة لجزء الاسترجاع ، نأخذ سؤال المستخدم كمدخلات والعثور على القطع الأكثر مطابقة المخزنة في VectorStore باستخدام بحث FAISS الذي يمكن أن يجيب على استعلام المستخدم.
بمجرد أن يكون لدينا أجزاءنا الأكثر تطابقًا ، يمكننا تصنيفها على أنها سياق ونقلها إلى المطالبة المخصصة لنموذجنا. لأغراض خارجية استخدمنا المطالبة التالية -
[ INST ] You are a Verizon company 's chatbot, Only use the following pieces of context to answer the user' s question . If the answer is not present in context , just say that you don 't know and display the following link "https://www.verizon.com/support/residential/contact-us/contactuslanding.htm", don' t try to make up an answer .[ / INST ]
Context : { context }
Question : { question }
answer : الآن يتم تمرير هذه المطالبة إلى LLM من أجل الحصول على الإخراج. LLM التي استخدمناها هي MISTRAL-7B (حالة مفتوحة المصدر الحالية).


