flora
1.0.0
Фон
Как мне ориентироваться в саду?
Дизайн
Архитектура
Как мы находим соединения между вашими данными?
Рендеринг
Где данные?
Инструкции
Будущее
Благодарности
Идея цифрового сада всегда была очень увлекательной для меня. Ранее в этом месяце я начал задаваться вопросом, как мы могли бы представить наш цифровой сад как нечто большее, чем просто текст на странице? Как мы можем сделать его интерактивным и создать опыт просмотра вашего цифрового следа? Как мы можем сделать наш цифровой сад чувствовать себя настоящим цифровым садом .
Флора - эксперимент, чтобы исследовать это.
Это подробно объясняется в учебном пособии в начале, когда вы запускаете Flora - пожалуйста, обратитесь к этому.
Установление дизайна заняло несколько недель экспериментов. Я хотел иметь возможность создать ощущение, похожее на график для просмотра данных в моем саду. Задача заключалась в создании чего -то, что было интуитивно понятным, но и технически осуществимым (через немного времени). Вот почему я остановился на «родительском дереве», изолированном от «лесов», которые являются наиболее связанными частями данных для родителей. 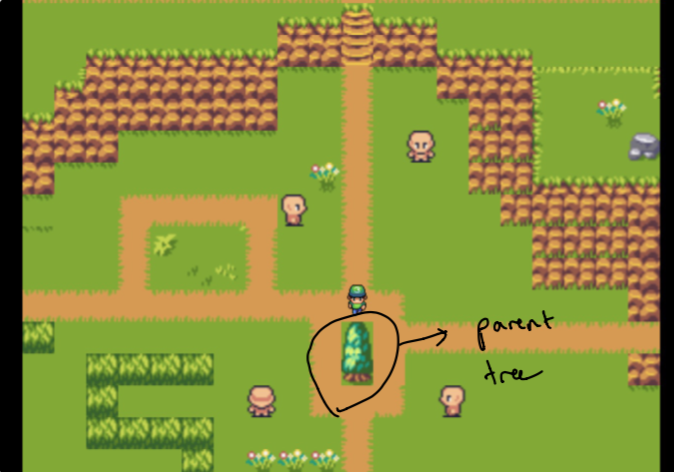
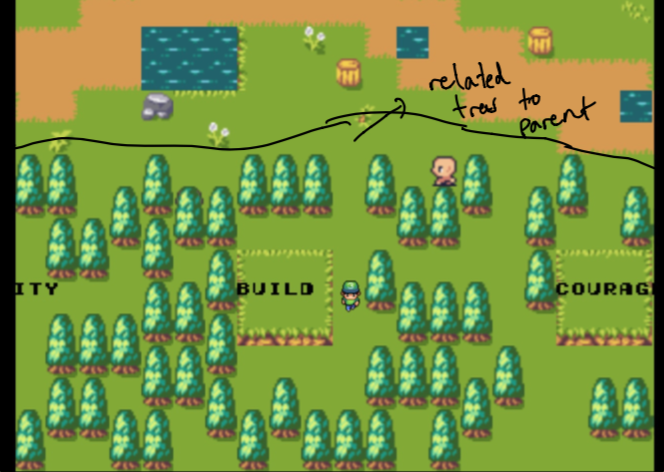
Первоначально обратите внимание, что родитель - это только мой домашний веб -сайт, и леса состоят из данных, которые наиболее похожи на темы, которые мне нужно. Они не выбраны вручную . Подробнее об этом позже!
Полная карта разработана с использованием отличного инструмента Mapeditor полностью с нуля, используя отличный плиток, который я нашел у Jestan.
Как плитка, так и карта полностью доступны в папке map так что вы можете полностью играть с ним, чтобы сделать это своим собственным.
Обратитесь к разделу рендеринга для получения более подробной информации о том, как мы отображаем карту и добавляем игровой логику.
Флора написана с Poseidon и Pixi (для помощи с рендерингом) на фронте, используя плагин Pixi Tilemap (для быстрого рендеринга Tilemap) и перейти на бэкэнд. Он использует пользовательский семантический и полнотекстовый алгоритм поиска, чтобы найти соединения между данными в моем цифровом следе. Это помогает нам найти связанный контент, который является тематическим и лексически похожим на любые конкретные данные или конкретное ключевое слово (о котором вы могли бы заметить, я загружаю несколько важных для меня на первом экране, таких как стартап, сообщество, побочные проекты и т. Д.). Ниже указать, как работает этот алгоритм.
Мне нравится называть этот шаг, создавая «график по требованию». Большая часть моих данных не живет в инструменте, который содержит двунаправленные ссылки - большая часть моих данных разбросана по ряду ссылок, заметок, сохраненных статей и многого другого. Попытка найти какие -либо гиперссылки в данных (которые я сохранил как текст) была бы почти невозможна. Вместо этого я зачитывал флору, чтобы вместо этого мы могли сделать что -то еще - мы можем использовать пользовательский семантический и полнотекстовый алгоритм поиска, чтобы найти наиболее связанные части данных.
Это принимает пару форм. Учитывая конкретную запись данных, мы можем найти другие наиболее связанные записи данных для этого, таким образом, несколько подмиривавшись по двунаправленной ссылке.
Мы также можем, учитывая конкретный запрос или слово, найти записи данных, наиболее связанные с этим конкретным запросом, что вы могли заметить при первой нагрузке в демонстрационном видео или, если вы пробовали его (со словами, community , build , side projects startups т. Д.). Таким образом, мы можем генерировать «график по требованию» с помощью надежного алгоритма поиска, который содержит два примечательных компонента.
Семантическая часть алгоритма поиска состоит из использования встроенных слов, которые представляют собой высокоразмерные векторы, которые кодируют различные биты информации, связанной со словами (например, вектор для слова King может иметь некоторую информацию, связанную с мужчинами, линейкой и т. Д.). Они построены таким образом, где мы можем работать на этих векторах (то есть добавить их, вычитайте их в среднем) и сохраняют некоторую информационную структуру о результате.
Это означает, что для любой части данных мы можем усреднить все слова, чтобы создать вектор документов, который представляет собой лишь единственный вектор, который пытается кодировать/суммировать информацию о данных. Существуют более сложные и значимых способов сделать это, чем просто усреднение всех слов встроения, но это было достаточно просто для реализации и работает относительно хорошо для целей этого проекта.
Как только у нас есть вектор документов для части данных, мы можем использовать сходство косинуса, чтобы узнать, насколько похожи эти два вектора документа (и, следовательно, насколько похожи темы любых двух частей данных).
Я использую предварительно обученные слова, лицензированные из Facebook Creative Commons, лицензированный набор данных Fasttext Word. В частности, я использую 50 тыс. Слова из данных, обученных в Wikipedia 2017 UMBC Webbase Corpus, найденный здесь. Фактический набор данных содержит ~ 1 миллион токенов, но я просто обрезаю и использую первые 50K, чтобы мой сервер мог справиться с ним. Я могу изменить это или поменять его в будущем, я просто выбрал это, потому что у него был наименьший размер файла.
Текстовый компонент поисковых конструкций векторов TF-IDF для каждой части данных, который является вектором, который хранит частоты токенов всех слов, которые появляются в документе. Поскольку документы могут иметь разные словесные слова, эти векторы TF-IDF используют словарный запас всего корпуса, так что любое слово, которое не появляется в документе, имеет 0 для ассоциированного местоположения в векторе.
Как только у нас есть векторы TF-IDF для двух слов, мы можем еще раз использовать сходство косинуса, чтобы узнать, насколько похожи эти векторы TF-IDF (и, следовательно, насколько используются слова для любых двух частей данных).
Собирая все это вместе, наш «пользовательский балл» для того, насколько похожи на мой след другой,-это просто среднее сходство косинуса и косинуса для поиска текста и сходство с семантическим поиском косинуса.
Когда мы «спускаемся в кроличье дыру» для любого фрагмента данных, мы рассчитываем оценки между первоначальной частью данных и любыми другими данными в нашем следе и используем эти оценки, чтобы ранжировать наиболее важные, которые мы затем возвращаем на фронта.
Помните, как я сказал, что первые деревья, связанные с определенными словами, не отобраны вручную ? Ну, это потому, что мы используем наш семантический поиск, чтобы найти документы, которые наиболее близки к слову встроения этих выбранных слов!
Flora использует Pixi для рендеринга и плагин Pixi Tilemap для рендеринга карты. Обратите внимание, что я не буду вдаваться в подробности о том, как работают эти рамки, но они абстрагируют много рендеринга, которым мы можем воспользоваться Via Webgl с запасением на холсте HTML, когда это недоступно. Они великолепны!
С точки зрения нашей карты во флоре, отбор не внедряется (я попробовал ее, но не мог заставить ее работать плавно из файла JSON, который, как я загружаю свою карту, хотел бы, чтобы некоторые указатели!) По умолчанию - вместо этого вся карта загружается с экспортированной карты JSON, и мы отображаем небольшое окно/камеру карты.
Флора держит все плитки в 2D сетке рядов и колонн всей нашей карты. Так также он реализует свою систему обнаружения столкновений. Обратите внимание, что спрайт не «физически движется», но вместо этого мы разворачиваем карту вокруг спрайта, чтобы создать иллюзию движения. Мы также сохраняем некоторые указатели, чтобы отслеживать текущее видимое окно, которое мы смещаемся в нашем Gameloop, когда спрайт «перемещается» по экрану. Мы используем файл tilset.json , который является нашим экспортируемым плитками от Mapeditor, чтобы загрузить любую соответствующую информацию для каждой плитки, которая необходима для определения того, является ли плитка деревом, не должна позволять пользователям проходить через нее (например, кирпичи дома) и отвечать в нашу игровой цикл.
Флора работает на данных Аполлона и инвертированного индекса. Если вы хотите иметь возможность использовать это для своих собственных данных, вам нужно будет сделать данные доступными в формате данных Apollo (подробно в Readme Apollo) или изменить шаги загрузки на бэкэнд, чтобы соответствовать вашему формату данных.
models и папки corpusgo run cmd/flora.go127.0.0.1:8992 , и должен был быть создан recordVectors.json , содержащий векторы документа всех данных/записей из базы данных 

