flora
1.0.0
배경
정원을 어떻게 탐색합니까?
설계
건축학
데이터 간의 연결을 어떻게 찾을 수 있습니까?
표현
데이터는 어디에 있습니까?
지침
미래
감사의 말
디지털 정원의 아이디어는 항상 저에게 매우 매력적이었습니다. 이번 달 초, 나는 어떻게 우리가 디지털 정원을 페이지에서 단순한 텍스트 이상으로 발표 할 수 있는지 궁금해하기 시작 했습니까? 우리는 어떻게 대화식으로 만들고 디지털 발자국을 탐색하는 것에 대한 경험을 만들 수 있습니까? 디지털 정원이 실제 디지털 정원 처럼 느끼게 할 수있는 방법은 무엇입니까?
Flora는 이것을 탐구하는 실험입니다.
이것은 Flora를 시작할 때 시작시 튜토리얼에 자세히 설명되어 있습니다. 참조하십시오.
설계에 정착하는 데 몇 주가 걸렸습니다. 나는 정원에서 데이터를 볼 수있는 그래프와 같은 느낌을 만들고 싶었습니다. 도전은 직관적이지만 기술적으로 실현 가능한 무언가를 창조하는 것이 었습니다 (약간의 시간 내에). 그렇기 때문에 부모와 가장 관련된 가장 관련 데이터 조각 인 "숲"에서 분리 된 "부모 나무"에 정착 한 이유입니다. 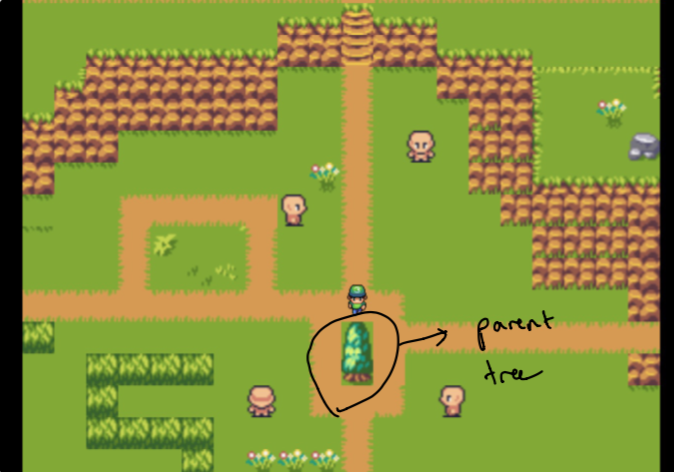
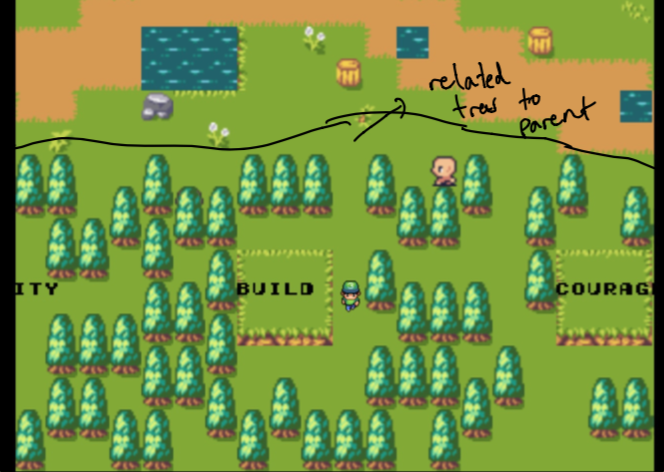
처음에는 부모가 내 홈 웹 사이트 일뿐 아니라 숲은 내가 관심있는 주제와 가장 유사한 데이터로 구성되어 있습니다. 이것들은 손으로 선택되지 않습니다 . 나중에 그것에 대해 더!
전체지도는 Jestan에서 찾은 훌륭한 타일 셋을 사용하여 우수한 Mapeditor 도구를 처음부터 완전히 사용하여 설계되었습니다.
Tileset과 Map은 모두 map 폴더 아래에서 완전히 사용할 수 있으므로 자신의 자체로 만들기 위해 완전히 재생할 수 있습니다.
맵을 렌더링하고 게임 로직을 추가하는 방법에 대한 자세한 내용은 렌더링 섹션을 참조하십시오.
Flora는 Poseidon과 Pixi (렌더링에 도움이되는)로 작성되었으며, Pixi Tilemap 플러그인 (빠른 Tilemap 렌더링)을 사용하여 백엔드를 사용합니다. 맞춤형 시맨틱 및 전체 텍스트 검색 알고리즘을 사용하여 디지털 풋 프린트의 데이터 간의 연결을 찾습니다. 이를 통해 특정 데이터 또는 특정 키워드와 국소 및 어휘가 유사한 관련 컨텐츠를 찾는 데 도움이됩니다. 이 알고리즘의 작동 방식은 아래를 참조하십시오.
나는이 단계를 "주문형 그래프"를 생성하는 것을 좋아합니다. 내 데이터의 대부분은 양방향 링크가 포함 된 도구에 남아 있지 않습니다. 대부분의 데이터는 다양한 링크, 메모, 저장된 기사 등에 흩어져 있습니다. 데이터 (텍스트로 저장 한) 내에서 하이퍼 링크를 찾는 것은 거의 불가능합니다. 대신, 나는 다른 것을 대신 할 수 있도록 플로라를 건축했습니다. 우리는 맞춤형 의미 및 전체 텍스트 검색 알고리즘을 사용하여 가장 관련된 데이터를 찾을 수 있습니다.
이것은 몇 가지 형태를 취합니다. 특정 데이터 레코드가 주어지면, 우리는 이것에 대해 다른 가장 관련된 데이터 레코드를 찾을 수 있습니다.
또한 특정 쿼리 나 단어가 주어지면 해당 쿼리와 가장 관련된 데이터 레코드를 찾을 수 있습니다. 이는 데모 비디오의 첫 번째로드 또는이를 시도한 경우 ( build , community , startups , side projects 등) 시도한 경우 귀하가 시도한 것입니다. 따라서 두 가지 주목할만한 구성 요소가 포함 된 강력한 검색 알고리즘으로 "주문형 그래프"를 생성 할 수 있습니다.
검색 알고리즘의 의미 론적 부분은 단어와 관련된 다양한 정보를 인코딩하는 고차원 벡터 인 단어 임베딩을 사용하는 것으로 구성됩니다 (예 : King이라는 단어의 벡터는 남성, 통치자 등과 관련된 정보를 가질 수 있습니다). 이것들은 우리 가이 벡터에서 작동 할 수있는 방식으로 구성되어 있습니다 (즉, 추가하고 평균을 빼고) 결과에 대한 정보 구조를 유지합니다.
이것은 모든 데이터를 의미합니다. 모든 단어를 평균하여 문서 벡터를 만들 수있는 모든 단어를 만들 수 있습니다. 문서 벡터는 데이터에 대한 정보를 인코딩/요약하려고 시도하는 단일 벡터입니다. 모든 단어 임베딩을 평균화하는 것보다 더 복잡하고 의미있는 방법이 있지만,이 프로젝트의 목적을 위해 비교적 잘 작동 할 수있을 정도로 간단했습니다.
데이터 조각에 대한 문서 벡터가 있으면 코사인 유사성을 사용 하여이 두 문서 벡터 (따라서 두 데이터의 주제가 얼마나 유사한 지)를 찾을 수 있습니다.
Facebook의 Creative Commons 라이센스가있는 FastText Word Embeddings 데이터 세트에서 미리 훈련 된 Word-embeddings를 사용합니다. 구체적으로 나는 여기에있는 Wikipedia 2017 UMBC 웹베이스 코퍼스에서 훈련 된 데이터에서 50k 단어를 사용합니다. 실제 데이터 세트에는 ~ 백만 개의 토큰이 포함되어 있지만 서버를 처리 할 수 있도록 첫 50k를 클립하고 사용합니다. 나는 이것을 변경하거나 앞으로 교체 할 수 있습니다. 파일 크기가 가장 작은 것이기 때문에 이것을 선택했습니다.
검색의 텍스트 구성 요소는 모든 데이터에 대한 TF-IDF 벡터를 구성합니다. 이는 문서에 나타나는 모든 단어의 토큰 주파수를 저장하는 벡터입니다. 문서에는 어휘가 다를 수 있으므로이 TF-IDF 벡터는 전체 코퍼스의 어휘를 사용하므로 문서에 나타나지 않는 단어는 벡터의 관련 위치에 대해 0이됩니다.
두 단어의 TF-IDF 벡터를 갖는 후에는 코사인 유사성을 다시 사용하여 이러한 TF-IDF 벡터가 얼마나 유사한지를 찾을 수 있습니다 (따라서 사용 된 단어가 두 가지 데이터에 대해 얼마나 유사한 지).
이 모든 것을 하나로 모으기 위해, 하나의 데이터가 다른 발자국인지에 대한 "사용자 정의 점수"는 텍스트 검색 코사인 유사성의 평균과 의미 론적 검색 코사인 유사성의 평균 일뿐입니다.
우리가 모든 데이터에 대해 "토끼 구멍을 내려가"할 때, 우리는 초기 데이터와 발자국의 다른 모든 데이터 사이의 점수를 계산하고 그 점수를 사용하여 가장 관련성이 높은 것의 순위를 정한 다음 프론트 엔드로 돌아갑니다.
특정 단어와 관련된 첫 번째 나무가 손으로 고르지 않았다고 말한 것을 기억하십니까? 우리는 의미 론적 검색을 사용하여 선택한 단어의 단어 임베딩에 가장 가까운 문서를 찾기 때문입니다!
Flora는 렌더링을 위해 Pixi를 사용하고 MAP 렌더링을 위해 Pixi Tilemap 플러그인을 사용합니다. 참고 나는 이러한 프레임 워크의 작동 방식에 대해 너무 자세하게 설명하지는 않지만, 사용할 수없는 경우 HTML 캔버스에서 낙하하여 WebGL을 활용할 수있는 많은 렌더링을 추출합니다. 그들은 훌륭합니다!
Flora의 맵의 관점에서, 컬링이 구현되지 않았다 (나는 그것을 시도했지만 내 맵을로드하는 방법, 일부 포인터를 좋아하는 JSON 파일에서 원활하게 작동 할 수 없다!) - 대신 전체 맵이 내보낸 JSON지도에서로드되며지도의 작은 창/카메라를 표시합니다.
Flora는 모든 타일을 전체지도의 2D 그리드와 열에 보관합니다. 또한 충돌 감지 시스템을 구현하는 방법이기도합니다. 스프라이트는 "물리적으로 움직이지 않고"대신 스프라이트 주변의지도를 피부하여 움직임의 환상을 제공합니다. 또한 스프라이트가 화면을 가로 질러 "움직임"할 때 Gameloop에서 오른쪽 눈에 띄는 현재 가시 창을 추적하기위한 몇 가지 포인터를 보관합니다. 우리는 MapEditor에서 내보내는 Tileset 인 tilset.json 파일을 사용하여 타일이 나무인지를 결정하는 데 필요한 각 타일에 대한 관련 정보를로드하고 사용자가 집의 벽돌을 이동하고 (예 : 집의 벽돌) 등을 게임 루프에 적절하게 응답 할 수 없습니다.
Flora는 Apollo의 데이터 및 역 지수에서 작동합니다. 자체 데이터에이를 사용하려면 Apollo의 데이터 형식으로 데이터를 사용할 수 있도록해야합니다 (Apollo의 readme의 세부 사항). 백엔드의로드 단계를 변경하여 데이터 형식을 수용하십시오.
models 과 corpus 폴더를 만듭니다go run cmd/flora.go 로 서버를 시작하십시오127.0.0.1:8992 에서 실행해야하며 recordVectors.json 은 데이터베이스의 모든 데이터/레코드의 문서 벡터를 포함하여 작성해야합니다. 

