VerAIzon
1.0.0
RAG (Generation Augmented Retrieval) Chatbot พร้อมกับ Mistral-7B ซึ่งได้รับการปรับแต่งเฉพาะสำหรับการบริการลูกค้า Verizon
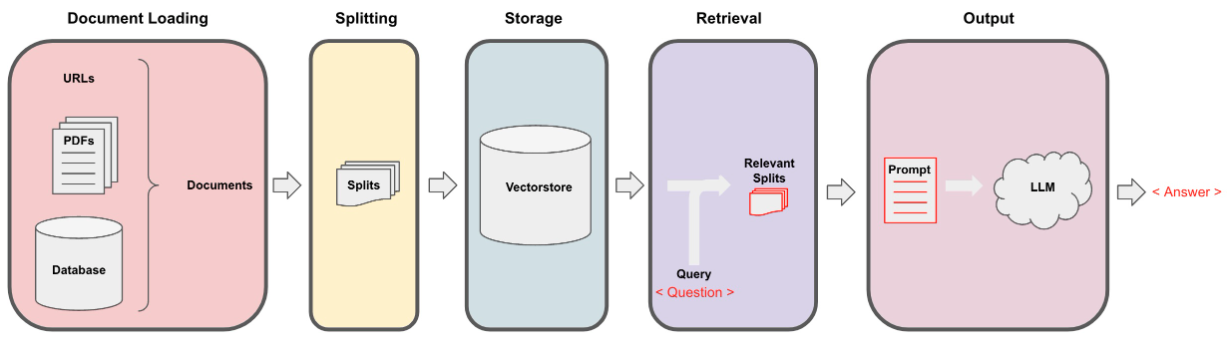
ข้อมูลถูกรวบรวมผ่านการสกัดซ้ำโดยใช้ไฟล์ data_extraction.py รหัสเริ่มต้นด้วยลิงก์เพียง 2 ลิงก์-['https://www.verizon.com/home/internet/'https://community.verizon.com/'] จากนั้นในเวลาที่ใช้งานได้ แหล่งข้อมูลอีกแหล่งหนึ่งคือคู่มือผู้ใช้ที่มีอยู่ที่ https://www.verizon.com/about/terms-conditions/user-guides
LLMS ไม่สามารถประมวลผลข้อมูลทั้งหมดและเราจำเป็นต้องแบ่งข้อมูลออกเป็นส่วนเล็ก ๆ ของข้อความ ชุดข้อมูลถูกแยกออกเป็นชิ้นเล็ก ๆ โดยใช้ตัวละครแบบเรียกซ้ำจาก Langchain เมื่อเรามีชิ้นเล็ก ๆ เราสามารถสร้าง embeddings ของมันโดยใช้โมเดลทั้งหมด Minilm-L12-V2 ผ่าน Embeddings HuggingFace
เมื่อเรามี embeddings ที่สอดคล้องกับชิ้นข้อความเราสามารถเก็บไว้ในฐานข้อมูลเวกเตอร์ เพื่อจุดประสงค์ของเราเราใช้ FAISS (การค้นหาความคล้ายคลึงกันของ Facebook AI) VectorStore เนื่องจากมีประสิทธิภาพสูงเมื่อคำนวณความคล้ายคลึงกันมากกว่าข้อมูลจำนวนมาก
สำหรับส่วนการดึงข้อมูลเราใช้คำถามผู้ใช้เป็นอินพุตและค้นหาชิ้นส่วนที่จับคู่มากที่สุดที่เก็บไว้ใน VectorStore โดยใช้การค้นหา FAISS ที่อาจตอบคำถามของผู้ใช้
เมื่อเรามีชิ้นส่วนที่ตรงกันที่สุดของเราเราสามารถติดฉลากเป็นบริบทและส่งผ่านไปยังพรอมต์ที่กำหนดเองสำหรับโมเดลของเรา เพื่อจุดประสงค์เราใช้พรอมต์ต่อไปนี้ -
[ INST ] You are a Verizon company 's chatbot, Only use the following pieces of context to answer the user' s question . If the answer is not present in context , just say that you don 't know and display the following link "https://www.verizon.com/support/residential/contact-us/contactuslanding.htm", don' t try to make up an answer .[ / INST ]
Context : { context }
Question : { question }
answer : ตอนนี้พรอมต์นี้จะถูกส่งผ่านไปยัง LLM เพื่อรับเอาต์พุต LLM ที่เราใช้คือ Mistral-7b (ปัจจุบันรัฐโอเพ่นซอร์สของศิลปะ)


