VerAIzon
1.0.0
RAG (Retrieval Augmented Generation) Chatbot disertai dengan Mistral-7b, khusus dirancang untuk layanan pelanggan Verizon.
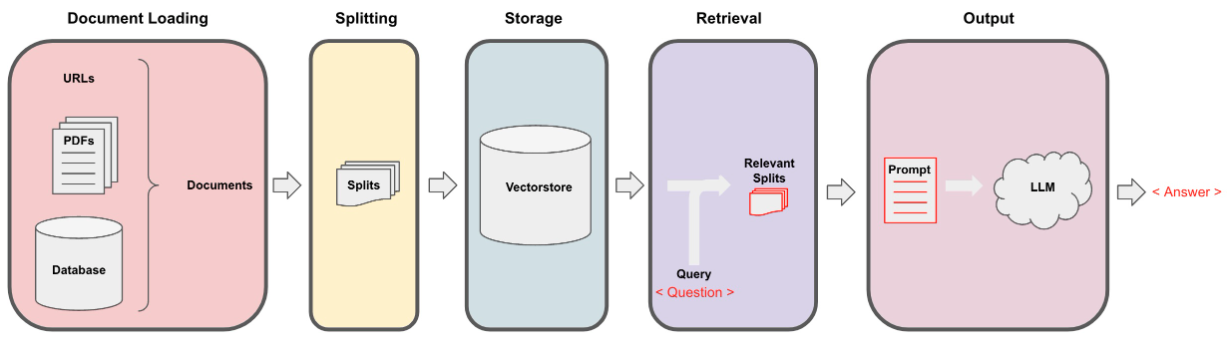
Data dikumpulkan melalui ekstraksi berulang menggunakan file data_extraction.py. Kode ini dimulai dengan hanya 2 tautan-['https://www.verizon.com/home/internet/' ,'https://community.verizon.com/'] dan kemudian pada run-time mengikis semua tautan di dua halaman web ini dan proses ini berlangsung, membuat sekitar satu dataset dari 1000 halaman. Sumber data lainnya adalah panduan pengguna yang tersedia di https://www.verizon.com/about/terms-conditions/user-guides.
LLMS tidak dapat memproses seluruh data dan dengan demikian kita perlu membagi data menjadi sebagian kecil teks. Dataset dipisahkan menjadi potongan -potongan kecil menggunakan pemisahan karakter rekursif dari langchain. Setelah kami memiliki potongan-potongan kecil, kami dapat membuat embedding menggunakan model all-minilm-L12-V2 melalui embeddings permukaan pelukan.
Setelah kami memiliki embeddings yang sesuai dengan potongan tekstual, kami dapat menyimpannya dalam database vektor. Untuk tujuan kami, kami menggunakan toko Vektor FAISS (Facebook AI kesamaan) karena sangat efisien ketika menghitung kesamaan dengan sejumlah besar data.
Untuk bagian pengambilan kami mengambil pertanyaan pengguna sebagai input dan menemukan potongan yang paling cocok yang disimpan di VectorStore menggunakan pencarian FAISS yang berpotensi menjawab permintaan pengguna.
Setelah kami memiliki potongan yang paling cocok, kami dapat memberi label sebagai konteks dan meneruskannya ke prompt khusus untuk model kami. Untuk tujuan keluar kami menggunakan prompt berikut -
[ INST ] You are a Verizon company 's chatbot, Only use the following pieces of context to answer the user' s question . If the answer is not present in context , just say that you don 't know and display the following link "https://www.verizon.com/support/residential/contact-us/contactuslanding.htm", don' t try to make up an answer .[ / INST ]
Context : { context }
Question : { question }
answer : Sekarang prompt ini diteruskan ke LLM untuk mendapatkan output. LLM yang kami gunakan adalah Mistral-7B (keadaan open-source saat ini).


