LLMsPracticalGuide
1.0.0
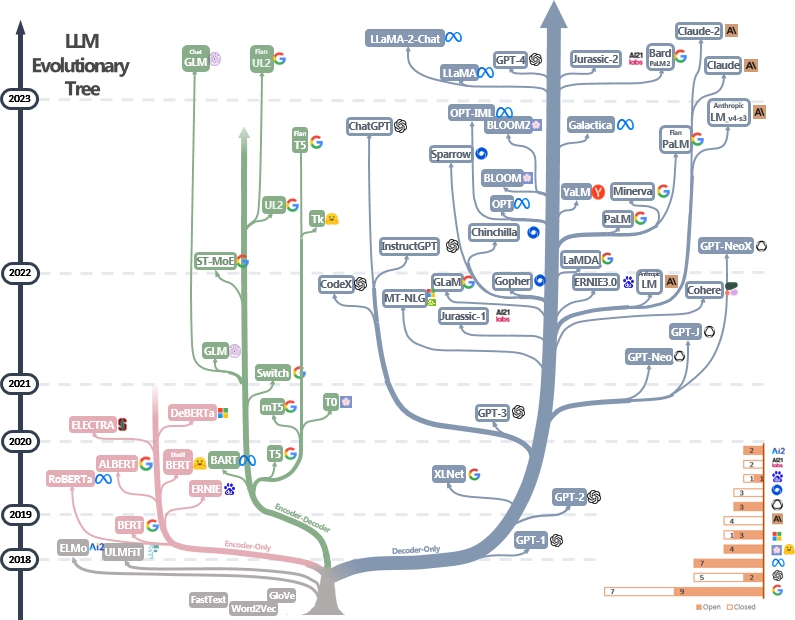
LLMS实用指南资源的策划(仍在积极更新)列表。它基于我们的调查论文:利用LLM的实践力量:Chatgpt及其境内的调查以及@xinyadu的努力。该调查部分基于此博客的后半部分。我们还建立了一棵现代大型语言模型(LLM)的进化树,以追踪近年来语言模型的发展,并突出显示一些最著名的模型。
这些资料旨在帮助从业者浏览大语言模型(LLM)的广阔景观及其在自然语言处理(NLP)应用中的应用。我们还根据模型和数据许可信息包括他们的使用限制。如果您在我们的存储库中发现任何资源有帮助,请随时使用它们(不要忘记引用我们的论文!?)。我们欢迎拉动请求来完善这个数字!
@article { yang2023harnessing ,
title = { Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond } ,
author = { Jingfeng Yang and Hongye Jin and Ruixiang Tang and Xiaotian Han and Qizhang Feng and Haoming Jiang and Bing Yin and Xia Hu } ,
year = { 2023 } ,
eprint = { 2304.13712 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
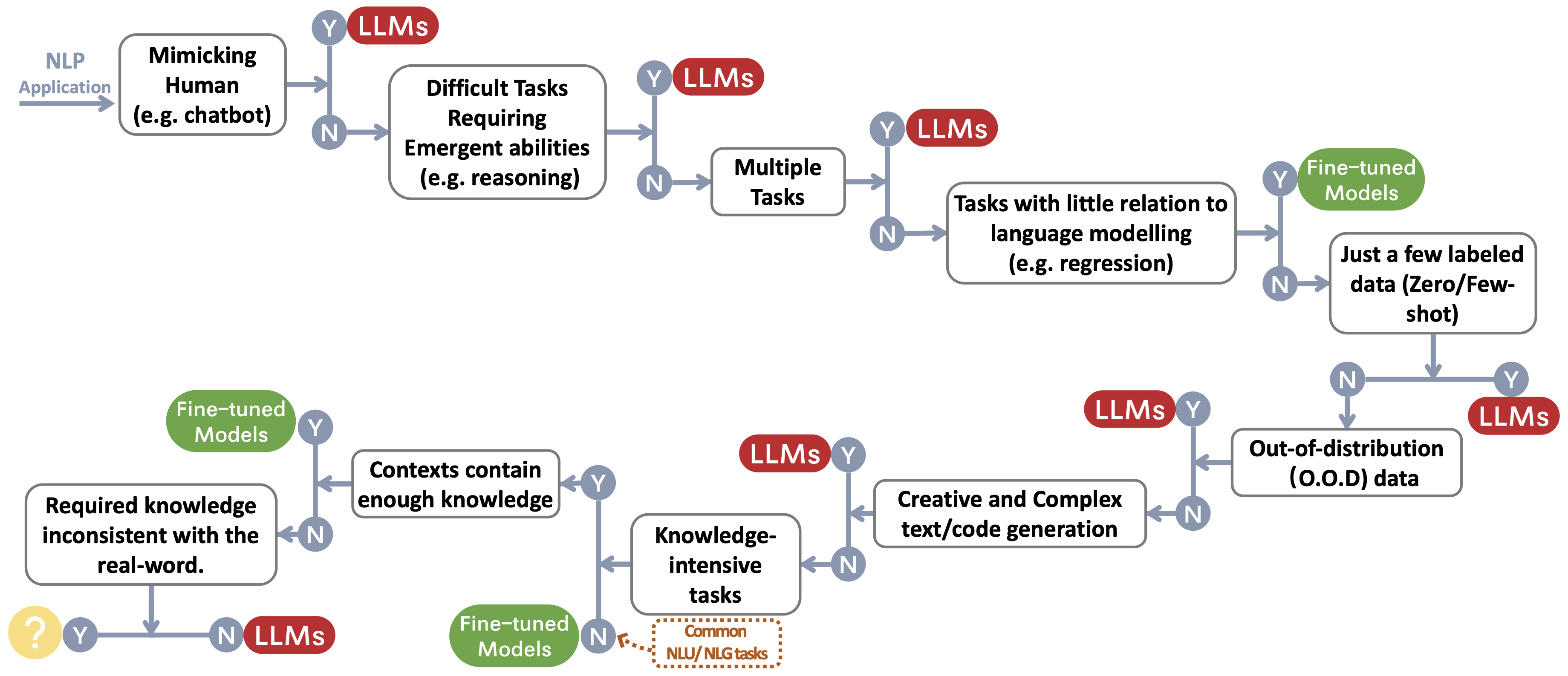
}我们为选择LLM或微调模型〜 protect footnotemark构建决策流,用于用户的NLP应用程序。决策流帮助用户评估其下游的NLP应用程序是否符合特定条件,并基于该评估,确定LLMS或微型模型是否是其应用程序最合适的选择。
我们构建了一个总结LLMS使用限制的表(例如,用于商业和研究目的)。特别是,我们从模型及其预处理数据的角度提供信息。我们敦促社区中的用户参考公共模型和数据的许可信息,并以负责任的方式使用它们。我们敦促开发人员特别注意许可,使他们透明和全面,以防止任何不必要的和无法预料的用法。
| LLMS | 模型 | 数据 | |||
|---|---|---|---|---|---|
| 执照 | 商业用途 | 其他明显的限制 | 执照 | 语料库 | |
| 仅编码 | |||||
| BERT系列模型(通用域) | Apache 2.0 | ✅ | 民众 | Bookscorpus,英语Wikipedia | |
| 罗伯塔 | 麻省理工学院许可证 | ✅ | 民众 | BookCorpus,CC-News,OpenWebText,故事 | |
| 厄尼 | Apache 2.0 | ✅ | 民众 | 英语维基百科 | |
| Scibert | Apache 2.0 | ✅ | 民众 | 伯特语料库,语义学者114万篇论文 | |
| Legalbert | CC BY-SA 4.0 | 公共(判例法访问项目的数据除外) | 欧盟立法,美国法院案件等 | ||
| 生物Biobert | Apache 2.0 | ✅ | PubMed | PubMed,PMC | |
| 编码器 | |||||
| T5 | Apache 2.0 | ✅ | 民众 | C4 | |
| Flan-T5 | Apache 2.0 | ✅ | 民众 | C4,任务的混合物(图2中的图2) | |
| 巴特 | Apache 2.0 | ✅ | 民众 | 罗伯塔语料库 | |
| Glm | Apache 2.0 | ✅ | 民众 | bookscorpus和英语维基百科 | |
| chatglm | chatglm许可证 | 无用于非法目的或军事研究,不会损害社会的公共利益 | N/A。 | 中文和英语语料库的1T令牌 | |
| 仅解码 | |||||
| GPT2 | 修改后的MIT许可证 | ✅ | 负责任地使用GPT-2,并清楚地表明您的内容是使用GPT-2创建的。 | 民众 | WebText |
| gpt-neo | 麻省理工学院许可证 | ✅ | 民众 | 桩 | |
| GPT-J | Apache 2.0 | ✅ | 民众 | 桩 | |
| --->多莉 | CC由NC 4.0 | CC由NC 4.0,遵守OpenAI生成的数据的使用条款 | 堆,自我指导 | ||
| ---> gpt4all-j | Apache 2.0 | ✅ | 民众 | GPT4ALL-J数据集 | |
| 毕田 | Apache 2.0 | ✅ | 民众 | 桩 | |
| ---> Dolly V2 | 麻省理工学院许可证 | ✅ | 民众 | 堆,数据映 - dolly-15k | |
| 选择 | OPT-175B许可协议 | 没有与监视研究和军事有关的发展,也不会损害社会的公共利益 | 民众 | Roberta Corpus,堆,PushShift.io reddit | |
| ---> opt-iml | OPT-175B许可协议 | 同样选择 | 民众 | Opt copus,超简短结构的扩展版本 | |
| YALM | Apache 2.0 | ✅ | 未指定 | 堆,团队收集了俄语的文字 | |
| 盛开 | Bigscience Rail许可证 | ✅ | 无需使用可危害他人的目的来生成虚假信息; 内容没有明确否认文本是机器生成的 | 民众 | Roots copus(Lauren≥Con等,2022) |
| ---> Bloomz | Bigscience Rail许可证 | ✅ | 也很开心 | 民众 | 根语料库,xp3 |
| 银河系 | CC BY-NC 4.0 | N/A。 | Galactica语料库 | ||
| 骆驼 | 非商业定制许可证 | 没有与监视研究和军事有关的发展,也不会损害社会的公共利益 | 民众 | CommonCrawl,C4,Github,Wikipedia等。 | |
| --->羊驼 | CC由NC 4.0 | CC由NC 4.0,遵守OpenAI生成的数据的使用条款 | Llama语料库,自我指导 | ||
| --->维库纳 | CC由NC 4.0 | 遵守OpenAI生成的数据的使用条款; 共享的隐私惯例 | Llama语料库,ShareGPT.com的70k对话 | ||
| ---> gpt4All | GPL许可的骆驼 | 民众 | GPT4ALL数据集 | ||
| Ottinllama | Apache 2.0 | ✅ | 民众 | Redpajama | |
| Codegeex | Codegeex许可证 | 无用于非法目的或军事研究 | 民众 | 堆,codeparrot,等。 | |
| Starcoder | BigCode OpenRail-M V1许可证 | ✅ | 无需使用可危害他人的目的来生成虚假信息; 内容没有明确否认文本是机器生成的 | 民众 | 堆栈 |
| MPT-7B | Apache 2.0 | ✅ | 民众 | MC4(英语),堆栈,Redpajama,S2orc | |
| 鹘 | TII Falcon LLM许可证 | ✅/ | 根据允许商业用途的许可证可用 | 民众 | 精制网络 |


