VerAIzon
1.0.0
RAG (geração aumentada de recuperação) Chatbot acompanhada com Mistral-7b, especificamente adaptada aos serviços ao cliente da Verizon.
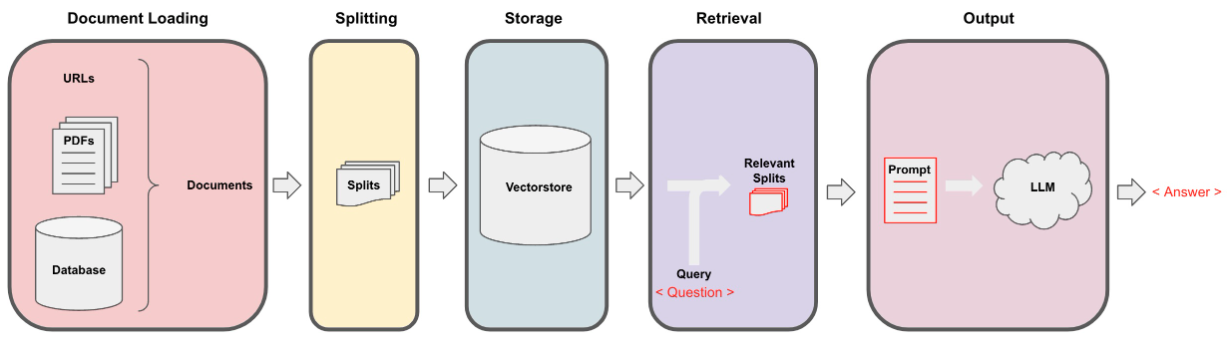
Os dados foram coletados através da extração iterativa usando o arquivo data_extraction.py. O código começa intimamente com apenas 2 links-['https://www.verizon.com/home/internet/'.'https://community.verizon.com/'] e, em seguida, no tempo de execução, elimina todos os links nessas duas páginas da web e esse processo, criando cerca de um padrão de pagas. Outra fonte de dados são os usuários disponíveis em https://www.verizon.com/about/terms-conditions/user-guides.
O LLMS não pode processar todos os dados e, portanto, precisamos dividir os dados em pequenas partes dos textos. O conjunto de dados foi dividido em pequenos pedaços usando a divisão de caracteres recursiva de Langchain. Depois de termos os pequenos pedaços, podemos criar suas incorporações usando o modelo Minilm-L12-V2 por meio de incorporações HuggingFace.
Depois que temos as incorporações correspondentes aos pedaços textuais, podemos armazená -lo em um banco de dados vetorial. Para nossa finalidade, usamos o VectorStore do FAISS (Facebook AI similaridade), pois é altamente eficaz ao calcular a similaridade em uma quantidade enorme de dados.
Para a parte de recuperação, tomamos a pergunta do usuário como uma entrada e encontramos os pedaços mais correspondentes armazenados no VectorStore usando a pesquisa do FAISS que poderia potencialmente responder à consulta do usuário.
Depois de termos nossos pedaços mais correspondentes, podemos rotulá -los como contexto e passá -los para o prompt personalizado para o nosso modelo. Para obter um propósito, usamos o seguinte prompt -
[ INST ] You are a Verizon company 's chatbot, Only use the following pieces of context to answer the user' s question . If the answer is not present in context , just say that you don 't know and display the following link "https://www.verizon.com/support/residential/contact-us/contactuslanding.htm", don' t try to make up an answer .[ / INST ]
Context : { context }
Question : { question }
answer : Agora, este prompt é passado para o LLM para obter a saída. O LLM que usamos é Mistral-7b (estado atual da arte de código aberto).


