คู่มือที่ใช้งานได้จริงสำหรับแบบจำลองภาษาขนาดใหญ่
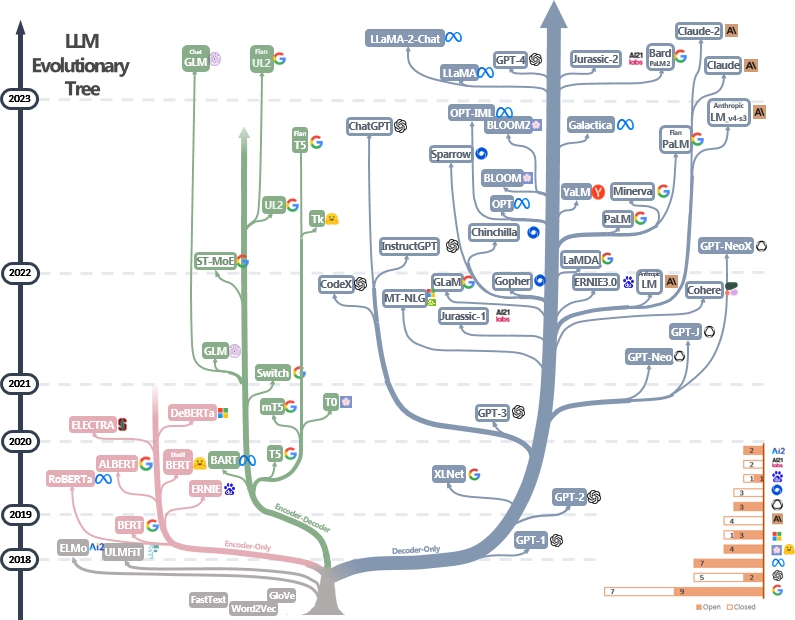
รายการที่ดูแล (ยังคงอัปเดตอย่างแข็งขัน) ของแหล่งข้อมูลคู่มือการปฏิบัติของ LLMS มันขึ้นอยู่กับรายงานการสำรวจของเรา: การควบคุมพลังของ LLM ในทางปฏิบัติ: การสำรวจเกี่ยวกับ chatgpt และอื่น ๆ และความพยายามจาก @xinyadu การสำรวจบางส่วนขึ้นอยู่กับช่วงครึ่งหลังของบล็อกนี้ นอกจากนี้เรายังสร้างต้นไม้วิวัฒนาการของแบบจำลองภาษาขนาดใหญ่ที่ทันสมัย (LLMS) เพื่อติดตามการพัฒนาแบบจำลองภาษาในช่วงไม่กี่ปีที่ผ่านมาและเน้นโมเดลที่รู้จักกันดีที่สุด
แหล่งข้อมูลเหล่านี้มีจุดมุ่งหมายเพื่อช่วยให้ผู้ปฏิบัติงานนำทางภูมิทัศน์อันกว้างใหญ่ของแบบจำลองภาษาขนาดใหญ่ (LLMS) และแอปพลิเคชันในการประมวลผลภาษาธรรมชาติ (NLP) นอกจากนี้เรายังรวมถึงข้อ จำกัด การใช้งานตามข้อมูลแบบจำลองและข้อมูลการออกใบอนุญาตข้อมูล หากคุณพบแหล่งข้อมูลใด ๆ ในที่เก็บของเรามีประโยชน์โปรดใช้มัน (อย่าลืมอ้างอิงกระดาษของเรา!?) เรายินดีต้อนรับคำขอดึงเพื่อปรับแต่งตัวเลขนี้!
@article { yang2023harnessing ,
title = { Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond } ,
author = { Jingfeng Yang and Hongye Jin and Ruixiang Tang and Xiaotian Han and Qizhang Feng and Haoming Jiang and Bing Yin and Xia Hu } ,
year = { 2023 } ,
eprint = { 2304.13712 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}ข่าวล่าสุด?
- เราเพิ่มส่วนการใช้งานและข้อ จำกัด
- เราใช้ PowerPoint เพื่อพล็อตรูปและปล่อยไฟล์ต้นฉบับ PPTX สำหรับรูป GIF ของเรา [4/27/2023]
- เราเปิดตัวไฟล์ต้นฉบับสำหรับเวอร์ชัน PPTX และแทนที่ตัวเลขใน repo นี้ด้วยเวอร์ชัน Still [4/29/2023]
- เพิ่ม Alexatm, unilm, unilmv2 ลงในรูปและแก้ไขโลโก้สำหรับ TK [4/29/2023]
- เพิ่มการใช้งานและข้อ จำกัด (เพื่อวัตถุประสงค์เชิงพาณิชย์และการวิจัย) เครดิตถึงดร. ดู [5/8/2023]
คู่มือปฏิบัติอื่น ๆ สำหรับ LLMS
- เหตุใดการทำซ้ำสาธารณะของ GPT-3 จึงล้มเหลว? เราควรใช้ GPT-3.5/chatgpt ในงานใด 2023 บล็อก
- การสร้างแอปพลิเคชัน LLM สำหรับการผลิต ปี 2023 บล็อก
- ปัญญาประดิษฐ์ที่เน้นข้อมูลเป็นศูนย์กลาง , 2023, repo/blog/paper
แคตตาล็อก
- คู่มือที่ใช้งานได้จริงสำหรับแบบจำลองภาษาขนาดใหญ่
- คู่มือปฏิบัติสำหรับแบบจำลอง
- รูปแบบภาษาสไตล์ Bert: encoder-decoder หรือ encoder-only
- รูปแบบภาษาสไตล์ GPT: ตัวถอดรหัสเท่านั้น
- คู่มือการปฏิบัติสำหรับข้อมูล
- ข้อมูลการเตรียมการ
- ข้อมูล Finetuning
- ทดสอบข้อมูล/ข้อมูลผู้ใช้
- คู่มือปฏิบัติสำหรับงาน NLP
- งาน NLU แบบดั้งเดิม
- งานรุ่น
- งานที่ต้องใช้ความรู้
- ความสามารถในการปรับขนาด
- งานเฉพาะ
- งานจริง '' งาน ''
- ประสิทธิภาพ
- ความน่าเชื่อถือ
- การปรับแต่งคำแนะนำมาตรฐาน
- การจัดตำแหน่ง
- การจัดแนวความปลอดภัย (ไม่เป็นอันตราย)
- การจัดแนวความจริง (ซื่อสัตย์)
- คู่มือปฏิบัติสำหรับการแจ้งเตือน (เป็นประโยชน์)
- ความพยายามในการจัดตำแหน่งของชุมชนโอเพ่นซอร์ส
- การใช้งานและการ จำกัด (แบบจำลองและข้อมูล)
คู่มือปฏิบัติสำหรับแบบจำลอง
รูปแบบภาษาสไตล์ Bert: encoder-decoder หรือ encoder-only
- เบิร์ ตเบิร์ต: การฝึกอบรมหม้อแปลงสองทิศทางลึกเพื่อความเข้าใจภาษา , 2018, กระดาษ
- Roberta Roberta: วิธีการฝึกอบรมเบิร์ตที่ได้รับการปรับปรุงอย่างดี , 2019, กระดาษ
- Distilbert Distilbert, Bert รุ่นกลั่น: เล็ก, เร็วกว่า, ราคาถูกและเบา , 2019, กระดาษ
- อัลเบิร์ ตอัลเบิร์ต: Lite Bert สำหรับการเรียนรู้ด้วยตนเองเกี่ยวกับการเป็นตัวแทนภาษา , 2019, Paper
- Unilm Unified Language Model Pre-Training สำหรับการทำความเข้าใจภาษาธรรมชาติและการสร้าง , 2019 Paper
- Electra Electra: การเข้ารหัสข้อความก่อนการฝึกฝนเป็นตัวเลือกจำเพาะมากกว่าเครื่องกำเนิดไฟฟ้า , 2020, กระดาษ
- T5 "สำรวจขีด จำกัด ของการเรียนรู้การถ่ายโอนด้วยหม้อแปลงข้อความเป็นแบบรวมเป็นข้อความ" Colin Raffel และคณะ JMLR 2019. กระดาษ
- GLM "GLM-130B: แบบเปิดสองภาษาแบบเปิดสองภาษา" 2022. กระดาษ
- Alexatm "Alexatm 20b: การเรียนรู้ไม่กี่นัดโดยใช้โมเดล SEQ2Seq หลายภาษาขนาดใหญ่" Saleh Soltan และคณะ Arxiv 2022. กระดาษ
- ST-MOE ST-MOE: การออกแบบโมเดลผู้เชี่ยวชาญที่มีความเสถียรและสามารถถ่ายโอนได้ กระดาษ 2022
รูปแบบภาษาสไตล์ GPT: ตัวถอดรหัสเท่านั้น
- GPT ปรับปรุงการทำความเข้าใจภาษาโดยการฝึกอบรมก่อนกำเนิด 2018. กระดาษ
- แบบจำลองภาษา GPT-2 เป็นผู้เรียนมัลติทาสก์ที่ไม่ได้รับการดูแล 2018. กระดาษ
- GPT-3 "โมเดลภาษาเป็นผู้เรียนไม่กี่คน" Neurips 2020. กระดาษ
- opt "opt: เปิดโมเดลภาษาหม้อแปลงที่ผ่านการฝึกอบรมล่วงหน้า" 2022. กระดาษ
- ปาล์ม "ปาล์ม: การปรับแต่งภาษาแบบปรับขนาดด้วยเส้นทาง" Aakanksha Chowdhery และคณะ Arxiv 2022. กระดาษ
- Bloom "Bloom: รูปแบบภาษาหลายภาษาแบบเปิดกว้าง 176b-parameter" 2022. กระดาษ
- mt-nlg "ใช้ Deepspeed และ Megatron เพื่อฝึกอบรม Megatron-Turing NLG 530B ซึ่งเป็นรูปแบบภาษาที่มีขนาดใหญ่" 2021. กระดาษ
- Glam "Glam: การปรับขนาดของแบบจำลองภาษาที่มีประสิทธิภาพด้วยส่วนผสมของ experts" ICML 2022. กระดาษ
- Gopher "แบบจำลองการปรับขนาดภาษา: วิธีการวิเคราะห์และข้อมูลเชิงลึกจากการฝึกอบรม Gopher" 2021. กระดาษ
- Chinchilla "การฝึกอบรมแบบจำลองภาษาขนาดใหญ่ที่ดีที่สุด" 2022. กระดาษ
- Lamda "Lamda: รุ่นภาษาสำหรับแอปพลิเคชันโต้ตอบ" 2021. กระดาษ
- Llama "Llama: แบบเปิดและเปิดกว้างและมีประสิทธิภาพ" 2023. กระดาษ
- GPT-4 "รายงานทางเทคนิค GPT-4" 2023. กระดาษ
- Bloomberggpt Bloomberggpt: รูปแบบภาษาขนาดใหญ่สำหรับการเงิน , 2023, กระดาษ
- GPT-NEOX-20B: "GPT-NEOX-20B: โมเดลภาษาแบบออโต้เทอร์ริติกโอเพนซอร์ซ" 2022. กระดาษ
- ปาล์ม 2: "รายงานทางเทคนิค Palm 2" 2023. Tech.Report
- Llama 2: "Llama 2: Open Foundation และ Models Chat ที่ปรับแต่งได้อย่างละเอียด" 2023. กระดาษ
- Claude 2: "Model Card และการประเมินผลสำหรับ Claude Models" 2023. การ์ดรุ่น
คู่มือการปฏิบัติสำหรับข้อมูล
ข้อมูลการเตรียมการ
- Redpajama , 2023. repo
- The Pile: ชุดข้อมูล 800GB ของข้อความที่หลากหลายสำหรับการสร้างแบบจำลองภาษา Arxiv 2020
- วัตถุประสงค์การฝึกอบรมก่อนการฝึกอบรมมีผลต่อแบบจำลองภาษาขนาดใหญ่ที่เรียนรู้เกี่ยวกับคุณสมบัติทางภาษาอย่างไร , ACL 2022. กระดาษ
- การปรับขนาดกฎหมายสำหรับแบบจำลองภาษาประสาท , 2020. กระดาษ
- ปัญญาประดิษฐ์ที่เน้นข้อมูลเป็นศูนย์กลาง: การสำรวจ , 2023. กระดาษ
- GPT ได้รับความสามารถอย่างไร? การติดตามความสามารถฉุกเฉินของแบบจำลองภาษาไปยังแหล่งที่มาของพวกเขา 2022 บล็อก
ข้อมูล Finetuning
- การจำแนกประเภทการจำแนกประเภทการจำแนกข้อความเป็นศูนย์: ชุดข้อมูลการประเมินผลและวิธีการ entailment , EMNLP 2019.
- โมเดลภาษาเป็นผู้เรียนไม่กี่คน , NIPS 2020. กระดาษ
- การสร้างข้อมูลสังเคราะห์ของ LLMS ช่วยในการขุดข้อความทางคลินิกหรือไม่? กระดาษอาร์กซ์ 2023
ทดสอบข้อมูล/ข้อมูลผู้ใช้
- การเรียนรู้ทางลัดของแบบจำลองภาษาขนาดใหญ่ในการทำความเข้าใจภาษาธรรมชาติ: การสำรวจ , arxiv 2023. กระดาษ
- เกี่ยวกับความทนทานของ CHATGPT: มุมมองที่เป็นปฏิปักษ์และการแจกจ่าย
- Superglue: มาตรฐานที่ติดอยู่สำหรับระบบทำความเข้าใจภาษาที่มีวัตถุประสงค์ทั่วไป Arxiv 2019. กระดาษ
คู่มือปฏิบัติสำหรับงาน NLP
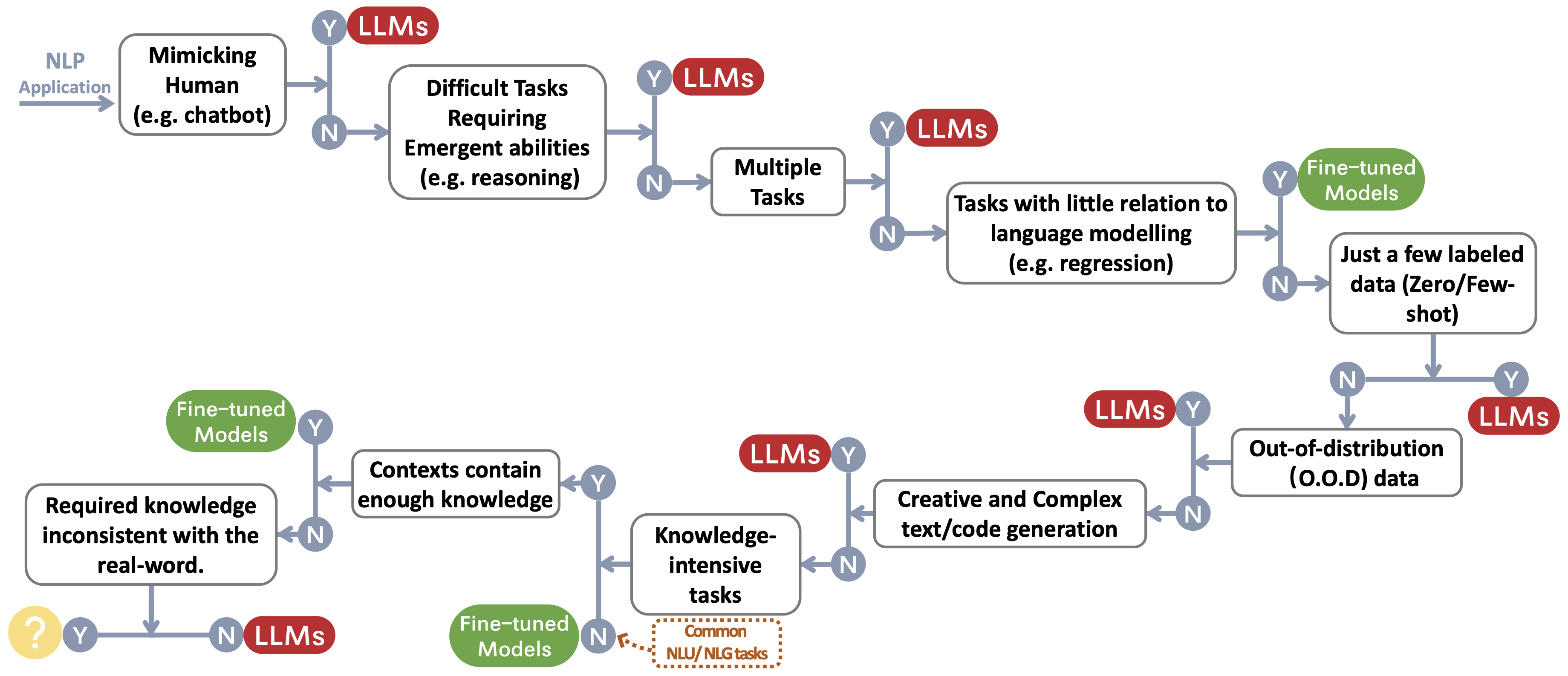
เราสร้างโฟลว์การตัดสินใจสำหรับการเลือก LLMS หรือแบบจำลองที่ปรับแต่ง ~ Protect Footnotemark สำหรับแอปพลิเคชัน NLP ของผู้ใช้ โฟลว์การตัดสินใจช่วยให้ผู้ใช้ประเมินว่าแอปพลิเคชัน NLP ดาวน์สตรีมของพวกเขาอยู่ในมือตรงกับเงื่อนไขเฉพาะและขึ้นอยู่กับการประเมินนั้นตรวจสอบว่า LLM หรือแบบจำลองที่ปรับแต่งเป็นตัวเลือกที่เหมาะสมที่สุดสำหรับแอปพลิเคชันของพวกเขา
งาน NLU แบบดั้งเดิม
- มาตรฐานสำหรับการจำแนกความคิดเห็นที่เป็นพิษในชุดข้อมูลความคิดเห็นทางแพ่ง Arxiv 2023 Paper
- chatgpt เป็นงานการประมวลผลภาษาธรรมชาติที่มีวัตถุประสงค์ทั่วไปหรือไม่? arxiv 2023paper
- การเปรียบเทียบแบบจำลองภาษาขนาดใหญ่สำหรับการสรุปข่าว Arxiv 2022 Paper
งานรุ่น
- การสรุปข่าวและการประเมินผลในยุคของกระดาษ GPT-3 arxiv 2022
- CHATGPT เป็นนักแปลที่ดีหรือไม่? ใช่ด้วย GPT-4 เป็นกระดาษเครื่องยนต์ Arxiv 2023
- ระบบการแปลเครื่องหลายภาษาจาก Microsoft สำหรับงานที่ใช้ร่วมกันของ WMT21 , WMT2021 Paper
- CHATGPT สามารถเข้าใจได้หรือไม่? การศึกษาเปรียบเทียบเกี่ยวกับ chatgpt และ bert ที่ปรับแต่ง , arxiv 2023, กระดาษ
งานที่ต้องใช้ความรู้
- การวัดความเข้าใจภาษามัลติทาสก์ขนาดใหญ่ ICLR 2021 Paper
- นอกเหนือจากเกมเลียนแบบ: การหาปริมาณและการคาดการณ์ความสามารถของโมเดลภาษา ARXIV 2022 PAPER
- รางวัลผกผันสเกลลิงก์ 2022 ลิงค์
- Atlas: การเรียนรู้ไม่กี่นัดด้วยโมเดลภาษาที่เพิ่มขึ้น
- แบบจำลองภาษาขนาดใหญ่เข้ารหัสความรู้ทางคลินิก , กระดาษ Arxiv 2022
ความสามารถในการปรับขนาด
- การฝึกอบรมแบบจำลองภาษาขนาดใหญ่ที่ดีที่สุด , Neurips 2022 Paper
- การปรับขนาดกฎหมายสำหรับแบบจำลองภาษาประสาท , กระดาษ Arxiv 2020
- การแก้ปัญหาคำศัพท์ทางคณิตศาสตร์ด้วยการตอบกลับกระบวนการและตามผลลัพธ์ , กระดาษ Arxiv 2022
- ห่วงโซ่แห่งความคิดกระตุ้นให้เกิดการให้เหตุผลในแบบจำลองภาษาขนาดใหญ่ Neurips 2022 Paper
- ความสามารถฉุกเฉินของแบบจำลองภาษาขนาดใหญ่ TMLR 2022 Paper
- การปรับขนาดผกผันอาจกลายเป็นรูปตัวยู , กระดาษ Arxiv 2022
- สู่การให้เหตุผลในรูปแบบภาษาขนาดใหญ่: การสำรวจ , กระดาษ Arxiv 2022
งานเฉพาะ
- ภาพเป็นภาษาต่างประเทศ: Beit pretraining สำหรับงานวิสัยทัศน์และการมองเห็นทั้งหมด , กระดาษ Arixv 2022
- PALI: รูปแบบภาพหลายภาษาหลายภาษาร่วมกัน , กระดาษ ArxIV 2022
- Auggpt: ใช้ประโยชน์จากการใช้งาน chatgpt สำหรับการเพิ่มข้อมูลข้อความ , กระดาษ Arxiv 2023
- GPT-3 เป็นคำอธิบายประกอบข้อมูลที่ดีหรือไม่? , กระดาษ Arxiv 2022
- ต้องการลดต้นทุนการติดฉลากหรือไม่? GPT-3 สามารถช่วยได้ การค้นพบ EMNLP 2021 กระดาษ
- GPT3MIX: การใช้ประโยชน์จากแบบจำลองภาษาขนาดใหญ่สำหรับการเพิ่มข้อความการค้น พบ EMNLP 2021 PAPER
- LLM สำหรับการจับคู่ผู้ป่วย-การพิจารณา
- chatgpt มีประสิทธิภาพสูงกว่าคนงานฝูงชนสำหรับงานเขียนคำอธิบายประกอบข้อความ , กระดาษ Arxiv 2023
- G-EVAL: การประเมิน NLG โดยใช้ GPT-4 กับการจัดตำแหน่งของมนุษย์ที่ดีขึ้น , กระดาษ Arxiv 2023
- GPTSCORE: ประเมินตามที่คุณต้องการ กระดาษ Arxiv 2023
- แบบจำลองภาษาขนาดใหญ่เป็นตัวประเมินคุณภาพที่ทันสมัยของคุณภาพการแปล , กระดาษ Arxiv 2023
- CHATGPT เป็นผู้ประเมิน NLG ที่ดีหรือไม่? การศึกษาเบื้องต้น กระดาษ Arxiv 2023
งานจริง '' งาน ''
- ประกายไฟแห่งข่าวกรองทั่วไปประดิษฐ์: การทดลองในช่วงต้นด้วย GPT-4 , Arxiv 2023 Paper
ประสิทธิภาพ
- ค่าใช้จ่าย
- โมเดลภาษา GPT-3 ของ Openai: ภาพรวมทางเทคนิค , 2020. บล็อกโพสต์
- การวัดความเข้มของคาร์บอนของ AI ในอินสแตนซ์ของคลาวด์ FACCT 2022
- ใน AI ใหญ่กว่าเสมอหรือไม่? , บทความธรรมชาติ 2023. บทความ
- แบบจำลองภาษาเป็นผู้เรียนไม่กี่คนที่มีการถ่าย ภาพ Neurips 2020
- ราคา Openai โพสต์บล็อก
- ความหน่วงแฝง
- Helm: การประเมินแบบองค์รวมของแบบจำลองภาษา , arxiv 2022. กระดาษ
- การปรับแต่งพารามิเตอร์อย่างละเอียด
- LORA: การปรับระดับต่ำของแบบจำลองภาษาขนาดใหญ่ Arxiv 2021. กระดาษ
- คำนำหน้าการปรับแต่ง: การเพิ่มประสิทธิภาพการแจ้งเตือนอย่างต่อเนื่องสำหรับการสร้าง , ACL 2021. กระดาษ
- P-tuning: การปรับแต่งพร้อมกันสามารถเทียบได้กับการปรับแต่งผ่านเครื่องชั่งและงาน ACL 2022
- P-tuning V2: การปรับแต่งพร้อมใช้งานสามารถเทียบได้กับการปรับแต่งอย่างละเอียดทั่วทั้งเครื่องชั่งและงาน Arxiv 2022
- ระบบการผ่าตัดก่อน
- ศูนย์: การเพิ่มประสิทธิภาพหน่วยความจำไปสู่การฝึกอบรมแบบจำลองพารามิเตอร์ล้านล้าน , Arxiv 2019. กระดาษ
- MEGATRON-LM: การฝึกอบรมแบบจำลองภาษาพารามิเตอร์หลายพันล้านแบบใช้โมเดลคู่ขนาน , ARXIV 2019.
- การฝึกแบบจำลองภาษาขนาดใหญ่ที่มีประสิทธิภาพในกลุ่ม GPU โดยใช้ Megatron-LM , Arxiv 2021
- การลดการเปิดใช้งานการเปิดใช้งานในแบบจำลองหม้อแปลงขนาดใหญ่ Arxiv 2021
ความน่าเชื่อถือ
- ความทนทานและการสอบเทียบ
- ปรับเทียบก่อนการใช้
- ข้อมูล จำเพาะ: การสอบเทียบตามพรอมต์ที่อ่อนนุ่มในการบรรเทาความแปรปรวนของประสิทธิภาพในการสรุปบันทึกทางคลินิก , ARXIV 2023.
- อคติปลอม
- แบบจำลองภาษาขนาดใหญ่อาจเป็นผู้เรียนที่ขี้เกียจ: วิเคราะห์ทางลัดในการเรียนรู้ในบริบท การค้นพบของ ACL 2023 Paper
- การเรียนรู้ทางลัดของแบบจำลองภาษาขนาดใหญ่ในการทำความเข้าใจภาษาธรรมชาติ: การสำรวจ , กระดาษ 2023
- บรรเทาอคติทางเพศในระบบคำบรรยายภาพ , กระดาษ www 2020
- ปรับเทียบก่อนการใช้
- การเรียนรู้ทางลัดในเครือข่ายประสาทลึก , Nature Machine Intelligence 2020 Paper
- โมเดลที่มีพื้นฐานมาจากการพร้อมที่จะเข้าใจความหมายของพรอมต์ของพวกเขาหรือไม่? , NAACL 2022 PAPER
- ปัญหาด้านความปลอดภัย
- การ์ดระบบ GPT-4 , 2023 Paper
- วิทยาศาสตร์การตรวจจับข้อความที่สร้างขึ้น LLM , กระดาษ Arxiv 2023
- วิธีการแบ่งปันแบบแผนผ่านภาษา: การทบทวนและการแนะนำของหมวดหมู่ Aocial และกรอบการสื่อสารแบบแผน (SCSC) , การทบทวนการวิจัยการสื่อสาร, 2019 Paper
- เฉดสีของเพศ: ความไม่เท่าเทียมกันของความแม่นยำในการจำแนกเพศเชิงพาณิชย์ , กระดาษ FACCT 2018
การปรับแต่งคำแนะนำมาตรฐาน
- Flan: โมเดลภาษา Finetuned เป็นผู้เรียนที่ไม่มีการยิง , Arxiv 2021 Paper
- T0: การฝึกอบรมมัลติทาสก์ช่วยให้การฝึกอบรมแบบไม่มีการยิงแบบไม่มีการยิง , กระดาษ Arxiv 2021
- การวางนัยทั่วไปข้ามงานผ่านคำแนะนำการระดมทุนภาษาธรรมชาติ ACL 2022 Paper
- TK-Instruct: Super-NaturalInstructions: การวางนัยทั่วไปผ่านคำแนะนำที่เปิดเผยเกี่ยวกับงาน 1600+ NLP , EMNLP 2022 Paper
- FLAN-T5/PALM: การปรับขนาดภาษาแบบจำลองภาษา -ฟินา
- The Flan Collection: การออกแบบข้อมูลและวิธีการสำหรับการปรับแต่งการเรียนการสอนที่มีประสิทธิภาพ , กระดาษ Arxiv 2023
- opt-iml: การปรับขนาดภาษาการเรียนการสอนการเรียนรู้การเรียนรู้ผ่านเลนส์ของการวางนัยทั่วไป , กระดาษ Arxiv 2023
การจัดตำแหน่ง
- การเรียนรู้การเสริมแรงอย่างลึกล้ำจากการตั้งค่าของมนุษย์ กระดาษ NIPS 2017
- เรียนรู้ที่จะสรุปจากข้อเสนอแนะของมนุษย์ กระดาษ Arxiv 2020
- ผู้ช่วยภาษาทั่วไปเป็นห้องปฏิบัติการสำหรับการจัดตำแหน่ง กระดาษ Arxiv 2021
- การฝึกอบรมผู้ช่วยที่เป็นประโยชน์และไม่เป็นอันตรายด้วยการเรียนรู้การเสริมแรงจากข้อเสนอแนะของมนุษย์ กระดาษ Arxiv 2022
- แบบจำลองภาษาการสอนเพื่อสนับสนุนคำตอบด้วยคำพูดที่ได้รับการตรวจสอบแล้ว กระดาษ Arxiv 2022
- InstructGPT: แบบจำลองภาษาการฝึกอบรมเพื่อทำตามคำแนะนำเกี่ยวกับข้อเสนอแนะของมนุษย์ Arxiv 2022 Paper
- การปรับปรุงการจัดตำแหน่งตัวแทนการสนทนาผ่านการตัดสินของมนุษย์ที่กำหนดเป้าหมาย กระดาษ Arxiv 2022
- การปรับขนาดกฎหมายสำหรับแบบจำลองการให้รางวัล opoptimization , Arxiv 2022 Paper
- การกำกับดูแลที่ปรับขนาดได้: การวัดความคืบหน้าในการกำกับดูแลที่ปรับขนาดได้สำหรับโมเดลภาษาขนาดใหญ่ , กระดาษ Arxiv 2022
การจัดแนวความปลอดภัย (ไม่เป็นอันตราย)
- รูปแบบภาษาที่เป็นทีมสีแดงพร้อมรูปแบบภาษา , กระดาษ Arxiv 2022
- AI รัฐธรรมนูญ: ความไม่เป็นอันตรายจากข้อเสนอแนะ AI , กระดาษ Arxiv 2022
- ความสามารถในการแก้ไขตนเองทางศีลธรรมในรูปแบบภาษาขนาดใหญ่ กระดาษ Arxiv 2023
- Openai: แนวทางของเราเพื่อความปลอดภัย AI , 2023 บล็อก
การจัดแนวความจริง (ซื่อสัตย์)
- การเรียนรู้การเสริมแรงสำหรับแบบจำลองภาษา 2023 บล็อก
คู่มือปฏิบัติสำหรับการแจ้งเตือน (เป็นประโยชน์)
- Openai Cookbook บล็อก
- วิศวกรรมที่รวดเร็ว บล็อก
- CHATGPT วิศวกรรมพรอมต์สำหรับนักพัฒนา! คอร์ส
ความพยายามในการจัดตำแหน่งของชุมชนโอเพ่นซอร์ส
- Instruct ตัวเอง: จัดแนวแบบจำลองภาษากับคำแนะนำที่สร้างขึ้นด้วยตนเอง , กระดาษ Arxiv 2022
- Alpaca repo
- Vicuna repo
- ดอลลี่ บล็อก
- Deepspeed-Chat บล็อก
- GPT4ALL repo
- Openassitant repo
- chatglm repo
- มอส repo
- Lamini repo/blog
การใช้งานและข้อ จำกัด
เราสร้างตารางสรุปข้อ จำกัด การใช้งาน LLMS (เช่นเพื่อวัตถุประสงค์ทางการค้าและการวิจัย) โดยเฉพาะอย่างยิ่งเราให้ข้อมูลจากแบบจำลองและมุมมองของข้อมูลการเตรียมการของพวกเขา เราขอเรียกร้องให้ผู้ใช้ในชุมชนอ้างถึงข้อมูลการออกใบอนุญาตสำหรับแบบจำลองสาธารณะและข้อมูลและใช้พวกเขาอย่างรับผิดชอบ เราขอแนะนำให้นักพัฒนาให้ความสนใจเป็นพิเศษกับการออกใบอนุญาตทำให้พวกเขาโปร่งใสและครอบคลุมเพื่อป้องกันการใช้งานที่ไม่พึงประสงค์และไม่คาดฝัน
| LLMS | แบบอย่าง | ข้อมูล |
|---|
| ใบอนุญาต | การใช้งานเชิงพาณิชย์ | ข้อ จำกัด ที่น่าสังเกตอื่น ๆ | ใบอนุญาต | คอร์ปัส |
| เข้ารหัสอย่างเดียว |
|
| Bert Series ของโมเดล (โดเมนทั่วไป) | Apache 2.0 | | | สาธารณะ | Bookscorpus, ภาษาอังกฤษ Wikipedia |
| โรเบอร์ต้า | ใบอนุญาต MIT | | | สาธารณะ | Bookcorpus, CC-News, OpenWebText, Stories |
| เออร์นี่ | Apache 2.0 | | | สาธารณะ | วิกิพีเดียภาษาอังกฤษ |
| รูปปั้น | Apache 2.0 | | | สาธารณะ | Bert Corpus, 1.14m เอกสารจาก Semantic Scholar |
| legalbert | CC BY-SA 4.0 | | | สาธารณะ (ยกเว้นข้อมูลจากโครงการเข้าถึงกฎหมายกรณี) | กฎหมายของสหภาพยุโรปคดีศาลของสหรัฐอเมริกา ฯลฯ |
| นักชีวภาพ | Apache 2.0 | | | PubMed | PubMed, PMC |
| เครื่องเข้ารหัส |
|
| T5 | Apache 2.0 | | | สาธารณะ | C4 |
| Flan-T5 | Apache 2.0 | | | สาธารณะ | C4, ส่วนผสมของงาน (รูปที่ 2 ในกระดาษ) |
| บาร์ต | Apache 2.0 | | | สาธารณะ | Roberta Corpus |
| GLM | Apache 2.0 | | | สาธารณะ | Bookscorpus และ Wikipedia ภาษาอังกฤษ |
| chatglm | ใบอนุญาต chatglm | | ไม่มีการใช้เพื่อวัตถุประสงค์ที่ผิดกฎหมายหรือการวิจัยทางทหารไม่เป็นอันตรายต่อผลประโยชน์สาธารณะของสังคม | N/A | 1T โทเค็นของคลังภาษาจีนและภาษาอังกฤษ |
| ตัวถอดรหัสอย่างเดียว |
| GPT2 | ใบอนุญาต MIT ที่ได้รับการแก้ไข | | ใช้ GPT-2 อย่างรับผิดชอบและระบุว่าเนื้อหาของคุณถูกสร้างขึ้นโดยใช้ GPT-2 อย่างชัดเจน | สาธารณะ | webtext |
| Gpt-neo | ใบอนุญาต MIT | | | สาธารณะ | กอง |
| GPT-J | Apache 2.0 | | | สาธารณะ | กอง |
| ---> ดอลลี่ | CC โดย NC 4.0 | | | CC โดย NC 4.0 ขึ้นอยู่กับเงื่อนไขการใช้ข้อมูลที่สร้างโดย OpenAI | กองทหารรักษาการณ์ตนเอง |
| ---> gpt4all-j | Apache 2.0 | | | สาธารณะ | ชุดข้อมูล GPT4ALL-J |
| งูเหลือม | Apache 2.0 | | | สาธารณะ | กอง |
| ---> Dolly v2 | ใบอนุญาต MIT | | | สาธารณะ | กอง Databricks-Dolly-15K |
| เลือก | ข้อตกลงใบอนุญาต OPT-175B | | ไม่มีการพัฒนาที่เกี่ยวข้องกับการวิจัยการเฝ้าระวังและการทหารไม่เป็นอันตรายต่อผลประโยชน์สาธารณะของสังคม | สาธารณะ | Roberta Corpus, กอง, pushshift.io reddit |
| ---> opt-iml | ข้อตกลงใบอนุญาต OPT-175B | | เช่นเดียวกับ OPT | สาธารณะ | Opt Corpus รุ่นขยายของ Super-NaturalInstructions |
| ยัลม์ | Apache 2.0 | | | ไม่ได้ระบุ | กองทีมรวบรวมข้อความเป็นภาษารัสเซีย |
| ผลิบาน | ใบอนุญาตรถไฟ Bigscience | | ไม่มีการใช้การสร้างข้อมูลเท็จอย่างชัดเจนโดยมีวัตถุประสงค์เพื่อทำร้ายผู้อื่น
เนื้อหาโดยไม่ปฏิเสธอย่างชัดแจ้งว่าข้อความถูกสร้างขึ้น | สาธารณะ | Roots Corpus (Lauren¸con et al., 2022) |
| ---> Bloomz | ใบอนุญาตรถไฟ Bigscience | | เช่นเดียวกับการบานสะพรั่ง | สาธารณะ | Roots Corpus, xp3 |
| กาแล็กซี่ | CC BY-NC 4.0 | | | N/A | Galactica Corpus |
| ลาม่า | ใบอนุญาตที่ไม่ใช่เชิงพาณิชย์ | | ไม่มีการพัฒนาที่เกี่ยวข้องกับการวิจัยการเฝ้าระวังและการทหารไม่เป็นอันตรายต่อผลประโยชน์สาธารณะของสังคม | สาธารณะ | Commoncrawl, C4, GitHub, Wikipedia ฯลฯ |
| ---> alpaca | CC โดย NC 4.0 | | | CC โดย NC 4.0 ขึ้นอยู่กับเงื่อนไขการใช้ข้อมูลที่สร้างโดย OpenAI | Llama Corpus, Instruct |
| ---> Vicuna | CC โดย NC 4.0 | | | ขึ้นอยู่กับเงื่อนไขการใช้ข้อมูลที่เกิดจาก OpenAI;
แนวทางปฏิบัติด้านความเป็นส่วนตัวของ ShareGpt | Llama Corpus, 70k การสนทนาจาก ShareGpt.com |
| ---> gpt4all | Llama ที่ได้รับใบอนุญาต GPL | | | สาธารณะ | ชุดข้อมูล GPT4ALL |
| Openllama | Apache 2.0 | | | สาธารณะ | สีแดง |
| Codegeex | ใบอนุญาต codegeex | | ไม่มีการใช้เพื่อวัตถุประสงค์ที่ผิดกฎหมายหรือการวิจัยทางทหาร | สาธารณะ | กอง codeparrot ฯลฯ |
| สตาร์โคเดอร์ | ใบอนุญาต BigCode OpenRail-M V1 | | ไม่มีการใช้การสร้างข้อมูลเท็จอย่างชัดเจนโดยมีวัตถุประสงค์เพื่อทำร้ายผู้อื่น
เนื้อหาโดยไม่ปฏิเสธอย่างชัดแจ้งว่าข้อความถูกสร้างขึ้น | สาธารณะ | สแต็ค |
| MPT-7B | Apache 2.0 | | | สาธารณะ | MC4 (ภาษาอังกฤษ), The Stack, Redpajama, S2ORC |
| เหยี่ยว | ใบอนุญาต TII Falcon LLM | / | พร้อมใช้งานภายใต้ใบอนุญาตที่อนุญาตให้มีการใช้งานในเชิงพาณิชย์ | สาธารณะ | การกลั่นกรอง |
ประวัติดาว


