flora
1.0.0
背景
我如何在花园里浏览?
设计
建筑学
我们如何找到您的数据之间的连接?
渲染
数据在哪里?
指示
未来
致谢
一个数字花园的想法一直对我非常着迷。本月早些时候,我开始想知道我们如何将我们的数字花园不仅仅是页面上的文字呈现?我们如何使其互动并在浏览您的数字足迹方面创造体验?我们如何使我们的数字花园感觉像是一个真正的数字花园。
Flora是探索这一点的实验。
启动Flora时,在开始时在教程中详细说明了这一点 - 请参考。
在设计上定居花了数周的实验。我希望能够创建一种图形的感觉,以查看我的花园中的数据。挑战是创造直观但在技术上可行的东西(在一小段时间内)。这就是为什么我定居于与“森林”隔离的“父树”上,这些“森林”都是对父母的最相关数据的原因。 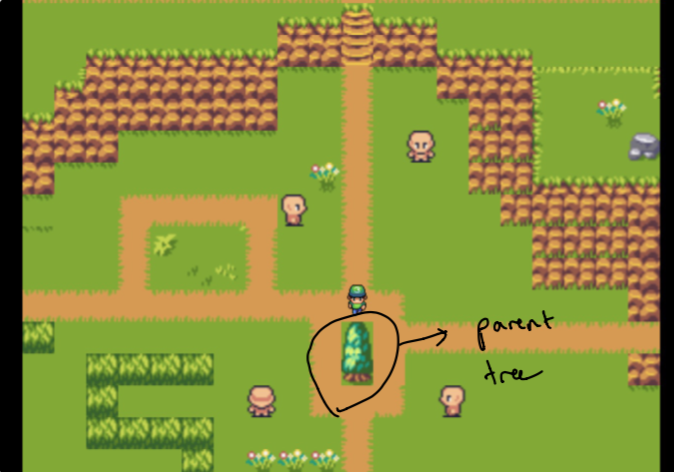
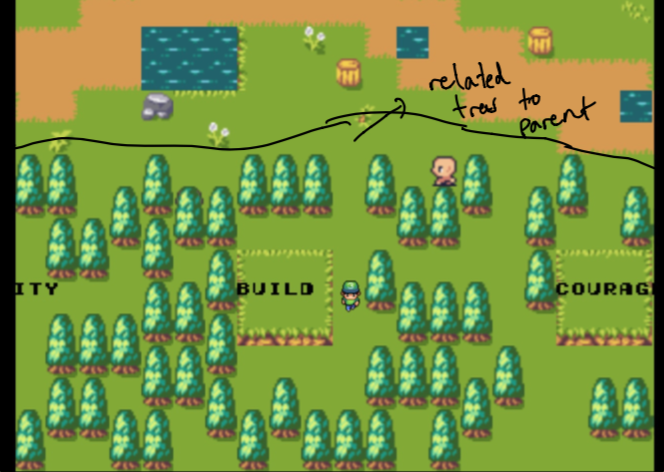
注意最初,父母只是我的家庭网站,森林由与我关心的主题最相似的数据组成。这些不是人工挑选的。稍后再详细介绍!
完整的地图是使用出色的Mapeditor工具完全从头开始设计的。
瓷砖集和地图都在map文件夹下完全可用,因此您可以完全播放它以使其自己。
有关我们如何渲染地图并添加游戏逻辑的更多详细信息,请参阅“渲染”部分。
Flora使用Pixi TileMap插件(用于快速的TiLemap渲染),并在前端上使用Poseidon和Pixi(为了帮助渲染)编写。它使用自定义的语义和全文搜索算法来在我的数字足迹中找到数据之间的连接。这有助于我们找到与任何特定数据或特定关键字的局部和词法相似的相关内容(您可能已经注意到的内容,我个人在第一个屏幕上为我个人加载了几个重要内容,例如初创企业,社区,附带项目等)。有关此算法的工作原理,请参见下面。
我喜欢称此步骤生成“按需图形”。我的大多数数据都不存在于包含双向链接的工具中 - 我的大多数数据都散布在一系列链接,注释,保存的文章等上。试图在数据中找到任何超链接(我保存为文本)几乎是不可能的。取而代之的是,我构建了Flora,以便我们可以做其他事情 - 我们可以使用自定义的语义和全文搜索算法来找到最相关的数据。
这采用了几种形式。给定特定的数据记录,我们可以通过这种方式找到该数据记录的其他最相关的数据记录,以模仿双向链接。
我们还可以给出特定的查询或单词,找到与该特定查询最相关的数据记录 - 这是您可能在演示视频中的第一个负载上注意到的,或者如果您尝试过(带有单词build , community , startups , side projects等)。因此,我们可以使用强大的搜索算法生成“按需图形”,其中包含两个值得注意的组件。
搜索算法的语义部分包括使用单词嵌入,它们是高维向量的单词嵌入,它们编码与单词相关的各种信息(例如,King一词的向量可能具有与男性,统治者等相关的一些信息)。这些构建的方式是我们可以在这些向量上操作的方式(即添加它们,平均减去它们)并保持有关结果的某种信息结构。
这意味着对于任何数据,我们都可以平均所有单词来创建文档向量,该文档向量只是一个试图编码/总结数据信息的单个向量。这样做的方法不仅仅是平均所有嵌入单词,但要实现这一目标的方法还要复杂,有意义,但是对于该项目的目的而言,这足够简单,可以实现并相对效果。
一旦我们拥有用于数据的文档向量,我们就可以使用余弦相似性找到这两个文档向量的相似之处(因此,任何两个数据的主题是多么相似)。
我使用Facebook创意共享的预先训练的单词插件许可的FastText Word嵌入数据集。具体来说,我使用了在此处找到的Wikipedia 2017 UMBC Webbase语料库中培训的数据中的50k单词。实际的数据集包含约100万个令牌,但我只是剪辑并使用第一个50k,以便我的服务器可以处理它。我可以将其更改或将来将其交换,我之所以选择它,是因为它具有最小的文件大小。
搜索的文本组件构建了每个数据的TF-IDF向量,该数据是存储文档中所有单词的令牌频率的向量。由于文档可能具有不同的词汇,因此这些TF-IDF矢量使用整个语料库的词汇,因此文档中未出现的任何单词对于向量中的关联位置都有0。
一旦我们拥有两个单词的TF-IDF向量,我们就可以再次使用余弦相似性来找到这些TF-IDF向量的相似之处(因此,对于任何两个数据,使用的单词是如何相似的)。
将这一切结合在一起,我们的“自定义得分”对于我的占地面积与另一个数据的相似性是如何的,只是文本搜索余弦相似性和语义搜索余弦相似性的平均值。
当我们为任何数据“沿兔子孔”“沿兔子孔”时,我们会计算足迹中初始数据和所有其他数据之间的分数,并使用这些分数对N最相关的分数进行排名,然后我们将其返回前端。
还记得我怎么说与某些单词相关的第一批树木没有被人工挑选吗?好吧,这是因为我们使用语义搜索找到最接近这些单词的单词嵌入的文档!
Flora使用Pixi进行渲染和Pixi TileMap插件来渲染地图。请注意,我不会详细介绍这些框架的工作原理,但是它们抽象了很多渲染,我们可以通过WebGL利用html帆布的后备,而在没有可用的情况下就可以通过WebGL进行优势。他们很棒!
就我们在植物群中的地图而言,没有实施淘汰(我尝试了一下,但无法使其从JSON文件中顺利进行,这是我加载地图的方式,喜欢一些指针!) - 相反,整个地图是从导出的JSON地图中加载的,我们显示了地图的小窗口/相机。
Flora将所有瓷砖都保持在我们整个地图的2D网格中。这也是它实现其碰撞检测系统的方式。请注意,Sprite不会“物理移动”,而是,我们围绕精灵旋转地图以给人以运动的幻觉。我们还保留一些指针,以跟踪当前的可见窗口,这些窗口在整个屏幕上的“移动”时在gameloop中偏移了。我们使用tilset.json文件,该文件是我们从MapEditor导出的瓷砖集来为每个瓷砖的任何相关信息加载,以确定瓷砖是否是树,不应让用户通过它移动(例如房屋的砖块)等并在我们的游戏循环中正确响应。
Flora在Apollo的数据上运行并倒立索引。如果您想能够将其用于自己的数据,则需要以Apollo数据的格式提供可用的数据(Apollo的Readme中的详细信息)或更改后端上的加载步骤以适应您的数据格式。
models和corpus文件夹go run cmd/flora.go启动服务器127.0.0.1:8992上运行,并且应该创建一个recordVectors.json 

