flora
1.0.0
พื้นหลัง
ฉันจะนำทางสวนได้อย่างไร?
ออกแบบ
สถาปัตยกรรม
เราจะค้นหาการเชื่อมต่อระหว่างข้อมูลของคุณได้อย่างไร?
การแสดงผล
ข้อมูลอยู่ที่ไหน
คำแนะนำ
อนาคต
กิตติกรรมประกาศ
ความคิดของสวนดิจิตอลนั้นน่าหลงใหลมากสำหรับฉันเสมอ เมื่อต้นเดือนนี้ฉันเริ่มสงสัยว่าเราจะนำเสนอสวนดิจิตอลของเราเป็นมากกว่าข้อความบนหน้าเว็บได้อย่างไร? เราจะทำให้มันเป็นแบบโต้ตอบและสร้างประสบการณ์เกี่ยวกับการท่องรอยเท้าดิจิตอลของคุณได้อย่างไร เราจะทำให้สวนดิจิตอลของเรารู้สึกเหมือน สวนดิจิตอลจริง ได้อย่างไร
Flora เป็นการทดลองเพื่อสำรวจสิ่งนี้
สิ่งนี้มีการอธิบายอย่างละเอียดในการสอนเมื่อเริ่มต้นเมื่อคุณเปิดตัว Flora - โปรดดูที่
การตั้งถิ่นฐานในการออกแบบใช้เวลาหลายสัปดาห์ในการทดลอง ฉันต้องการสร้างความรู้สึกเหมือนกราฟสำหรับการดูข้อมูลในสวนของฉัน ความท้าทายคือการสร้างบางสิ่งที่ใช้งานง่าย แต่ก็เป็นไปได้ทางเทคนิค (ภายในเวลาไม่นาน) นี่คือเหตุผลที่ฉันตัดสินบน "ต้นไม้แม่" ที่แยกได้จาก "ป่า" ซึ่งเป็นข้อมูลที่เกี่ยวข้องมากที่สุดกับผู้ปกครอง 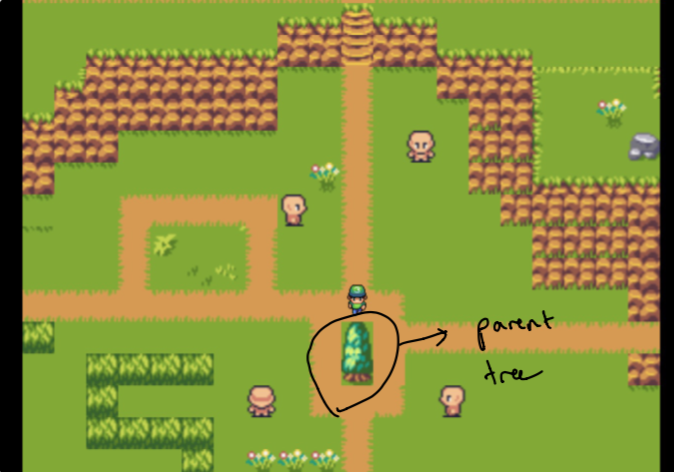
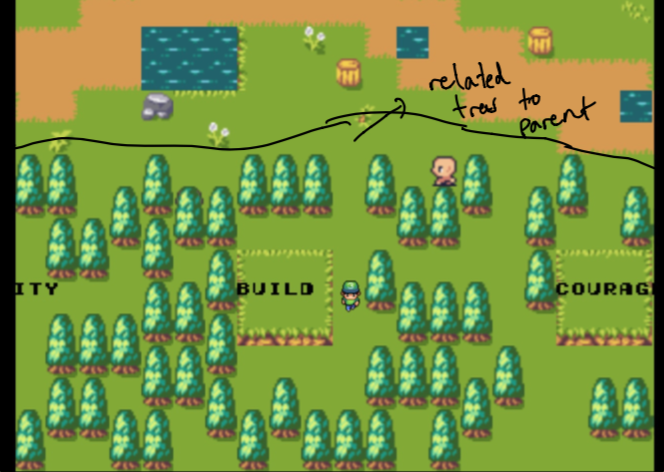
หมายเหตุเริ่มแรกผู้ปกครองเป็นเพียงเว็บไซต์บ้านของฉันและป่าประกอบด้วยข้อมูลที่คล้ายกับหัวข้อที่ฉันสนใจมากที่สุด สิ่งเหล่านี้ ไม่ได้รับการคัดเลือก เพิ่มเติมในภายหลัง!
แผนที่เต็มรูปแบบได้รับการออกแบบโดยใช้เครื่องมือ Mapeditor ที่ยอดเยี่ยมตั้งแต่เริ่มต้นโดยใช้กระเบื้องที่ยอดเยี่ยมที่ฉันพบจาก Jestan
ทั้ง Tileset และ Map มี ให้บริการอย่างเต็มที่ ภายใต้โฟลเดอร์ map เพื่อให้คุณสามารถเล่นได้อย่างเต็มที่เพื่อให้เป็นของคุณเอง
อ้างถึงส่วนการแสดงผลสำหรับรายละเอียดเพิ่มเติมเกี่ยวกับวิธีที่เราแสดงแผนที่และเพิ่มตรรกะเกม
Flora เขียนด้วย Poseidon และ Pixi (สำหรับความช่วยเหลือเกี่ยวกับการแสดงผล) ในส่วนหน้าโดยใช้ปลั๊กอิน Pixi Tilemap (สำหรับการแสดงผล TileMap ที่รวดเร็ว) และไปที่แบ็กเอนด์ มันใช้อัลกอริทึมการค้นหาแบบความหมายและข้อความแบบเต็มรูปแบบเพื่อค้นหาการเชื่อมต่อระหว่างข้อมูลในรอยเท้าดิจิตอลของฉัน สิ่งนี้จะช่วยให้เราค้นหาเนื้อหาที่เกี่ยวข้องซึ่งมีทั้งข้อมูลเฉพาะและ lexically คล้ายกับข้อมูลเฉพาะหรือคำหลักที่เฉพาะเจาะจง (ซึ่งคุณอาจสังเกตเห็นฉันโหลดสิ่งสำคัญสองอย่างสำหรับฉันเป็นการส่วนตัวในหน้าจอแรกเช่นการเริ่มต้นชุมชนโครงการด้านข้าง ฯลฯ ) อ้างอิงด้านล่างสำหรับวิธีการทำงานของอัลกอริทึมนี้
ฉันชอบเรียกขั้นตอนนี้ว่าสร้าง "กราฟตามความต้องการ" ข้อมูลส่วนใหญ่ของฉันไม่ได้อยู่ในเครื่องมือที่มีลิงก์แบบสองทิศทาง - ข้อมูลส่วนใหญ่ของฉันกระจัดกระจายไปทั่วลิงก์โน้ตบทความที่บันทึกไว้และอื่น ๆ การพยายามค้นหาไฮเปอร์ลิงก์ใด ๆ ภายในข้อมูล (ซึ่งฉันได้บันทึกเป็นข้อความ) จะเป็นไปไม่ได้ แต่ฉันได้ออกแบบพืชเพื่อให้เราสามารถทำอย่างอื่นแทน - เราสามารถใช้อัลกอริทึมการค้นหาแบบความหมายและข้อความเต็มรูปแบบที่กำหนดเองเพื่อค้นหาข้อมูล ที่เกี่ยวข้องมากที่สุด
สิ่งนี้ใช้ในสองรูปแบบ ด้วยการบันทึกข้อมูลเฉพาะเราสามารถค้นหาบันทึกข้อมูลที่เกี่ยวข้องมากที่สุดอื่น ๆ ในบันทึกนี้ด้วยวิธีนี้ค่อนข้างจะเลียนแบบลิงก์แบบสองทิศทาง
นอกจากนี้เรายังสามารถให้การสืบค้นหรือคำที่เฉพาะเจาะจงค้นหาบันทึกข้อมูลที่เกี่ยวข้องกับการสืบค้นนั้นส่วนใหญ่ - ซึ่งเป็นสิ่งที่คุณอาจสังเกตเห็นในการโหลดครั้งแรกในวิดีโอสาธิตหรือถ้าคุณลองใช้ (ด้วยคำ community build startups , side projects ฯลฯ ) ดังนั้นเราสามารถสร้าง "กราฟตามความต้องการ" ด้วยอัลกอริทึมการค้นหาที่มีประสิทธิภาพซึ่งมีสององค์ประกอบที่น่าจดจำ
ส่วนความหมายของอัลกอริทึมการค้นหาประกอบด้วยการใช้การฝังคำซึ่งเป็นเวกเตอร์มิติสูงที่เข้ารหัสข้อมูลต่าง ๆ ที่เกี่ยวข้องกับคำ (เช่นเวกเตอร์สำหรับคำว่ากษัตริย์อาจมีข้อมูลบางอย่างที่เกี่ยวข้องกับชายผู้ปกครอง ฯลฯ ) สิ่งเหล่านี้ถูกสร้างขึ้นในลักษณะที่เราสามารถใช้งานได้กับเวกเตอร์เหล่านี้ (เช่นเพิ่มพวกเขาลบพวกเขาโดยเฉลี่ย) และรักษาโครงสร้างข้อมูลบางอย่างเกี่ยวกับผลลัพธ์
ซึ่งหมายความว่าสำหรับข้อมูลใด ๆ เราสามารถเฉลี่ยคำทั้งหมดเพื่อสร้างเวกเตอร์เอกสารซึ่งเป็นเพียงเวกเตอร์เดียวที่พยายามเข้ารหัส/สรุปข้อมูลเกี่ยวกับข้อมูล มีวิธีที่ซับซ้อนและมีความหมายมากกว่าการทำสิ่งนี้มากกว่าการหาค่าเฉลี่ยทั้งหมดของคำที่ฝังอยู่ แต่นี่เป็นเรื่องง่ายพอที่จะนำไปใช้และทำงานได้ค่อนข้างดีเพื่อจุดประสงค์ของโครงการนี้
เมื่อเรามีเวกเตอร์เอกสารสำหรับชิ้นส่วนของข้อมูลเราสามารถใช้ความคล้ายคลึงกันของโคไซน์เพื่อค้นหาว่าเวกเตอร์เอกสารทั้งสองนี้คล้ายกัน (และด้วยเหตุนี้หัวข้อของข้อมูลสองชิ้นที่คล้ายกันอย่างไร)
ฉันใช้ embeddings word ที่ผ่านการฝึกอบรมมาก่อนจากชุดข้อมูล Creative Commons ของ Facebook ที่ได้รับใบอนุญาต FastText Word Word Embeddings โดยเฉพาะฉันใช้คำ 50K จากข้อมูลที่ได้รับการฝึกฝนบน Wikipedia 2017 UMBC Webbase Corpus พบที่นี่ ชุดข้อมูลจริงมีโทเค็นประมาณ 1 ล้านโท แต่ฉันเพิ่งคลิปและใช้ 50K แรกเพื่อให้เซิร์ฟเวอร์ของฉันสามารถจัดการได้ ฉันสามารถเปลี่ยนสิ่งนี้หรือสลับมันออกมาในอนาคตฉันแค่เลือกสิ่งนี้เพราะมันมีขนาดไฟล์ที่เล็กที่สุด
องค์ประกอบข้อความของการค้นหาสร้างเวกเตอร์ TF-IDF สำหรับข้อมูลทุกชิ้นซึ่งเป็นเวกเตอร์ที่เก็บความถี่โทเค็นของคำทั้งหมดที่ปรากฏในเอกสาร เนื่องจากเอกสารอาจมีคำศัพท์ที่แตกต่างกันเวกเตอร์ TF-IDF เหล่านี้ใช้คำศัพท์ของคลังข้อมูลทั้งหมดเพื่อให้คำใด ๆ ที่ไม่ปรากฏในเอกสารมี 0 สำหรับตำแหน่งที่เกี่ยวข้องในเวกเตอร์
เมื่อเรามีเวกเตอร์ TF-IDF สำหรับสองคำแล้วเราสามารถใช้ความคล้ายคลึงกันของโคไซน์อีกครั้งเพื่อค้นหาว่าเวกเตอร์ TF-IDF เหล่านี้มีความคล้ายคลึงกันอย่างไร (และด้วยเหตุนี้คำที่ใช้คล้ายกันสำหรับข้อมูลสองชิ้นใด ๆ )
เมื่อนำสิ่งนี้มารวมกัน "คะแนนที่กำหนดเอง" ของเราสำหรับข้อมูลที่คล้ายกันคือรอยเท้าของฉันไปยังอีกข้อมูลเป็นเพียงค่าเฉลี่ยของความคล้ายคลึงกันของการค้นหาข้อความและความคล้ายคลึงกันของการค้นหาความหมาย
เมื่อเรา "ลงไปในรูกระต่าย" สำหรับข้อมูลใด ๆ เราคำนวณคะแนนระหว่างข้อมูลเริ่มต้นและข้อมูลอื่น ๆ ทุกอย่างในรอยเท้าของเราและใช้คะแนนเหล่านั้นเพื่อจัดอันดับ N ที่เกี่ยวข้องมากที่สุดซึ่งเรากลับมาที่ส่วนหน้า
จำได้ไหมว่าฉันพูดว่าต้นไม้แรกที่เกี่ยวข้องกับคำบางคำ ไม่ได้รับการคัดเลือก ? นั่นเป็นเพราะเราใช้การค้นหาความหมายของเราเพื่อค้นหาเอกสารที่ ใกล้เคียง กับคำที่ฝังคำของคำที่เลือก!
Flora ใช้ Pixi สำหรับการแสดงผลและปลั๊กอิน Pixi Tilemap สำหรับการแสดงผลแผนที่ หมายเหตุฉันจะไม่ลงรายละเอียดมากเกินไปเกี่ยวกับวิธีการทำงานของเฟรมเวิร์กเหล่านี้ แต่พวกเขาเป็นนามธรรมของการแสดงผลจำนวนมากที่เราสามารถใช้ประโยชน์จากผ่าน WebGL ด้วยทางเลือกบนผืนผ้าใบ HTML เมื่อไม่สามารถใช้ได้ พวกเขายอดเยี่ยม!
ในแง่ของแผนที่ของเราใน Flora ไม่มีการคัดลอก (ฉันลองใช้ แต่ไม่สามารถทำให้มันทำงานได้อย่างราบรื่นจากไฟล์ JSON ซึ่งเป็นวิธีที่ฉันโหลดแผนที่ของฉันจะรักพอยน์เตอร์บางตัว!) โดยค่าเริ่มต้น - แทนที่จะใช้แผนที่ทั้งหมดจากแผนที่ JSON ที่ส่งออกและเราแสดงหน้าต่าง/กล้องขนาดเล็กของแผนที่
Flora เก็บกระเบื้องทั้งหมดไว้ในตาราง 2D ของแถวและคอลัมน์ของแผนที่ทั้งหมดของเรา นี่คือวิธีที่ใช้ระบบตรวจจับการชนกัน โปรดทราบว่าสไปรต์ไม่ได้ "เคลื่อนไหวทางร่างกาย" แต่เราหมุนแผนที่รอบ ๆ สไปรต์เพื่อให้ภาพลวงตาของการเคลื่อนไหว นอกจากนี้เรายังเก็บพอยน์เตอร์บางตัวเพื่อติดตามหน้าต่างที่มองเห็นปัจจุบันซึ่งเราชดเชยใน gameLoop ของเราเป็นสไปรต์ "เคลื่อนที่" ข้ามหน้าจอ เราใช้ไฟล์ tilset.json ซึ่งเป็นกระเบื้องส่งออกของเราจาก mapeditor เพื่อโหลดข้อมูลที่เกี่ยวข้องสำหรับแต่ละกระเบื้องที่จำเป็นในการพิจารณาว่ากระเบื้องเป็นต้นไม้ไม่ควรปล่อยให้ผู้ใช้เคลื่อนที่ผ่าน (เช่นอิฐบ้าน) ฯลฯ
Flora ดำเนินการกับข้อมูลของ Apollo และดัชนีคว่ำ หากคุณต้องการใช้ข้อมูลนี้สำหรับข้อมูลของคุณเองคุณจะต้องจัดทำข้อมูลในรูปแบบข้อมูลของ Apollo (รายละเอียดใน readme ของ Apollo) หรือเปลี่ยนขั้นตอนการโหลดบนแบ็กเอนด์เพื่อรองรับรูปแบบข้อมูลของคุณ
models และ corpus คลังข้อมูลgo run cmd/flora.go127.0.0.1:8992 และ recordVectors.json ควรถูกสร้างขึ้นที่มีเวกเตอร์เอกสารของข้อมูล/ระเบียนทั้งหมดจากฐานข้อมูล 

