flora
1.0.0
Fondo
¿Cómo navega por el jardín?
Diseño
Arquitectura
¿Cómo encontramos conexiones entre sus datos?
Representación
¿Dónde están los datos?
Instrucciones
Futuro
Expresiones de gratitud
La idea de un jardín digital siempre ha sido súper fascinante para mí. A principios de este mes, comencé a preguntarme cómo podríamos presentar nuestro jardín digital como algo más que solo enviar mensajes de texto en una página. ¿Cómo podríamos hacerlo interactivo y crear una experiencia en la navegación de su huella digital? ¿Cómo podríamos hacer que nuestro jardín digital se sienta como un jardín digital real ?
Flora es un experimento para explorar esto.
Esto se explica en detalle en el tutorial al principio cuando lanza Flora, consulte eso.
Acusarse en el diseño tomó varias semanas de experimentos. Quería poder crear una sensación de gráfico para ver los datos en mi jardín. El desafío fue crear algo que fuera intuitivo pero también técnicamente factible (en un poco de tiempo). Es por eso que me decidí por un "árbol principal" aislado de los "bosques" que son todos los datos más relacionados con el padre. 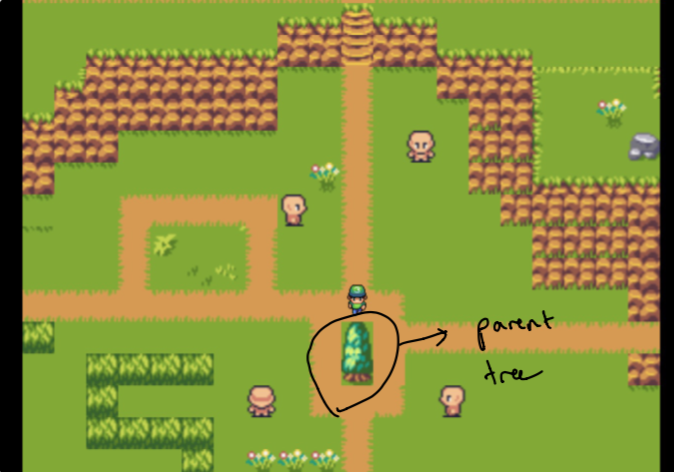
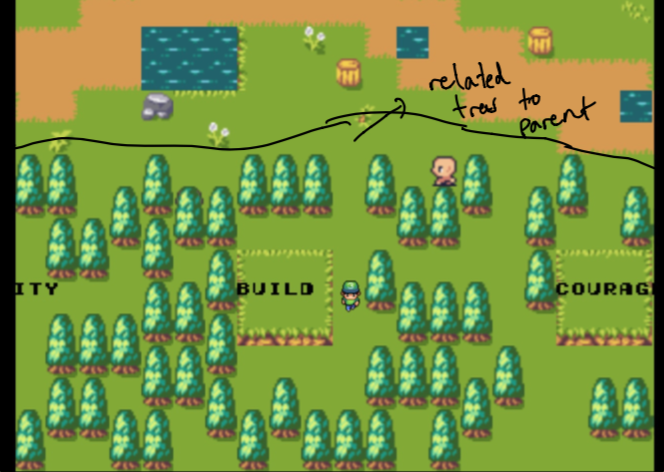
Nota Inicialmente, el padre es solo el sitio web de mi hogar y los bosques están compuestos de datos que son más similares a los temas que me importan. Estos no se seleccionan a mano . ¡Más sobre eso más tarde!
El mapa completo está diseñado utilizando la excelente herramienta MapEditor completamente desde cero utilizando un excelente conjunto de mosaicos que encontré desde Jestan.
Tanto las manchas como el mapa están completamente disponibles en la carpeta map para que pueda jugar completamente con él para que sea suyo.
Consulte la sección de renderizado para obtener más detalles sobre cómo representamos el mapa y agregamos la lógica del juego.
Flora está escrita con Poseidon y Pixi (para obtener ayuda con la representación) en la parte delantera, utilizando un complemento Pixi TilEmap (para el renderizado rápido de TilEmap) y vaya al backend. Utiliza un algoritmo de búsqueda semántica y de texto completo personalizado para encontrar conexiones entre los datos en mi huella digital. Esto nos ayuda a encontrar contenido relacionado que sea de manera tópica y léxica similar a cualquier datos específicos o una palabra clave específica (de la cual podría haber notado, me cargo un par de importantes para mí personalmente en la primera pantalla, como inicio, comunidad, proyectos secundarios, etc.). Consulte a continuación cómo funciona este algoritmo.
Me gusta llamar a este paso generando un "gráfico a pedido". La mayoría de mis datos no viven en una herramienta que contiene enlaces bidireccionales: la mayoría de mis datos están dispersos en una variedad de enlaces, notas, artículos guardados y más. Intentar encontrar hipervínculos dentro de los datos (que he guardado como texto) sería casi imposible. En su lugar, diseñé Flora para que pudiéramos hacer otra cosa en su lugar: podemos usar un algoritmo de búsqueda semántica y de texto completo personalizado para encontrar los datos más relacionados .
Esto adquiere un par de formas. Dado un registro de datos específico, podemos encontrar los otros registros de datos más relacionados para este, de esta manera, de esta manera, imitando un enlace bidireccional.
También podemos, dada una consulta o palabra específica, encontrar los registros de datos más relacionados con esa consulta específica, que es lo que podría haber notado en la primera carga en el video de demostración o si lo probó (con la build de palabras, community , startups , side projects , etc.). Por lo tanto, podemos generar un "gráfico a pedido" con un algoritmo de búsqueda robusto, que contiene dos componentes notables.
La parte semántica del algoritmo de búsqueda consiste en usar incrustaciones de palabras que son vectores de alta dimensión que codifican varios bits de información asociados con las palabras (por ejemplo, un vector para la palabra rey podría tener alguna información asociada con el hombre, la regla, etc.). Estos se construyen de tal manera que podamos operar en estos vectores (es decir, sumarlos, restarlos promedio) y mantener algún tipo de estructura informativa sobre el resultado.
Esto significa para cualquier dato, podemos promediar todas las palabras para crear un vector de documento que es solo un vector único que intenta codificar/resumir información sobre un datos. Hay formas más complejas y significativas de hacer esto que solo promediar todas las entradas de palabras, pero esto fue lo suficientemente simple como para implementar y funciona relativamente bien para el propósito de este proyecto.
Una vez que tenemos un vector de documento para una pieza de datos, podemos usar la similitud de coseno para encontrar cuán similares son estos dos vectores de documentos (y, por lo tanto, cuán similares son los temas de dos datos).
Utilizo las actividades de palabras previamente capacitadas del conjunto de datos de incrustaciones de palabras de palabras rápidas con licencia de Facebook Commons. Específicamente, uso 50k palabras de los datos capacitados en Wikipedia 2017 UMBC Webbase Corpus que se encuentran aquí. El conjunto de datos real contiene ~ 1 millón de tokens, pero solo recorto y uso los primeros 50k para que mi servidor pueda manejarlo. Puedo cambiar esto o intercambiarlo en el futuro, solo elegí esto porque tenía el tamaño de archivo más pequeño.
El componente de texto de la búsqueda construye vectores TF-IDF para cada pieza de datos, que es un vector que almacena las frecuencias de token de todas las palabras que aparecen en un documento. Dado que los documentos pueden tener un vocabularios diferentes, estos vectores TF-IDF usan el vocabulario de todo el corpus, de modo que cualquier palabra que no aparezca en el documento tenga un 0 para la ubicación asociada en el vector.
Una vez que tenemos los vectores TF-IDF para dos palabras, una vez más podemos usar la similitud de coseno para encontrar cuán similares son estos vectores TF-IDF (y por lo tanto, cuán similares son las palabras utilizadas para dos datos).
Al reunir todo esto, nuestro "puntaje personalizado" para cuán similares son los datos de mi huella a otra es solo el promedio de la similitud de coseno de búsqueda de texto y la similitud de coseno de búsqueda semántica.
Cuando "bajamos por una madriguera de conejos" para cualquier dato, calculamos los puntajes entre los datos iniciales y todos los demás datos en nuestra huella, y usamos esos puntajes para clasificar los N más relevantes, que luego regresamos en la interfaz.
¿Recuerdas cómo dije que los primeros árboles relacionados con ciertas palabras no están seleccionadas ? ¡Bueno, eso es porque usamos nuestra búsqueda semántica para encontrar los documentos que están más cerca de la palabra incrustaciones de esas palabras seleccionadas!
Flora usa Pixi para la representación y el complemento Pixi TilEmap para representar el mapa. Tenga en cuenta que no entraré en demasiados detalles sobre cómo funcionan estos marcos, pero abstraen una gran cantidad de la representación que podemos aprovechar a través de WebGL con una retroceso en el lienzo HTML cuando eso no está disponible. ¡Son geniales!
En términos de nuestro mapa en Flora, no se implementa un sacrificio (¡lo probé pero no pude hacer que funcione sin problemas desde un archivo JSON, que es cómo cargo mi mapa, me encantarán algunos consejos!) Por defecto, en cambio, todo el mapa se carga desde el mapa JSON exportado y mostramos una pequeña ventana/cámara del mapa.
Flora mantiene todas las baldosas en una cuadrícula 2D de filas y columnas de todo nuestro mapa. Así es como implementa su sistema de detección de colisiones. Tenga en cuenta que el sprite no se "mueve físicamente", pero en cambio, giramos el mapa alrededor del sprite para dar la ilusión del movimiento. También mantenemos algunos consejos para rastrear la ventana visible actual que compensamos en nuestro Gameloop a medida que el sprite "se mueve" a través de la pantalla. Utilizamos el archivo tilset.json , que es nuestro conjunto de mosaicos exportados desde MapEditor para cargar cualquier información relevante para cada mosaico que sea necesario para determinar si un mosaico es un árbol, no debe permitir que los usuarios se muevan a través de él (por ejemplo, ladrillos de la casa), etc. y respondan seguramente en nuestro bucle de juego.
Flora opera en los datos de Apolo y el índice invertido. Si desea poder usar esto para sus propios datos, deberá poner los datos disponibles en el formato Los datos de Apollo entran (detalles en el ReadMe de Apolo) o cambiar los pasos de carga en el backend para acomodar su formato de datos.
models y carpeta corpusgo run cmd/flora.go127.0.0.1:8992 y un recordVectors.json debería haberse creado que contenga los vectores de documentos de todos los datos/registros de la base de datos de la base de datos 

