Panduan Praktis untuk Model Bahasa Besar
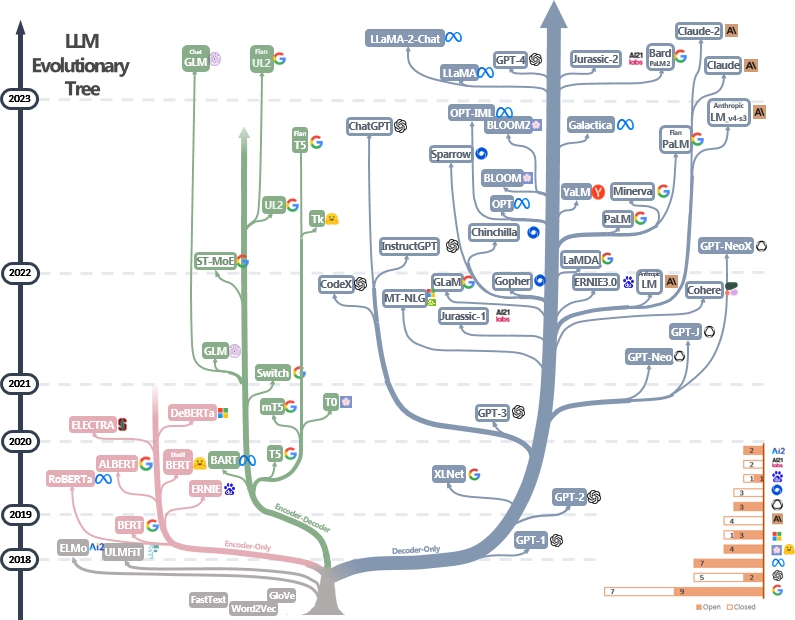
Daftar sumber daya panduan praktis yang dikuratori (masih aktif diperbarui). Ini didasarkan pada makalah survei kami: memanfaatkan kekuatan LLM dalam praktik: survei tentang chatgpt dan di luar dan upaya dari @xinyadu. Survei ini sebagian didasarkan pada paruh kedua blog ini. Kami juga membangun pohon evolusi model bahasa besar modern (LLM) untuk melacak pengembangan model bahasa dalam beberapa tahun terakhir dan menyoroti beberapa model yang paling terkenal.
Sumber -sumber ini bertujuan untuk membantu para praktisi menavigasi lanskap besar model bahasa besar (LLM) dan aplikasi mereka dalam aplikasi pemrosesan bahasa alami (NLP). Kami juga memasukkan pembatasan penggunaan mereka berdasarkan informasi model dan lisensi data. Jika Anda menemukan sumber daya dalam repositori kami bermanfaat, jangan ragu untuk menggunakannya (jangan lupa untuk mengutip kertas kami!?). Kami menyambut permintaan tarik untuk memperbaiki angka ini!
@article { yang2023harnessing ,
title = { Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond } ,
author = { Jingfeng Yang and Hongye Jin and Ruixiang Tang and Xiaotian Han and Qizhang Feng and Haoming Jiang and Bing Yin and Xia Hu } ,
year = { 2023 } ,
eprint = { 2304.13712 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}Berita terbaru?
- Kami menambahkan bagian penggunaan dan pembatasan.
- Kami menggunakan PowerPoint untuk memplot gambar dan merilis file sumber PPTX untuk gambar GIF kami. [4/27/2023]
- Kami merilis file sumber untuk versi Still Version, dan mengganti gambar dalam repo ini dengan versi Still. [4/29/2023]
- Tambahkan Alexatm, Unilm, UNILMV2 ke gambar, dan perbaiki logo untuk TK. [4/29/2023]
- Tambahkan Penggunaan dan Pembatasan (untuk tujuan komersial dan penelitian). Kredit untuk Dr. Du. [5/8/2023]
Panduan Praktis Lainnya untuk LLMS
- Mengapa semua reproduksi publik GPT-3 gagal? Dalam tugas apa kita harus menggunakan GPT-3.5/Chatgpt? 2023, blog
- Membangun Aplikasi LLM untuk Produksi , 2023, Blog
- Kecerdasan buatan data-sentris , 2023, repo/blog/kertas
Katalog
- Panduan Praktis untuk Model Bahasa Besar
- Panduan Praktis untuk Model
- Model Bahasa Bert-Style: Encoder-Decoder atau Encoder saja
- Model Bahasa GPT-Style: Decoder-Only
- Panduan Praktis untuk Data
- Data pretraining
- Data finetuning
- Data uji/data pengguna
- Panduan Praktis untuk Tugas NLP
- Tugas nlu tradisional
- Tugas Generasi
- Tugas-tugas intensif pengetahuan
- Kemampuan dengan penskalaan
- Tugas tertentu
- Tugas dunia nyata ''
- Efisiensi
- Kepercayaan
- Tuning Instruksi Benchmark
- Penyelarasan
- Penyelarasan keselamatan (tidak berbahaya)
- Penyelarasan Kejual (Jujur)
- Panduan praktis untuk diminta (bermanfaat)
- Upaya penyelarasan dari komuntitas open-source
- Penggunaan dan Restraksi (Model dan Data)
Panduan Praktis untuk Model
Model Bahasa Bert-Style: Encoder-Decoder atau Encoder saja
- Bert Bert: Pra-pelatihan transformator dua arah yang dalam untuk pemahaman bahasa , 2018, kertas
- Roberta Roberta: Pendekatan Pretraining Bert yang dioptimalkan dengan kuat , 2019, kertas
- Distilbert Distilbert, versi suling Bert: lebih kecil, lebih cepat, lebih murah dan lebih ringan , 2019, kertas
- Albert Albert: Lite Bert untuk pembelajaran representasi bahasa sendiri , 2019, kertas
- Unilm Model Bahasa Pra-Pelatihan untuk Pemahaman dan Generasi Bahasa Alami , Makalah 2019
- Electra Electra: Encoder teks pra-pelatihan sebagai diskriminator daripada generator , 2020, kertas
- T5 "Menjelajahi batasan pembelajaran transfer dengan transformator teks-ke-teks terpadu" . Colin Raffel et al. JMLR 2019. Kertas
- GLM "GLM-130B: Model pra-terlatih bilingual terbuka" . 2022. Kertas
- AlexatM "AlexatM 20B: Pembelajaran beberapa-shot menggunakan model Seq2seq multibahasa skala besar" . Saleh Soltan et al. Arxiv 2022. Kertas
- ST-Moe ST-Moe: Mendesain model ahli yang stabil dan dapat ditransfer . Kertas 2022
Model Bahasa GPT-Style: Decoder-Only
- GPT meningkatkan pemahaman bahasa dengan pra-pelatihan generatif . 2018. Kertas
- Model bahasa GPT-2 adalah pelajar multitask yang tidak diawasi . 2018. Kertas
- GPT-3 "Model bahasa adalah beberapa pelajar shot" . Neurips 2020. Kertas
- Opt "Opt: Buka model bahasa transformator pra-terlatih" . 2022. Kertas
- Palm "Palm: Pemodelan Bahasa Penskalaan dengan Jalur" . Aakanksha Chowdhery et al. Arxiv 2022. Kertas
- Bloom "Bloom: Model bahasa multibahasa akses terbuka 176B-parameter" . 2022. Kertas
- MT-NLG "Menggunakan Deepspeed dan Megatron untuk melatih Megatron-Turing NLG 530B, model bahasa generatif skala besar" . 2021. Kertas
- Glam "Glam: Penskalaan Efisien Model Bahasa dengan Campuran Ekseklam" . ICML 2022. Kertas
- Gopher "Model Bahasa Skala: Metode, Analisis & Wawasan dari Pelatihan Gopher" . 2021. Kertas
- Chinchilla "Model bahasa besar komputasi-optimal" . 2022. Kertas
- LAMDA "LAMDA: Model Bahasa untuk Aplikasi Dialog" . 2021. Kertas
- Llama "Llama: Model Bahasa Yayasan Terbuka dan Efisien" . 2023. Kertas
- GPT-4 "Laporan Teknis GPT-4" . 2023. Kertas
- Bloomberggpt Bloomberggpt: Model bahasa besar untuk keuangan , 2023, kertas
- GPT-NEOX-20B: "GPT-NEOX-20B: Model Bahasa Autoregresif Sumber Terbuka" . 2022. Kertas
- Palm 2: "Laporan Teknis Palm 2" . 2023. Tech.Report
- Llama 2: "Llama 2: Open Foundation dan Model Obrolan yang disetujui" . 2023. Kertas
- Claude 2: "Kartu Model dan Evaluasi untuk Model Claude" . 2023. Kartu Model
Panduan Praktis untuk Data
Data pretraining
- Redpajama , 2023. Repo
- Tumpukan: Dataset 800GB dari beragam teks untuk Pemodelan Bahasa , Arxiv 2020. Kertas
- Bagaimana tujuan pra-pelatihan mempengaruhi apa yang dipelajari oleh model bahasa besar tentang sifat linguistik? , ACL 2022. Kertas
- Penskalaan Hukum untuk Model Bahasa Saraf , 2020. Kertas
- Kecerdasan Buatan Data-sentris: Survei , 2023. Makalah
- Bagaimana GPT memperoleh kemampuannya? Menelusuri Kemampuan Muncul Model Bahasa ke Sumber Mereka , 2022. Blog
Data finetuning
- Benchmarking Zero-Shot Text Classification: Dataset, Evaluasi dan Pendekatan Persyaratan , EMNLP 2019. Paper
- Model bahasa adalah beberapa pelajar , NIPS 2020. Paper
- Apakah pembuatan data sintetis LLM membantu penambangan teks klinis? Kertas ARXIV 2023
Data uji/data pengguna
- Pembelajaran Pintasan Model Bahasa Besar dalam Pemahaman Bahasa Alami: Sebuah Survei , ARXIV 2023. Makalah
- Tentang ketahanan chatgpt: perspektif permusuhan dan di luar distribusi Arxiv, 2023. Paper
- Superglue: Benchmark yang lengket untuk sistem pemahaman bahasa tujuan umum arxiv 2019. Kertas
Panduan Praktis untuk Tugas NLP
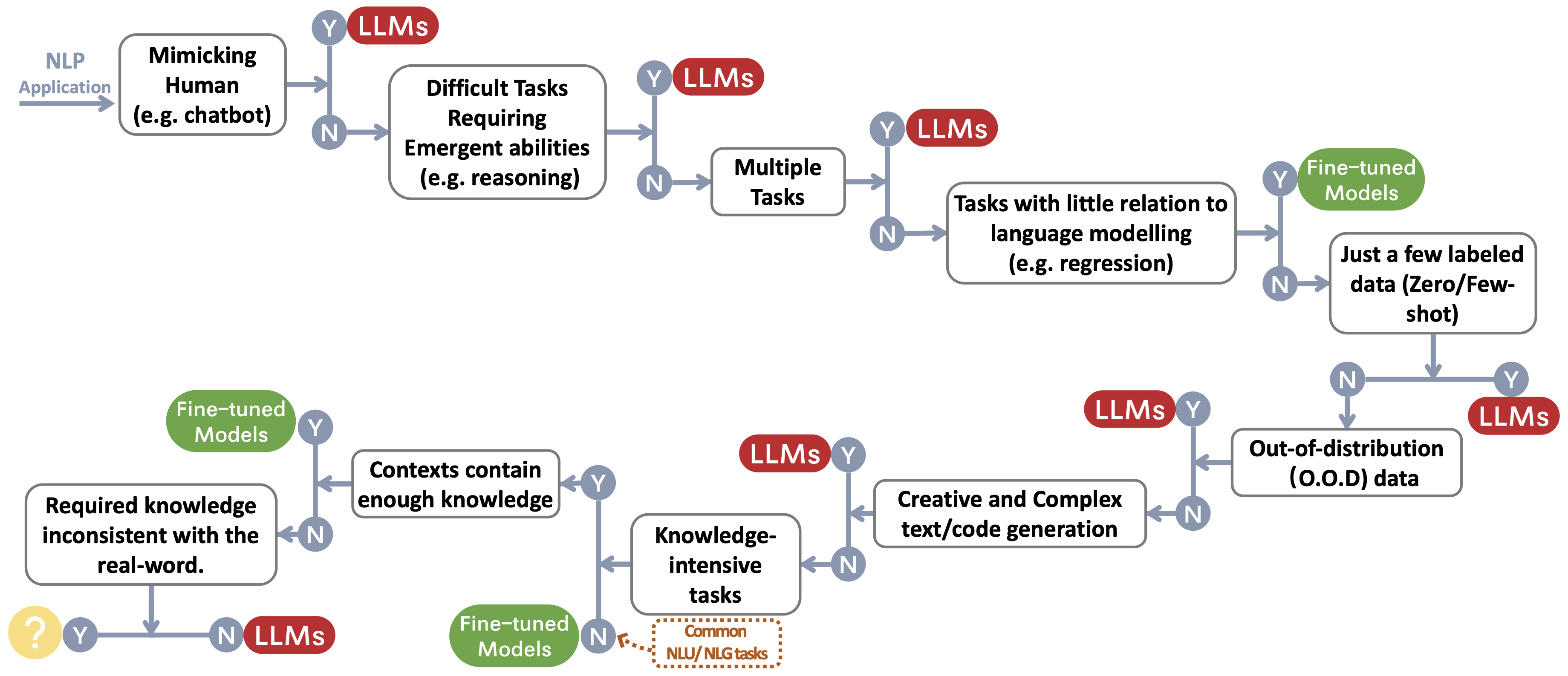
Kami membangun aliran keputusan untuk memilih LLMS atau model yang disesuaikan ~ Protect footnotemark untuk aplikasi NLP pengguna. Aliran keputusan membantu pengguna menilai apakah aplikasi NLP hilir mereka di tangan memenuhi kondisi tertentu dan, berdasarkan evaluasi itu, menentukan apakah LLM atau model yang disesuaikan adalah pilihan yang paling cocok untuk aplikasi mereka.
Tugas nlu tradisional
- Benchmark untuk Klasifikasi Komentar Beracun tentang Dataset Komentar Sipil ARXIV 2023 Makalah
- Apakah Chatgpt adalah pemecah tugas pemrosesan bahasa alami tujuan umum? Arxiv 2023paper
- Benchmarking Model Bahasa Besar Untuk Ringkasan Berita Arxiv 2022 Paper
Tugas Generasi
- Ringkasan dan Evaluasi Berita di Era Kertas GPT-3 ARXIV 2022
- Apakah chatgpt seorang penerjemah yang baik? Ya dengan GPT-4 sebagai kertas mesin arxiv 2023
- Sistem terjemahan mesin multibahasa dari Microsoft untuk Tugas Bersama WMT21 , kertas WMT2021
- Bisakah chatgpt mengerti juga? Sebuah studi perbandingan tentang chatgpt dan bertaruhannya , Arxiv 2023, kertas
Tugas-tugas intensif pengetahuan
- Mengukur Pemahaman Bahasa Multitask Masif , Makalah ICLR 2021
- Di luar permainan imitasi: mengukur dan mengekstrapolasi kemampuan model bahasa , kertas arxiv 2022
- Hadiah penskalaan terbalik , tautan 2022
- Atlas: Pembelajaran beberapa shot dengan pengambilan model bahasa augmented , makalah arxiv 2022
- Model bahasa besar menyandikan pengetahuan klinis , kertas arxiv 2022
Kemampuan dengan penskalaan
- Model bahasa besar komputasi-optimal , kertas Neurips 2022
- Penskalaan Hukum untuk Model Bahasa Saraf , Makalah ARXIV 2020
- Memecahkan masalah kata matematika dengan umpan balik berbasis proses dan hasil , makalah arxiv 2022
- Rantai pemikiran yang mendorong memunculkan penalaran dalam model bahasa besar , kertas neurips 2022
- Kemampuan Muncul Model Bahasa Besar , TMLR 2022 Paper
- Penskalaan terbalik bisa menjadi u berbentuk , kertas arxiv 2022
- Menuju penalaran dalam model bahasa besar: survei , makalah arxiv 2022
Tugas tertentu
- Gambar sebagai Bahasa Asing: Beit Pretraining Untuk Semua Tugas Visi dan Bahasa Visi , Arixv 2022 Paper
- Pali: Model Image Bahasa multibahasa berskala bersama , Kertas ARXIV 2022
- Auggpt: Memanfaatkan chatgpt untuk augmentasi data teks , makalah ARXIV 2023
- Apakah GPT-3 Annotator Data yang Baik? , Kertas arxiv 2022
- Ingin mengurangi biaya pelabelan? GPT-3 dapat membantu , EMNLP Temuan 2021 Paper
- GPT3MIX: Memanfaatkan model bahasa skala besar untuk augmentasi teks , temuan EMNLP 2021 kertas
- LLM untuk pencocokan persidangan: augmentasi data privasi-sadar terhadap kinerja dan generalisasi yang lebih baik , makalah ARXIV 2023
- Chatgpt mengungguli pekerja kerumunan untuk tugas-tugas anotasi teks , kertas arxiv 2023
- G-Eval: Evaluasi NLG Menggunakan GPT-4 dengan Penyelarasan Manusia yang Lebih Baik , Kertas ARXIV 2023
- GPTSCORE: Evaluasi sesuai keinginan Anda , makalah ARXIV 2023
- Model Bahasa Besar adalah evaluator yang canggih dengan kualitas terjemahan , makalah ARXIV 2023
- Apakah chatgpt evaluator NLG yang baik? Studi pendahuluan , makalah ARXIV 2023
Tugas dunia nyata ''
- Sparks of Artificial General Intelligence: Eksperimen Awal dengan GPT-4 , Paper ARXIV 2023
Efisiensi
- Biaya
- Model Bahasa GPT-3 Openai: Tinjauan Teknis , 2020. Posting Blog
- Mengukur intensitas karbon AI dalam kasus cloud , facct 2022. Kertas
- Di AI, apakah lebih besar selalu lebih baik? , Nature Artikel 2023. Artikel
- Model bahasa adalah beberapa pelajar shot , neurips 2020. Paper
- Harga , Openai. Posting Blog
- Latensi
- Helm: Evaluasi Holistik Model Bahasa , ARXIV 2022. Makalah
- Fine-tuning efisien parameter
- Lora: Adaptasi Rendah Model Bahasa Besar , ARXIV 2021. Kertas
- Tuning awalan: Mengoptimalkan permintaan kontinu untuk generasi , ACL 2021. Kertas
- P-Tuning: Penyetelan cepat dapat sebanding dengan penyempurnaan di seluruh skala dan tugas , ACL 2022. Kertas
- P-Tuning V2: Penyetelan cepat dapat sebanding dengan penyempurnaan secara universal di seluruh skala dan tugas , Arxiv 2022. Kertas
- Sistem pretraining
- Nol: Optimalisasi Memori Menuju Model Parameter Triliun Pelatihan , ARXIV 2019. Kertas
- Megatron-LM: Pelatihan Model Bahasa Multi-Miliar Parameter Menggunakan Model Parallelism , ARXIV 2019. Kertas
- Pelatihan model bahasa skala besar yang efisien pada kelompok GPU menggunakan Megatron-LM , ARXIV 2021. Kertas
- Mengurangi Rekomputasi Aktivasi dalam Model Transformator Besar , ARXIV 2021. Kertas
Kepercayaan
- Kekokohan dan kalibrasi
- Kalibrasi Sebelum digunakan: Meningkatkan beberapa kinerja model bahasa , ICML 2021. Kertas
- Spec: Kalibrasi berbasis prompt lunak tentang mitigasi variabilitas kinerja dalam peringkasan catatan klinis , arxiv 2023. Kertas
- Bias palsu
- Model Bahasa Besar Bisa Menjadi Pelajar Malas: Menganalisis Pintasan dalam Pembelajaran Dalam-Konteks , Temuan Kertas ACL 2023
- Pembelajaran Pintasan Model Bahasa Besar dalam Pemahaman Bahasa Alami: Survei , Makalah 2023
- Memitigasi Bias Gender dalam Sistem Keterangan , WWW 2020 Paper
- Kalibrasi Sebelum digunakan: Meningkatkan beberapa kinerja model bahasa , kertas ICML 2021
- Pembelajaran Pintasan di Jaringan Saraf Depian , Kertas Intelijen Mesin Alam 2020 Kertas
- Apakah model berbasis prompt benar-benar memahami arti dari petunjuknya? , Kertas NAACL 2022
- Masalah keselamatan
- Kartu Sistem GPT-4 , Kertas 2023
- Ilmu mendeteksi teks yang dihasilkan LLM , makalah ARXIV 2023
- Bagaimana stereotip dibagikan melalui bahasa: ulasan dan pengenalan kerangka kerja kategori aocial dan stereotip (SCSC) , ulasan penelitian komunikasi, makalah 2019
- Nuansa gender: Kesenjangan akurasi interseksional dalam klasifikasi gender komersial , kertas FACCT 2018
Tuning Instruksi Benchmark
- Flan: Model Bahasa Finetuned Adalah Peserta didik Zero-Shot , Paper Arxiv 2021
- T0: Pelatihan multitask yang diminta memungkinkan generalisasi tugas zero-shot , makalah ARXIV 2021
- Generalisasi silang melalui instruksi crowdsourcing bahasa alami , kertas ACL 2022
- TK-INSTRUCT: Super-naturalstruksi: Generalisasi melalui instruksi deklaratif pada 1600+ tugas NLP , EMNLP 2022 Paper
- Flan-T5/Palm: Model Bahasa yang Di-Instruksi Penskalaan , Kertas ARXIV 2022
- Koleksi Flan: Merancang Data dan Metode untuk Penyetelan Instruksi Efektif , Kertas ARXIV 2023
- OPT-IML: Instruksi Model Bahasa Skala Pembelajaran Meta melalui Lensa Generalisasi , Kertas ARXIV 2023
Penyelarasan
- Pembelajaran Penguatan yang mendalam dari Preferensi Manusia , Makalah NIPS 2017
- Belajar meringkas dari umpan balik manusia , kertas Arxiv 2020
- Asisten Bahasa Umum sebagai Laboratorium untuk Alignment , Makalah ARXIV 2021
- Melatih asisten yang membantu dan tidak berbahaya dengan penguatan pembelajaran dari umpan balik manusia , makalah arxiv 2022
- Mengajar model bahasa untuk mendukung jawaban dengan kutipan terverifikasi , makalah arxiv 2022
- Instruktur: Model Bahasa Pelatihan untuk mengikuti instruksi dengan umpan balik manusia , makalah ARXIV 2022
- Meningkatkan penyelarasan agen dialog melalui penilaian manusia yang ditargetkan , makalah ARXIV 2022
- Hukum Penskalaan untuk Opoptimisasi Model Hadiah , Kertas ARXIV 2022
- Pengawasan yang dapat diskalakan: Mengukur kemajuan pada pengawasan yang dapat diskalakan untuk model bahasa besar , makalah ARXIV 2022
Penyelarasan keselamatan (tidak berbahaya)
- Model Bahasa Tim Merah Dengan Model Bahasa , Kertas ARXIV 2022
- AI Konstitusi: tidak berbahaya dari umpan balik AI , makalah ARXIV 2022
- Kapasitas untuk koreksi diri moral dalam model bahasa besar , kertas arxiv 2023
- Openai: Pendekatan kami terhadap AI Safety , 2023 Blog
Penyelarasan Kejual (Jujur)
- Pembelajaran Penguatan untuk Model Bahasa , 2023 Blog
Panduan praktis untuk diminta (bermanfaat)
- Openai Cookbook . Blog
- Teknik yang cepat . Blog
- ChatGPT Prompt Engineering untuk pengembang! Kursus
Upaya penyelarasan dari komuntitas open-source
- Mandiri Mandiri: Model Bahasa Menyelaraskan dengan Instruksi yang Dibuat sendiri , Kertas ARXIV 2022
- Alpaca . Repo
- Vicuna . Repo
- Dolly . Blog
- DEEK-CHAT DEEP . Blog
- Gpt4all . Repo
- OpenAssitan . Repo
- Chatglm . Repo
- Lumut . Repo
- Lamini . Repo/blog
Penggunaan dan pembatasan
Kami membangun tabel yang merangkum pembatasan penggunaan LLMS (misalnya untuk tujuan komersial dan penelitian). Secara khusus, kami memberikan informasi dari model dan perspektif data pretraining mereka. Kami mendesak pengguna di masyarakat untuk merujuk pada informasi lisensi untuk model dan data publik dan menggunakannya secara bertanggung jawab. Kami mendesak para pengembang untuk memberikan perhatian khusus pada lisensi, menjadikannya transparan dan komprehensif, untuk mencegah penggunaan yang tidak diinginkan dan tidak terduga.
| Llms | Model | Data |
|---|
| Lisensi | Penggunaan komersial | Pembatasan lain yang terkenal | Lisensi | Corpus |
| Encoder-only |
|
| Bert Seri Model (Domain Umum) | Apache 2.0 | ✅ | | Publik | Bookscorpus, Wikipedia Inggris |
| Roberta | Lisensi MIT | ✅ | | Publik | BookCorpus, CC-News, OpenWebtext, Stories |
| Ernie | Apache 2.0 | ✅ | | Publik | Wikipedia Inggris |
| Scibert | Apache 2.0 | ✅ | | Publik | Bert Corpus, 1,14 juta makalah dari Semantic Scholar |
| Legalbert | CC BY-SA 4.0 | | | Publik (kecuali data dari proyek akses hukum kasus) | Legislasi UE, kasus pengadilan AS, dll. |
| Biobert | Apache 2.0 | ✅ | | PubMed | PubMed, PMC |
| Encoder-Decoder |
|
| T5 | Apache 2.0 | ✅ | | Publik | C4 |
| Flan-T5 | Apache 2.0 | ✅ | | Publik | C4, campuran tugas (Gambar 2 dalam kertas) |
| Bart | Apache 2.0 | ✅ | | Publik | Roberta Corpus |
| Glm | Apache 2.0 | ✅ | | Publik | Bookscorpus dan Wikipedia Inggris |
| Chatglm | Lisensi Chatglm | | Tidak ada gunanya untuk tujuan ilegal atau penelitian militer, tidak ada salahnya kepentingan publik masyarakat | N/a | Token 1t dari korpus Cina dan Inggris |
| Hanya decoder |
| Gpt2 | Lisensi MIT yang dimodifikasi | ✅ | Gunakan GPT-2 secara bertanggung jawab dan jelas menunjukkan konten Anda telah dibuat menggunakan GPT-2. | Publik | Webtext |
| GPT-NEO | Lisensi MIT | ✅ | | Publik | Tumpukan |
| Gpt-j | Apache 2.0 | ✅ | | Publik | Tumpukan |
| ---> Dolly | CC oleh NC 4.0 | | | CC oleh NC 4.0, tunduk pada ketentuan penggunaan data yang dihasilkan oleh OpenAI | Tumpukan, instruksi sendiri |
| ---> gpt4all-j | Apache 2.0 | ✅ | | Publik | Dataset GPT4ALL-J |
| Pythia | Apache 2.0 | ✅ | | Publik | Tumpukan |
| ---> Dolly v2 | Lisensi MIT | ✅ | | Publik | Pile, Databricks-Dolly-15k |
| MEMILIH | Perjanjian Lisensi OPT-175B | | Tidak ada pembangunan yang berkaitan dengan penelitian pengawasan dan militer, tidak ada salahnya kepentingan publik masyarakat | Publik | Roberta Corpus, The Pile, Pushshift.io Reddit |
| ---> opt-iml | Perjanjian Lisensi OPT-175B | | sama untuk memilih | Publik | Opt corpus, versi diperpanjang dari super-naturalinstructions |
| Yalm | Apache 2.0 | ✅ | | Tidak ditentukan | Tumpukan, tim mengumpulkan teks dalam bahasa Rusia |
| BUNGA | Lisensi kereta api besar | ✅ | Tidak menggunakan informasi yang salah dengan tujuan menyakiti orang lain;
konten tanpa secara tegas menyangkal bahwa teks tersebut dihasilkan mesin | Publik | Roots Corpus (Lauren¸con et al., 2022) |
| ---> Bloomz | Lisensi kereta api besar | ✅ | sama dengan mekar | Publik | Roots Corpus, XP3 |
| Galactica | CC BY-NC 4.0 | | | N/a | Galactica Corpus |
| Llama | Lisensi Bespoke Non-Komersial | | Tidak ada pembangunan yang berkaitan dengan penelitian pengawasan dan militer, tidak ada salahnya kepentingan publik masyarakat | Publik | CommonCrawl, C4, GitHub, Wikipedia, dll. |
| ---> alpaca | CC oleh NC 4.0 | | | CC oleh NC 4.0, tunduk pada ketentuan penggunaan data yang dihasilkan oleh OpenAI | Llama corpus, instruktur mandiri |
| ---> Vicuna | CC oleh NC 4.0 | | | Tunduk pada ketentuan penggunaan data yang dihasilkan oleh OpenAI;
Praktik Privasi Sharegpt | Llama Corpus, percakapan 70k dari Sharegpt.com |
| ---> gpt4all | Llama berlisensi GPL | | | Publik | Dataset GPT4All |
| Openllama | Apache 2.0 | ✅ | | Publik | Redpajama |
| Codegeex | Lisensi codegeex | | Tidak ada gunanya untuk tujuan ilegal atau penelitian militer | Publik | Tumpukan, codeparrot, dll. |
| Starcoder | Lisensi BigCode OpenRail-M V1 | ✅ | Tidak menggunakan informasi yang salah dengan tujuan menyakiti orang lain;
konten tanpa secara tegas menyangkal bahwa teks tersebut dihasilkan mesin | Publik | Tumpukannya |
| MPT-7B | Apache 2.0 | ✅ | | Publik | MC4 (Bahasa Inggris), The Stack, Redpajama, S2orc |
| elang | Lisensi llm tii falcon | ✅/ | Tersedia di bawah lisensi yang memungkinkan penggunaan komersial | Publik | RefinedWeb |
Sejarah Bintang


