flora
1.0.0
Fundo
Como faço para navegar no jardim?
Projeto
Arquitetura
Como encontramos conexões entre seus dados?
Renderização
Onde estão os dados?
Instruções
Futuro
Agradecimentos
A idéia de um jardim digital sempre foi super fascinante para mim. No início deste mês, comecei a me perguntar como poderíamos apresentar nosso jardim digital como mais do que apenas texto em uma página? Como podemos torná -lo interativo e criar uma experiência em navegar na sua pegada digital? Como poderíamos fazer nosso jardim digital parecer um jardim digital real .
Flora é um experimento para explorar isso.
Isso é explicado em detalhes no tutorial no início quando você inicia a Flora - consulte isso.
A instalação do design levou várias semanas de experimentos. Eu queria poder criar uma sensação de gráfico para visualizar os dados no meu jardim. O desafio era criar algo intuitivo, mas também tecnicamente viável (dentro de um pouco de tempo). É por isso que eu me acomodei em uma "árvore pai" isolada das "florestas", que são todos os dados mais relacionados aos pais. 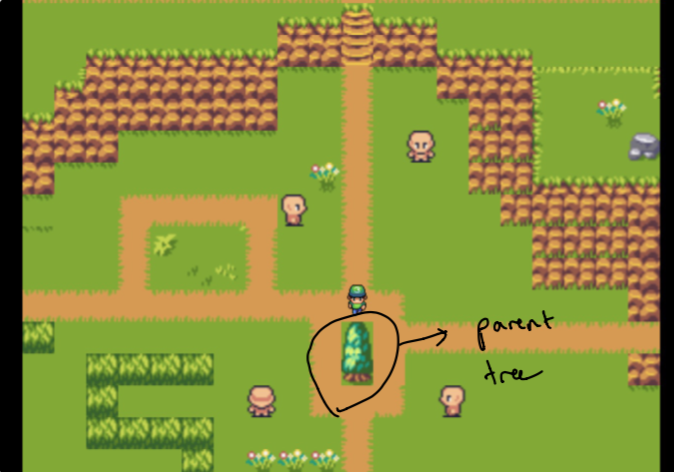
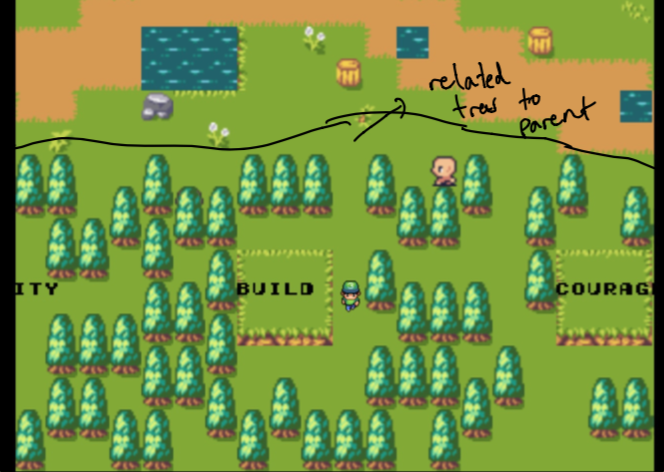
Nota Inicialmente, o pai é apenas o meu site doméstico e as florestas são compostas por dados mais semelhantes aos tópicos com os quais me preocupo. Estes não são escolhidos a dedo . Mais sobre isso mais tarde!
O mapa completo foi projetado usando a excelente ferramenta Mapeditor completamente do zero usando um ótimo azulejo que encontrei no Jestan.
O TileSet e o mapa estão totalmente disponíveis na pasta map , para que você possa brincar totalmente com ele para torná -lo o seu.
Consulte a seção de renderização para obter mais detalhes sobre como renderizamos o mapa e adicionamos a lógica do jogo.
Flora é escrita com Poseidon e Pixi (para obter ajuda na renderização) no front -end, usando um plug -in Pixi Tilemap (para renderização rápida de tilemap) e vá no back -end. Ele usa um algoritmo de pesquisa semântico e de texto completo personalizado para encontrar conexões entre dados na minha pegada digital. Isso nos ajuda a encontrar conteúdo relacionado que seja tópica e lexicamente semelhante a quaisquer dados específicos ou a uma palavra -chave específica (da qual você deve ter notado, carrego alguns importantes para mim pessoalmente na primeira tela, como startup, comunidade, projetos paralelos etc.). Consulte abaixo como esse algoritmo funciona.
Eu gosto de chamar essa etapa gerando um "gráfico sob demanda". A maioria dos meus dados não vive em uma ferramenta que contém links bidirecionais - a maioria dos meus dados está espalhada por uma variedade de links, notas, artigos salvos e muito mais. Tentar encontrar hiperlinks dentro dos dados (que eu salvei como texto) seria quase impossível. Em vez disso, arquitetei a flora para que pudéssemos fazer outra coisa - podemos usar um algoritmo de pesquisa semântico e de texto completo personalizado para encontrar os dados mais relacionados .
Isso assume algumas formas. Dado um registro de dados específico, podemos encontrar os outros registros de dados mais relacionados a este, dessa maneira, imitando um pouco um link bidirecional.
Também podemos, dada uma consulta ou palavra específica, encontrar os registros de dados mais relacionados a essa consulta específica - que é o que você deve ter notado na primeira carga no vídeo de demonstração ou se você tentou (com as palavras build , community , startups , side projects etc.). Assim, podemos gerar um "gráfico sob demanda" com um algoritmo de pesquisa robusto, que contém dois componentes dignos de nota.
A parte semântica do algoritmo de pesquisa consiste em usar incorporações de palavras, que são vetores de alta dimensão que codificam vários bits de informações associadas a palavras (por exemplo, um vetor para a palavra rei pode ter algumas informações associadas ao homem, governante etc.). Eles são construídos de tal maneira que podemos operar nesses vetores (ou seja, adicione -os, subtrai -los com média) e manter algum tipo de estrutura informativa sobre o resultado.
Isso significa que, para qualquer dados, podemos calcular todas as palavras para criar um vetor de documento, que é apenas um único vetor que tenta codificar/resumir informações sobre dados. Existem maneiras mais complexas e significativas de fazer isso do que apenas a média de todas as palavras incorporadas, mas isso foi simples o suficiente para implementar e funciona relativamente bem para os fins deste projeto.
Depois de termos um vetor de documento para uma peça de dados, podemos usar a similaridade de cosseno para encontrar o quão semelhantes esses dois documentos são vetores (e, portanto, quão semelhantes são os tópicos de dois dados).
Eu uso o trabalho pré-treinado a incorporação de palavras do conjunto de dados Creative Commons Fasttext Word licenciado do Facebook. Especificamente, uso 50 mil palavras dos dados treinados no Wikipedia 2017 UMBC Webbase Corpus encontrado aqui. O conjunto de dados real contém ~ 1 milhão de tokens, mas eu apenas preso e uso os primeiros 50k para que meu servidor possa lidar com ele. Eu posso mudar isso ou trocá -lo no futuro, apenas escolhi isso porque tinha o menor tamanho de arquivo.
O componente de texto dos constructos de pesquisa de TF-IDF para todos os dados, que é um vetor que armazena as frequências de token de todas as palavras que aparecem em um documento. Como os documentos podem ter vocabulários diferentes, esses vetores de TF-IDF usam o vocabulário de todo o corpus, para que qualquer palavra que não apareça no documento tenha um 0 para o local associado no vetor.
Depois de termos os vetores TF-IDF para duas palavras, podemos mais uma vez usar a similaridade de cosseno para encontrar o quão semelhantes esses vetores de TF-IDF são (e, portanto, quão semelhantes são as palavras usadas para quaisquer dois dados).
Reunindo tudo isso, nossa "pontuação personalizada" para o quão semelhantes os dados são minha pegada a outra é apenas a média da similaridade de cosseno para busca de texto e a similaridade de cosseno semântica.
Quando "descemos uma toca de coelho" para qualquer dados, calculamos as pontuações entre os dados iniciais e todos os outros dados em nossa pegada e usamos essas pontuações para classificar os N mais relevantes, que retornamos no front -end.
Lembra como eu disse que as primeiras árvores relacionadas a certas palavras não são escolhidas a dedo ? Bem, porque usamos nossa pesquisa semântica para encontrar os documentos mais próximos da palavra incorporação dessas palavras selecionadas!
Flora usa o Pixi para renderizar e o plug -in Pixi Tilemap para renderizar o mapa. Observe que não vou entrar em muitos detalhes sobre como essas estruturas funcionam, mas elas abstravam muitas das renderizações das quais podemos aproveitar via WebGL com um fallback na tela HTML quando isso não estiver disponível. Eles são ótimos!
Em termos de nosso mapa na flora, nenhum abate é implementado (eu o experimentei, mas não consegui fazer funcionar bem a partir de um arquivo JSON, que é assim que eu carrego meu mapa, adoraria alguns ponteiros!) Por padrão - o mapa inteiro é carregado do mapa JSON exportado e exibimos uma pequena janela/câmera do mapa.
A flora mantém todos os ladrilhos em uma grade 2D de linhas e colunas de todo o nosso mapa. É também assim que implementa seu sistema de detecção de colisão. Observe que o sprite não "se move fisicamente", mas, em vez disso, giramos o mapa ao redor do sprite para dar a ilusão de movimento. Também mantemos alguns indicadores para rastrear a janela visível atual que compensamos em nossa gameeloop como o Sprite "se move" na tela. Usamos o arquivo tilset.json , que é o nosso azulejo exportado do Mapeditor para carregar qualquer informação relevante para cada ladrilho necessário para determinar se um ladrilho é uma árvore, não deve permitir que os usuários se movam (por exemplo, tijolos da casa) etc. e respondemos de maneira apropriada em nosso loop de jogo.
A Flora opera nos dados da Apollo e no índice invertido. Se você deseja usá -lo para seus próprios dados, precisará disponibilizar os dados no formato Apollo Data (Detalhes no ReadMe da Apollo) ou alterar as etapas de carregamento no back -end para acompanhar seu formato de dados.
models e pasta corpusgo run cmd/flora.go127.0.0.1:8992 e um recordVectors.json deve ter sido criado contendo os vetores de documentos de todos os dados/registros do banco de dados 

