flora
1.0.0
Hintergrund
Wie navigiere ich durch den Garten?
Design
Architektur
Wie finden wir Verbindungen zwischen Ihren Daten?
Rendering
Wo sind die Daten?
Anweisungen
Zukunft
Anerkennung
Die Idee eines digitalen Gartens war mir immer super faszinierend. Anfang dieses Monats habe ich mich gefragt, wie wir unseren digitalen Garten als mehr als nur einen Text auf einer Seite präsentieren könnten. Wie können wir es interaktiv machen und ein Erlebnis mit dem Durchsuchen Ihres digitalen Fußabdrucks schaffen? Wie könnten wir unseren digitalen Garten wie ein digitaler Garten anfühlen?
Flora ist ein Experiment, um dies zu erforschen.
Dies wird im Tutorial zu Beginn ausführlich erläutert, wenn Sie Flora starten. Weitere Informationen finden Sie im Tutorial.
Das Absetzen des Designs dauerte mehrere Wochen Experimente. Ich wollte in der Lage sein, ein graphisches Gefühl zu erstellen, um die Daten in meinem Garten anzusehen. Die Herausforderung bestand darin, etwas zu schaffen, das intuitiv, aber auch technisch machbar war (innerhalb von ein wenig Zeit). Aus diesem Grund habe ich mich für einen "Elternbaum" entschieden, der aus den "Wäldern" isoliert wurde, die alle die am meisten miteinander verbundenen Datenstücke für den Elternteil sind. 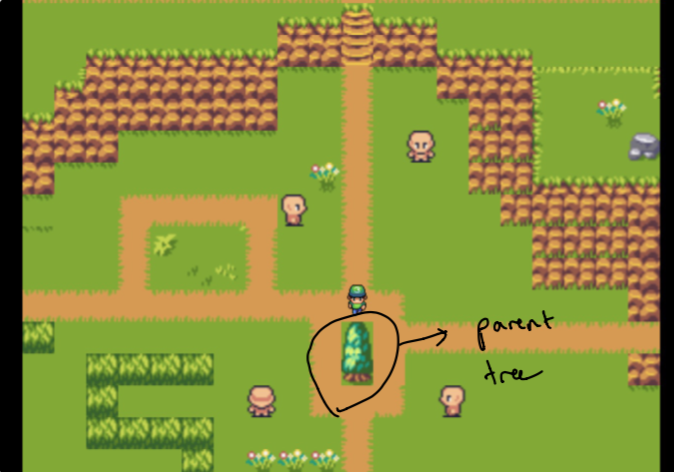
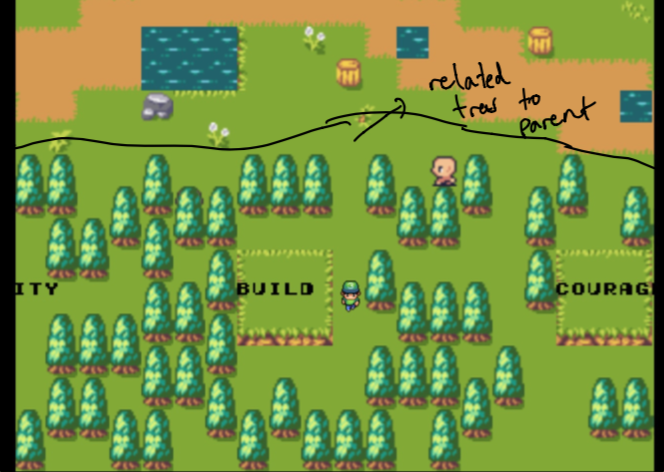
Beachten Sie zunächst, dass der Elternteil nur meine Heim -Website ist und die Wälder aus Daten bestehen, die den Themen, die mir wichtig sind, am ähnlichsten sind. Diese sind nicht handverlesen . Mehr dazu später!
Die vollständige Karte wurde mit dem exzellenten MapeDitor -Tool komplett von Grund auf mit einem großartigen Kachel aus Jestan entworfen.
Sowohl der Tileset als auch die Karte sind im map vollständig verfügbar, damit Sie vollständig damit spielen können, um sie zu Ihrem eigenen zu machen.
Weitere Informationen zum Rendern der Karte finden Sie im Abschnitt "Rendering" und fügen Sie die Spiellogik hinzu.
Flora ist mit Poseidon und Pixi (zur Hilfe beim Rendering) an der Frontend geschrieben, wobei ein Pixi Tilemap -Plugin (für das schnelle Tilemap -Rendering) verwendet wird und auf den Backend geht. Es verwendet einen benutzerdefinierten semantischen und Volltext-Suchalgorithmus, um Verbindungen zwischen Daten in meinem digitalen Fußabdruck zu finden. Dies hilft uns, verwandte Inhalte zu finden, die sowohl topisch als auch lexikalisch zu bestimmten Daten oder einem bestimmten Schlüsselwort (von dem Sie vielleicht bemerkt haben, dass ich im ersten Bildschirm, wie Startup, Gemeinschaft, Nebenprojekte usw., ein paar wichtige wichtige für mich persönlich lade). In der folgenden Funktionsweise finden Sie unten, wie dieser Algorithmus funktioniert.
Ich nenne diesen Schritt gerne und generiere ein "Diagramm auf Bedarf". Die meisten meiner Daten leben nicht in einem Tool, das bidirektionale Links enthält - die meisten meiner Daten sind über eine Reihe von Links, Notizen, gespeicherten Artikeln und vielem mehr verstreut. Es wäre nahezu unmöglich, Hyperlinks innerhalb der Daten zu finden (die ich als Text gespeichert habe). Stattdessen habe ich Flora so archiviert, dass wir stattdessen etwas anderes tun können - wir können einen benutzerdefinierten semantischen und Volltext -Suchalgorithmus verwenden, um die am meisten verwandten Datenstücke zu finden.
Dies nimmt ein paar Formen an. In Anbetracht eines spezifischen Datendatensatzes finden wir die anderen am meisten verwandten Datensätze, die auf diese Weise einen bidirektionalen Verknüpfung nachdenken.
Wir können auch eine bestimmte Abfrage oder ein bestimmtes Wort finden, die die Datensätze mit dieser speziellen Abfrage am meisten zusammenhängen - wie Sie es möglicherweise auf der ersten Last im Demo -Video bemerkt haben oder wenn Sie es ausprobiert haben (mit den build , community , startups , side projects usw.). Daher können wir mit einem robusten Suchalgorithmus, der zwei bemerkenswerte Komponenten enthält, ein "Diagramm auf Bedarf" generieren.
Der semantische Teil des Suchalgorithmus besteht darin, Worteinbettungen zu verwenden, bei denen es sich um hochdimensionale Vektoren handelt, die verschiedene mit Wörtern verbundene Informationen codieren (z. B. ein Vektor für das Wort König, möglicherweise einige Informationen haben, die mit Männern, Herrschern usw. verbunden sind). Diese werden so konstruiert, dass wir mit diesen Vektoren arbeiten können (dh sie hinzufügen, sie durchschnittlich subtrahieren) und eine Art Informationsstruktur über das Ergebnis beibehalten.
Dies bedeutet, dass wir für alle Daten alle Wörter im Durchschnitt können, um einen Dokumentvektor zu erstellen, der nur ein einzelner Vektor ist, der versucht, Informationen zu Daten zu codieren/zusammenzufassen. Es gibt komplexere und aussagekräftigere Möglichkeiten, dies zu tun, als nur das gesamte Wort Einbettungsdings zu ermitteln, aber dies war einfach genug, um sie implementieren zu können, und funktioniert relativ gut für den Zweck dieses Projekts.
Sobald wir einen Dokumentenvektor für ein Datenstück haben, können wir die Ähnlichkeit mit Cosinus verwenden, um festzustellen, wie ähnlich diese beiden Dokumentvektoren ähnlich sind (und wie ähnlich die Themen zweier Daten sind).
Ich benutze vorgebildete Wort-Embeddings aus dem Creative Commons-lizenzierten FastText-Word-Einbettungsdatensatz von Facebook. Insbesondere verwende ich 50k Wörter aus den Daten, die auf Wikipedia 2017 UMBC Webbase Corpus trainiert wurden. Der tatsächliche Datensatz enthält ~ 1 Million Token, aber ich habe einfach die ersten 50k, damit mein Server es verarbeiten kann. Ich kann dies ändern oder in Zukunft austauschen. Ich habe dies nur ausgewählt, weil es die kleinste Dateigröße hatte.
Die Textkomponente der Suchkonstrukte konstruiert TF-IDF-Vektoren für jedes Datenstück, der ein Vektor ist, der die Token-Frequenzen aller Wörter speichert, die in einem Dokument erscheinen. Da Dokumente möglicherweise unterschiedliche Vokabulare haben, verwenden diese TF-IDF-Vektoren das Vokabular des gesamten Korpus, so dass jedes Wort, das nicht im Dokument erscheint, einen 0 für den zugehörigen Ort im Vektor hat.
Sobald wir die TF-IDF-Vektoren für zwei Wörter haben, können wir erneut die Kosinus-Ähnlichkeit verwenden, um festzustellen, wie ähnlich diese TF-IDF-Vektoren sind (und daher, wie ähnlich die verwendeten Wörter für zwei Datenstücke sind).
Wenn wir dies alles zusammenbringen, ist unsere "benutzerdefinierte Punktzahl", wie ähnliche Daten mein Fußabdruck zu einem anderen sind, nur der Durchschnitt der Kosinus-Ähnlichkeit des Textsearchs und der Semantic-Search Cosinus-Ähnlichkeit.
Wenn wir für alle Daten "ein Kaninchenloch hinuntergehen", berechnen wir die Bewertungen zwischen den anfänglichen Daten und allen anderen Daten in unserem Fußabdruck und verwenden diese Ergebnisse, um die am relevantesten N einzuordnen, die wir dann am Frontend zurückgeben.
Erinnern Sie sich, wie ich sagte, die ersten Bäume, die mit bestimmten Wörtern zusammenhängen, sind nicht handverlesen ? Nun, das liegt daran, dass wir unsere semantische Suche verwenden, um die Dokumente zu finden, die dem Wort einbetteten, der diesen ausgewählten Wörtern am nächsten kommt!
Flora verwendet Pixi zum Rendering und das Pixi Tilemap -Plugin zum Rendern der Karte. Beachten Sie, dass ich nicht zu viel Details darüber eingehen werde, wie diese Frameworks funktionieren, aber sie werden viel von dem Rendering abstrahieren, das wir über WebGL mit einem Fallback auf HTML -Leinwand nutzen können, wenn dies nicht verfügbar ist. Sie sind großartig!
In Bezug auf unsere Karte in Flora wird keine Ausrüstung implementiert (ich habe es ausprobiert, konnte es aber nicht dazu bringen, aus einer JSON -Datei reibungslos zu arbeiten, sodass ich meine Karte lade, würde einige Hinweise lieben!) Stattdessen wird die gesamte Karte aus der exportierten JSON -Karte geladen und wir zeigen ein kleines Fenster/eine Kamera der Karte an.
Flora hält alle Kacheln in einem 2D -Raster aus Zeilen und Säulen unserer gesamten Karte. So implementiert es auch sein Kollisionserkennungssystem. Beachten Sie, dass sich das Sprite nicht "physisch bewegt", sondern die Karte um das Sprite drehen, um die Illusion der Bewegung zu geben. Wir behalten auch einige Hinweise, um das aktuelle sichtbare Fenster zu verfolgen, das wir in unserem Gameloop über den Bildschirm "bewegt". Wir verwenden die tilset.json -Datei, die unser exportierter Kachel vom MapeDitor ist, um relevante Informationen für jede Kachel zu laden, die erforderlich ist, um festzustellen, ob ein Kachel ein Baum ist, nicht zulassen, dass Benutzer sie durch sie bewegen (z. B. Ziegel des Hauses) usw. und in unserer Spielschleife aufgreifend reagieren.
Flora arbeitet mit den Daten von Apollo und einem invertierten Index. Wenn Sie dies für Ihre eigenen Daten verwenden möchten, müssen Sie die Daten in den Daten des Formats Apollo zur Verfügung stellen (Details in Apollos Readme) oder die Ladeschritte im Backend ändern, um Ihr Datenformat zu begleiten.
models und corpusgo run cmd/flora.go127.0.0.1:8992 ausgeführt werden und ein recordVectors.json sollte erstellt werden, der die Dokumentvektoren aller Daten/Datensätze aus der Datenbank enthält 

