flora
1.0.0
Latar belakang
Bagaimana cara menavigasi taman?
Desain
Arsitektur
Bagaimana kami menemukan koneksi antara data Anda?
Rendering
Dimana datanya?
Instruksi
Masa depan
Ucapan Terima Kasih
Gagasan kebun digital selalu sangat menarik bagi saya. Awal bulan ini, saya mulai bertanya -tanya bagaimana kami bisa menyajikan taman digital kami lebih dari sekadar teks di halaman? Bagaimana kami bisa membuatnya interaktif dan membuat pengalaman di sekitar menjelajahi jejak digital Anda? Bagaimana kita bisa membuat taman digital kita terasa seperti taman digital yang sebenarnya .
Flora adalah percobaan untuk mengeksplorasi ini.
Ini dijelaskan secara rinci dalam tutorial di awal ketika Anda meluncurkan Flora - silakan merujuk itu.
Menyelesaikan desain membutuhkan beberapa minggu percobaan. Saya ingin dapat membuat nuansa seperti grafik untuk melihat data di kebun saya. Tantangannya adalah menciptakan sesuatu yang intuitif tetapi juga layak secara teknis (dalam sedikit waktu). Inilah sebabnya saya memilih "pohon induk" yang diisolasi dari "hutan" yang merupakan semua data yang paling terkait dengan induk. 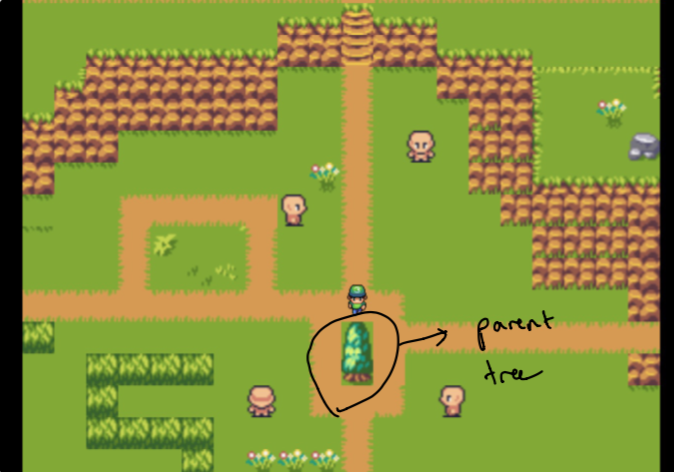
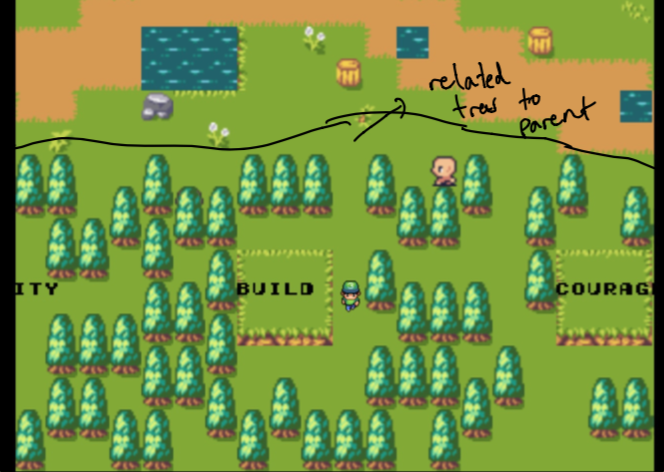
Catatan pada awalnya, orang tua hanyalah situs web rumah saya dan hutan terdiri dari data yang paling mirip dengan topik yang saya pedulikan. Ini tidak dipilih sendiri . Lebih lanjut tentang itu nanti!
Peta lengkap dirancang menggunakan alat MapEditor yang sangat baik sepenuhnya dari awal menggunakan tileset hebat yang saya temukan dari Jestan.
Baik tileset dan peta tersedia sepenuhnya di bawah folder map sehingga Anda dapat sepenuhnya bermain dengannya untuk membuatnya sendiri.
Lihat bagian Rendering untuk detail lebih lanjut tentang bagaimana kami membuat peta dan menambahkan logika game.
Flora ditulis dengan Poseidon dan Pixi (untuk bantuan dengan rendering) di frontend, menggunakan plugin Pixi Tilemap (untuk rendering tilemap cepat) dan pergi di backend. Ini menggunakan algoritma pencarian semantik dan teks lengkap khusus untuk menemukan koneksi antara data di jejak digital saya. Ini membantu kami menemukan konten terkait yang secara topikal dan leksikal mirip dengan data tertentu atau kata kunci tertentu (yang mungkin Anda perhatikan, saya memuat beberapa yang penting untuk saya secara pribadi di layar pertama, seperti startup, komunitas, proyek sampingan dll). Lihat di bawah untuk cara kerja algoritma ini.
Saya suka menyebut langkah ini menghasilkan "grafik sesuai permintaan." Sebagian besar data saya tidak hidup dalam alat yang berisi tautan dua arah - sebagian besar data saya tersebar di berbagai tautan, catatan, artikel yang disimpan, dan banyak lagi. Mencoba menemukan hyperlink dalam data (yang telah saya simpan sebagai teks) akan hampir mustahil. Sebagai gantinya, saya mengarsipkan flora sehingga kami dapat melakukan sesuatu yang lain - kami dapat menggunakan algoritma pencarian semantik dan teks lengkap khusus untuk menemukan bagian data yang paling terkait .
Ini mengambil beberapa bentuk. Dengan catatan data tertentu, kami dapat menemukan catatan data lain yang paling terkait untuk yang satu ini, dengan cara ini agak meniru tautan dua arah.
Kami juga dapat, dengan kueri atau kata tertentu, menemukan catatan data yang paling terkait dengan kueri spesifik itu - yang mungkin Anda perhatikan pada beban pertama dalam video demo atau jika Anda mencobanya (dengan kata -kata build , community , startups , side projects , dll.). Dengan demikian, kita dapat menghasilkan "grafik sesuai permintaan" dengan algoritma pencarian yang kuat, yang berisi dua komponen penting.
Bagian semantik dari algoritma pencarian terdiri dari menggunakan kata embeddings yang merupakan vektor dimensi tinggi yang menyandikan berbagai bit informasi yang terkait dengan kata-kata (misalnya vektor untuk kata raja mungkin memiliki beberapa informasi yang terkait dengan pria, penguasa dll.). Ini dibangun sedemikian rupa di mana kita dapat beroperasi pada vektor -vektor ini (yaitu menambahkannya, kurangi mereka rata -rata) dan mempertahankan semacam struktur informasi tentang hasilnya.
Ini berarti untuk setiap bagian data, kami dapat rata -rata semua kata untuk membuat vektor dokumen yang hanya merupakan vektor tunggal yang mencoba menyandikan/merangkum informasi tentang data. Ada cara yang lebih kompleks dan bermakna untuk melakukan ini daripada hanya rata -rata semua kata embeddings, tetapi ini cukup sederhana untuk diimplementasikan dan bekerja relatif baik untuk tujuan proyek ini.
Setelah kami memiliki vektor dokumen untuk sepotong data, kami dapat menggunakan kemiripan cosinus untuk menemukan seberapa mirip dua vektor dokumen ini (dan karenanya seberapa mirip topik dari dua bagian data).
Saya menggunakan kata-embeddings pra-terlatih dari dataset FastText Word Embeddings Creative Commons Facebook. Secara khusus saya menggunakan 50k kata dari data yang dilatih di Wikipedia 2017 UMBC Webbase Corpus yang ditemukan di sini. Dataset yang sebenarnya berisi ~ 1 juta token tetapi saya hanya klip dan menggunakan 50k pertama sehingga server saya dapat menanganinya. Saya dapat mengubah ini atau menukarnya di masa depan, saya hanya memilih ini karena memiliki ukuran file terkecil.
Komponen teks pencarian membuat vektor TF-IDF untuk setiap bagian data, yang merupakan vektor yang menyimpan frekuensi token dari semua kata yang muncul dalam dokumen. Karena dokumen mungkin memiliki kosa kata yang berbeda, vektor TF-IDF ini menggunakan kosakata seluruh korpus, sehingga kata apa pun yang tidak muncul dalam dokumen memiliki 0 untuk lokasi terkait di vektor.
Setelah kami memiliki vektor TF-IDF untuk dua kata, kami dapat sekali lagi menggunakan kemiripan kosinus untuk menemukan seberapa mirip vektor TF-IDF ini (dan karenanya seberapa mirip kata yang digunakan untuk dua potong data).
Menyatukan semua ini, "skor khusus" kami untuk seberapa mirip data satu jejak saya dengan yang lain hanyalah rata-rata dari kesamaan cosinus pencarian teks dan kesamaan cosinus pencarian semantik.
Ketika kami "turun lubang kelinci" untuk setiap data, kami menghitung skor antara bagian awal data dan setiap data lainnya dalam jejak kaki kami, dan menggunakan skor tersebut untuk memberi peringkat n yang paling relevan, yang kemudian kami kembalikan di frontend.
Ingat bagaimana saya mengatakan pohon pertama yang terkait dengan kata -kata tertentu tidak dipilih sendiri ? Nah itu karena kami menggunakan pencarian semantik kami untuk menemukan dokumen yang paling dekat dengan kata embeddings dari kata -kata yang dipilih!
Flora menggunakan Pixi untuk rendering dan plugin Pixi Tilemap untuk rendering peta. Catatan Saya tidak akan terlalu mendetail tentang bagaimana kerangka kerja ini bekerja, tetapi mereka mengabstraksi banyak rendering yang dapat kita manfaatkan melalui WebGL dengan fallback pada kanvas HTML ketika itu tidak tersedia. Mereka hebat!
Dalam hal peta kami di Flora, tidak ada pemusnahan yang diimplementasikan (saya mencobanya tetapi tidak bisa membuatnya bekerja dengan lancar dari file JSON yang merupakan cara saya memuat peta saya, akan menyukai beberapa petunjuk!) Secara default - sebaliknya seluruh peta dimuat dari peta JSON yang diekspor dan kami menampilkan jendela kecil/kamera peta.
Flora menyimpan semua ubin di grid 2D baris dan kolom dari seluruh peta kami. Ini juga bagaimana ia mengimplementasikan sistem deteksi tabrakannya. Perhatikan bahwa sprite tidak "bergerak secara fisik" tetapi sebaliknya, kami memutar peta di sekitar sprite untuk memberikan ilusi gerakan. Kami juga menyimpan beberapa petunjuk untuk melacak jendela yang terlihat saat ini yang kami offset di gameloop kami saat sprite "bergerak" melintasi layar. Kami menggunakan file tilset.json yang merupakan tileset yang diekspor dari MapEditor untuk memuat informasi yang relevan untuk setiap ubin yang diperlukan untuk menentukan apakah ubin adalah pohon, tidak boleh membiarkan pengguna bergerak melaluinya (misalnya batu bata rumah) dll dan merespons dengan tepat di loop permainan kami.
Flora beroperasi pada data Apollo dan indeks terbalik. Jika Anda ingin dapat menggunakan ini untuk data Anda sendiri, Anda harus membuat data tersedia dalam format data Apollo masuk (detail dalam ReadMe Apollo) atau mengubah langkah -langkah pemuatan pada backend untuk mengakomadasi format data Anda.
models dan folder corpusgo run cmd/flora.go127.0.0.1:8992 dan recordVectors.json seharusnya dibuat yang berisi vektor dokumen dari semua data/catatan dari database 

