flora
1.0.0
Arrière-plan
Comment naviguer dans le jardin?
Conception
Architecture
Comment pouvons-nous trouver des connexions entre vos données?
Rendu
Où sont les données?
Instructions
Avenir
Remerciements
L'idée d'un jardin numérique a toujours été super fascinante pour moi. Plus tôt ce mois-ci, j'ai commencé à me demander comment pourrions-nous présenter notre jardin numérique comme plus que du texte sur une page? Comment pourrions-nous le rendre interactif et créer une expérience autour de la navigation sur votre empreinte numérique? Comment pourrions-nous faire en sorte que notre jardin numérique se sente comme un véritable jardin numérique .
Flora est une expérience pour explorer cela.
Ceci est expliqué en détail dans le tutoriel au début lorsque vous lancez Flora - veuillez vous référer à cela.
S'installer sur la conception a pris plusieurs semaines d'expériences. Je voulais pouvoir créer une atmosphère de type graphique pour voir les données de mon jardin. Le défi était de créer quelque chose qui était intuitif mais aussi techniquement faisable (dans un peu de temps). C'est pourquoi je me suis installé sur un "arbre parent" isolé des "forêts" qui sont toutes les données les plus apparentées au parent. 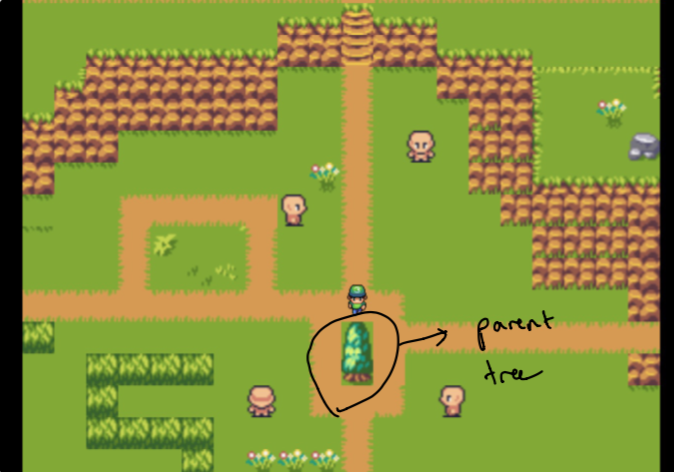
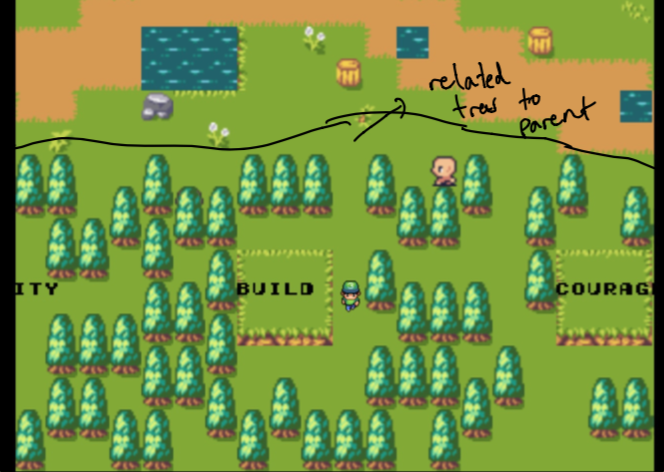
Notez au départ, le parent n'est que mon site Web d'origine et les forêts sont composées de données qui sont les plus similaires aux sujets qui m'intéressent. Ce ne sont pas triés sur le volet . Plus à ce sujet plus tard!
La carte complète est conçue en utilisant l'excellent outil MapEditor complètement à partir de zéro à l'aide d'un excellent Tileset que j'ai trouvé de Jestan.
Le Tileset et la carte sont entièrement disponibles dans le dossier map afin que vous puissiez jouer avec lui pour en faire le vôtre.
Reportez-vous à la section de rendu pour plus de détails sur la façon dont nous rendons la carte et ajoutez la logique du jeu.
Flora est écrite avec Poseidon et Pixi (pour obtenir de l'aide avec le rendu) sur le frontend, en utilisant un plugin Tilemap Pixi (pour le rendu rapide en tilemap) et allez sur le backend. Il utilise un algorithme de recherche sémantique et de texte complet personnalisé pour trouver des connexions entre les données dans mon empreinte numérique. Cela nous aide à trouver du contenu connexe à la fois par voie topique et lextiquement similaire à toutes les données spécifiques ou un mot-clé spécifique (dont vous pourriez avoir remarqué, je charge quelques-uns pour moi personnellement dans le premier écran, comme le démarrage, la communauté, les projets secondaires, etc.). Reportez-vous ci-dessous pour le fonctionnement de cet algorithme.
J'aime appeler cette étape générant un «graphique à la demande». La plupart de mes données ne vivent pas dans un outil qui contient des liens bidirectionnels - la plupart de mes données sont dispersées sur une gamme de liens, de notes, d'articles enregistrés, etc. Essayer de trouver des hyperliens dans les données (que j'ai enregistrés en tant que texte) serait presque impossible. Au lieu de cela, j'ai architeclé Flora afin que nous puissions faire autre chose à la place - nous pouvons utiliser un algorithme de recherche sémantique et en texte complet personnalisé pour trouver les données les plus apparentées .
Cela prend quelques formulaires. Compte tenu d'un enregistrement de données spécifique, nous pouvons trouver les autres enregistrements de données les plus connexes à celui-ci, de cette manière, imitant quelque peu un lien bidirectionnel.
Nous pouvons également, étant donné une requête ou un mot spécifique, trouver les enregistrements de données les plus liés à cette requête spécifique - ce que vous avez peut-être remarqué sur la première charge dans la vidéo de démonstration ou si vous l'avez essayé (avec les mots build , community , startups , side projects , etc.). Ainsi, nous pouvons générer un "graphique à la demande" avec un algorithme de recherche robuste, qui contient deux composants remarquables.
La partie sémantique de l'algorithme de recherche consiste à utiliser des incorporations de mots qui sont des vecteurs de grande dimension qui codent divers morceaux d'informations associés aux mots (par exemple, un vecteur du mot roi pourrait avoir certaines informations associées à un homme, un souverain, etc.). Ceux-ci sont construits de manière à ce que nous pouvons opérer sur ces vecteurs (c'est-à-dire les ajouter, les soustraire en moyenne) et maintenir une sorte de structure informationnelle sur le résultat.
Cela signifie que pour n'importe quelle pièce de données, nous pouvons en moyenne tous les mots pour créer un vecteur de document qui n'est qu'un seul vecteur qui tente d'encoder / résumer des informations sur une données. Il existe des moyens plus complexes et significatifs de le faire que de simplement faire de la moyenne de tous les mots intégrés, mais c'était assez simple pour mettre en œuvre et fonctionner relativement bien aux fins de ce projet.
Une fois que nous avons un vecteur de document pour un élément de données, nous pouvons utiliser la similitude du cosinus pour trouver à quel point ces deux vecteurs de documents similaires (et donc à quel point les sujets de deux données sont similaires).
J'utilise des embouts de mots pré-formés de l'ensemble de données Creative Commons FastText Word Embeddings de Creative Commons. Plus précisément, j'utilise des mots 50k à partir des données formées sur le corpus Webbase UMBC WEBC Wikipedia 2017 trouvé ici. L'ensemble de données réel contient ~ 1 million de jetons, mais je suis simplement en train de couper et d'utiliser les 50 km pour que mon serveur puisse le gérer. Je peux changer cela ou l'échanger à l'avenir, je viens de le choisir car il avait la plus petite taille de fichier.
Le composant texte de la recherche construit des vecteurs TF-IDF pour chaque élément de données, qui est un vecteur qui stocke les fréquences de jeton de tous les mots qui apparaissent dans un document. Étant donné que les documents peuvent avoir un vocabulaire différent, ces vecteurs TF-IDF utilisent le vocabulaire de l'ensemble du corpus, de sorte que tout mot qui n'apparaît pas dans le document a un 0 pour l'emplacement associé dans le vecteur.
Une fois que nous avons les vecteurs TF-IDF pour deux mots, nous pouvons à nouveau utiliser la similitude du cosinus pour trouver à quel point ces vecteurs TF-IDF sont similaires (et donc à quel point les mots utilisés sont similaires pour deux éléments de données).
Le rassemblement de tout cela, notre "score personnalisé" pour la similitude des données de mon empreinte à un autre n'est que la moyenne de la similitude du cosinus de recherche de texte et de la similitude du cosinus de recherche sémantique.
Lorsque nous «descendons un terrier de lapin» pour toute pièce de données, nous calculons les scores entre les données initiales et toutes les autres données de notre empreinte, et utilisons ces scores pour classer les n les plus pertinents, que nous retournons ensuite sur le frontend.
Rappelez-vous comment j'ai dit que les premiers arbres liés à certains mots ne sont pas triés sur le volet ? Eh bien, c'est parce que nous utilisons notre recherche sémantique pour trouver les documents qui sont les plus proches du mot incorporé de ces mots sélectionnés!
Flora utilise Pixi pour le rendu et le plugin Pixi Tilemap pour rendre la carte. Remarque Je n'entrerai pas dans trop de détails sur le fonctionnement de ces frameworks, mais ils abstracent une grande partie du rendu dont nous pouvons profiter via WebGL avec une secours sur la toile HTML lorsque cela n'est pas disponible. Ils sont super!
En termes de notre carte à Flora, aucune réduction n'est implémentée (je l'ai essayé mais je n'ai pas pu le faire fonctionner en douceur à partir d'un fichier JSON, c'est ainsi que je charge ma carte, j'aimerais certains pointeurs!) Par défaut - au lieu de cela, la carte entière est chargée à partir de la carte JSON exportée et nous affichons une petite fenêtre / caméra de la carte.
La flore conserve toutes les carreaux dans une grille 2D de lignes et de colonnes de toute notre carte. C'est aussi ainsi qu'il met en œuvre son système de détection de collision. Notez que le sprite ne "bouge pas physiquement" mais à la place, nous pivotons la carte autour du sprite pour donner l'illusion de mouvement. Nous gardons également des pointeurs pour suivre la fenêtre visible actuelle que nous compensions dans notre Gameloop alors que le sprite "se déplace" à travers l'écran. Nous utilisons le fichier tilset.json qui est notre ensemble de carreaux exportés de MapEditor pour charger toutes les informations pertinentes pour chaque tuile nécessaire pour déterminer si une tuile est un arbre, ne devrait pas permettre aux utilisateurs de le déplacer (par exemple, les briques de la maison), etc. et de répondre de manière appropriée dans notre boucle de jeu.
Flora fonctionne sur les données d'Apollo et l'index inversé. Si vous souhaitez pouvoir l'utiliser pour vos propres données, vous devrez rendre les données disponibles dans le format que les données d'Apollo sont disponibles (détails dans ReadMe d'Apollo) ou modifier les étapes de chargement sur le backend pour accueillir votre format de données.
models et un dossier corpusgo run cmd/flora.go127.0.0.1:8992 et un recordVectors.json aurait dû être créé contenant les vecteurs de documents de toutes les données / enregistrements de la base de données 

