flora
1.0.0
背景
庭をナビゲートするにはどうすればよいですか?
デザイン
建築
データ間の接続をどのように見つけますか?
レンダリング
データはどこにありますか?
説明書
未来
謝辞
デジタルガーデンのアイデアは、私にとって常に非常に魅力的でした。今月初め、私はどのようにしてページにテキスト以上のデジタルガーデンを提示できるのか疑問に思い始めました。どのようにしてそれをインタラクティブにし、デジタルフットプリントを閲覧することに関するエクスペリエンスを作成できますか?どのようにして、デジタルガーデンを実際のデジタルガーデンのように感じさせることができますか。
Floraはこれを探求する実験です。
これについては、Floraを起動するときの最初のチュートリアルで詳細に説明されています。それを参照してください。
デザインに落ち着くには、数週間の実験が必要でした。庭でデータを表示するためのグラフのような感触を作成できるようにしたかったのです。課題は、直感的でありながら技術的には実行可能なものを作成することでした(少し時間内に)。これが、親に最も関連するデータのすべてである「森」から隔離された「親の木」に落ち着いた理由です。 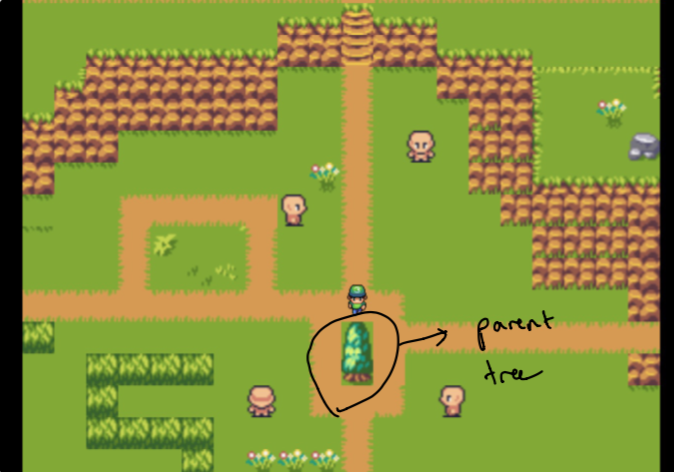
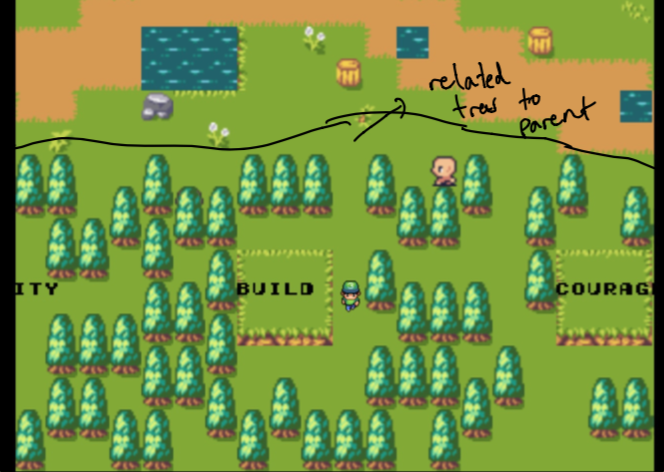
最初は、親は私のホームウェブサイトであり、森林は私が気にするトピックに最も似たデータで構成されています。これらは厳選されていません。それについては後で詳しく!
完全なマップは、Jestanから見つけた優れたタイルセットを使用して、優れたMapeditorツールをゼロから完全にゼロから完全に使用して設計されています。
タイルセットとマップの両方がmapフォルダーの下で完全に利用可能であるため、完全に再生して独自に再生できます。
マップのレンダリング方法とゲームロジックを追加する方法の詳細については、レンダリングセクションを参照してください。
Floraは、Pixi TileMapプラグイン(高速TileMapレンダリング用)を使用して、PoseidonとPixi(レンダリングのために)でフロントエンドで書かれ、バックエンドに移動します。カスタムセマンティックおよびフルテキスト検索アルゴリズムを使用して、デジタルフットプリント内のデータ間の接続を見つけます。これにより、特定のデータや特定のキーワード(気づいたかもしれない可能性のある特定のキーワードと格言的に類似している関連コンテンツを見つけることができます。最初の画面では、起動、コミュニティ、サイドプロジェクトなど、最初の画面にいくつかの重要なコンテンツをロードします)。このアルゴリズムの仕組みについては、以下を参照してください。
「オンデマンド」を生成するこのステップを呼び出すのが好きです。私のデータのほとんどは、双方向のリンクを含むツールに存在しません。私のデータのほとんどは、さまざまなリンク、メモ、保存された記事などに散らばっています。データ内のハイパーリンクを見つけようとすると(テキストとして保存しました)、ほぼ不可能です。代わりに、他の何かを行うことができるように、フローラをアーキテットしました。カスタムセマンティックとフルテキスト検索アルゴリズムを使用して、最も関連するデータを見つけることができます。
これにはいくつかのフォームが必要です。特定のデータレコードを考えると、これに他の最も関連するデータレコードを見つけることができます。このようにして、双方向のリンクをいくらか模倣します。
また、特定のクエリまたは単語を考慮して、その特定のクエリに最も関連するデータレコードを見つけることができます。これは、デモビデオの最初のロードで気づいたかもしれないこと、または試した場合community build startups 、 side projectsなど)。したがって、2つの注目すべきコンポーネントを含む堅牢な検索アルゴリズムを使用して「オンデマンドグラフ」を生成できます。
検索アルゴリズムのセマンティック部分は、単語に関連付けられたさまざまな情報をエンコードする高次元ベクトルである単語埋め込みを使用することで構成されています(たとえば、キングのベクトルは、男性、定規などに関連する情報を持っている可能性があります。これらは、これらのベクトルを操作できるように構築され(つまり、それらを追加し、平均を減算し、結果について何らかの情報構造を維持できるように構築されます。
これは、すべてのデータの場合、すべての単語を平均して、データに関する情報をエンコード/要約しようとする単一のベクトルであるドキュメントベクトルを作成できます。これを行うには、すべての単語埋め込みを平均化するよりも複雑で意味のある方法がありますが、これはこのプロジェクトの目的のために比較的うまく機能し、比較的うまく機能しました。
データ用のドキュメントベクトルがあると、Cosineの類似性を使用して、これら2つのドキュメントベクトル(したがって、2つのデータのトピックがどれほど類似しているか)を見つけることができます。
FacebookのCreative CommonsライセンスされたFastText Word Embeddings Datasetの事前に訓練されたWord-Beddingsを使用します。具体的には、ここで見つかったWikipedia 2017 UMBC Webbaseコーパスでトレーニングされたデータから50Kワードを使用します。実際のデータセットには約100万個のトークンが含まれていますが、サーバーが処理できるように、最初の50kをクリップして使用します。これを変更したり、将来交換したりすることができます。これを選択しました。これは、最小のファイルサイズがあったためです。
検索のテキストコンポーネントは、ドキュメントに表示されるすべての単語のトークン周波数を保存するベクトルであるすべてのデータのTF-IDFベクトルを構築します。ドキュメントには異なる語彙がある可能性があるため、これらのTF-IDFベクトルはコーパス全体の語彙を使用しているため、ドキュメントに表示されない単語は、ベクトルの関連する位置に0を持ちます。
2つの単語のTF-IDFベクトルを取得したら、Cosineの類似性を使用して、これらのTF-IDFベクターがどれほど類似しているかを見つけることができます(したがって、使用される単語が2つのデータでどれだけ類似しているか)。
これをすべてまとめると、あるデータが私のフットプリントに類似した「カスタムスコア」を別のデータに類似していることは、テキスト検索コサインの類似性とセマンティック検索コサインの類似性の平均です。
データの「ウサギの穴を下る」と、フットプリント内の最初のデータと他のすべてのデータの間のスコアを計算し、それらのスコアを使用して、フロントエンドで戻る最も関連性の高いスコアをランク付けします。
特定の単語に関連する最初の木が厳選されていないと言ったことを覚えていますか?それは、セマンティック検索を使用して、選択した単語の単語埋め込みに最も近いドキュメントを見つけるためです!
Floraは、レンダリングにPixiを使用し、マップをレンダリングするためにPixi TileMapプラグインを使用しています。これらのフレームワークがどのように機能するかについてはあまり詳しく説明することはありませんが、それが利用できないときにHTMLキャンバスのフォールバックでWebGLを介して利用できるレンダリングの多くを抽象化します。彼らは素晴らしいです!
フローラのマップに関しては、カリングは実装されていません(試しましたが、マップをロードする方法であるJSONファイルからスムーズに動作させることができませんでした。デフォルトでは、デフォルトでは、マップ全体がエクスポートされたJSONマップからロードされ、マップの小さなウィンドウ/カメラが表示されます。
Floraは、すべてのタイルをマップ全体の行と列の2Dグリッドに保持します。これは、衝突検出システムを実装する方法でもあります。スプライトは「物理的に動く」のではなく、代わりにスプライトの周りに地図を旋回させて動きの幻想を与えることに注意してください。また、Spriteが画面を「動く」ときにGameloopでオフセットする現在の可視ウィンドウを追跡するためのいくつかのポインターを保持します。 Mapeditorからエクスポートされたタイルセットであるtilset.jsonファイルを使用して、タイルがツリーであるかどうかを判断するために必要な各タイルに関連する情報をロードして、ユーザーがそれを通過させないようにし、ゲームループで適切に応答します。
Floraは、Apolloのデータと反転インデックスを操作します。これを独自のデータに使用できるようにしたい場合は、Apolloのデータをフォーマットに入手できるようにする必要があります(ApolloのREADMEの詳細)、またはバックエンドの読み込み手順を変更してデータ形式を付与します。
modelsとcorpusフォルダーを作成しますgo run cmd/flora.goでサーバーを開始します127.0.0.1:8992で実行され、 recordVectors.jsonがデータベースからのすべてのデータ/レコードのドキュメントベクトルを含む作成されたはずです

