VerAIzon
1.0.0
RAG(検索拡張生成)チャットボットは、Verizonカスタマーサービスに合わせて特別に調整されたMistral-7Bを伴います。
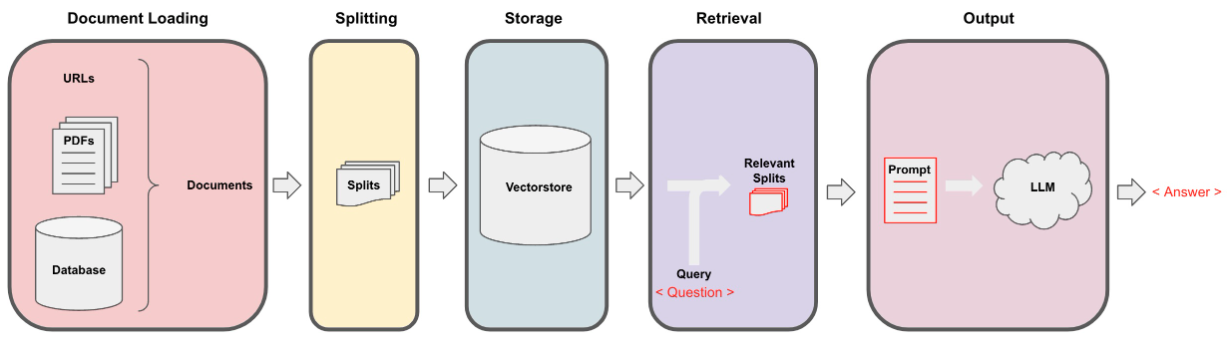
データは、data_extraction.pyファイルを使用して、反復抽出を介して収集されました。コードは、['https://www.verizon.com/home/internet/','https://community.verizon.com/']で2つのリンクから始まります。その後、これら2つのWebページのすべてのリンクを削ると、このプロセスが続き、1000ページのデータセットを作成します。データのもう1つのソースは、https://www.verizon.com/about/terms-conditions/user-guidesで入手できるユーザーガイドです。
LLMはデータ全体を処理できないため、データを小さなテキストの部分に分割する必要があります。 Langchainからの再帰的な文字分割を使用して、データセットを小さなチャンクに分割しました。小さなチャンクができたら、Huggingface Embeddingsを介してAll-Minilm-L12-V2モデルを使用して埋め込みを作成できます。
テキストチャンクに対応する埋め込みを取得したら、ベクトルデータベースに保存できます。私たちの目的のために、膨大な量のデータで類似性を計算するときに非常に効率的であるため、FAISS(Facebook AI類似性検索)VectorStoreを使用しました。
検索部品については、ユーザーの質問を入力として取得し、ユーザークエリに応答する可能性のあるFAISS検索を使用して、VectorStoreに保存されている最も一致するチャンクを見つけます。
最も一致するチャンクができたら、それらをコンテキストとしてラベル付けし、モデルのカスタムプロンプトに渡すことができます。目的のために、次のプロンプトを使用しました -
[ INST ] You are a Verizon company 's chatbot, Only use the following pieces of context to answer the user' s question . If the answer is not present in context , just say that you don 't know and display the following link "https://www.verizon.com/support/residential/contact-us/contactuslanding.htm", don' t try to make up an answer .[ / INST ]
Context : { context }
Question : { question }
answer : これで、このプロンプトは出力を取得するためにLLMに渡されます。私たちが使用したLLMは、Mistral-7B(現在のオープンソースの最先端)です。


