Les guides pratiques pour les modèles de grande langue
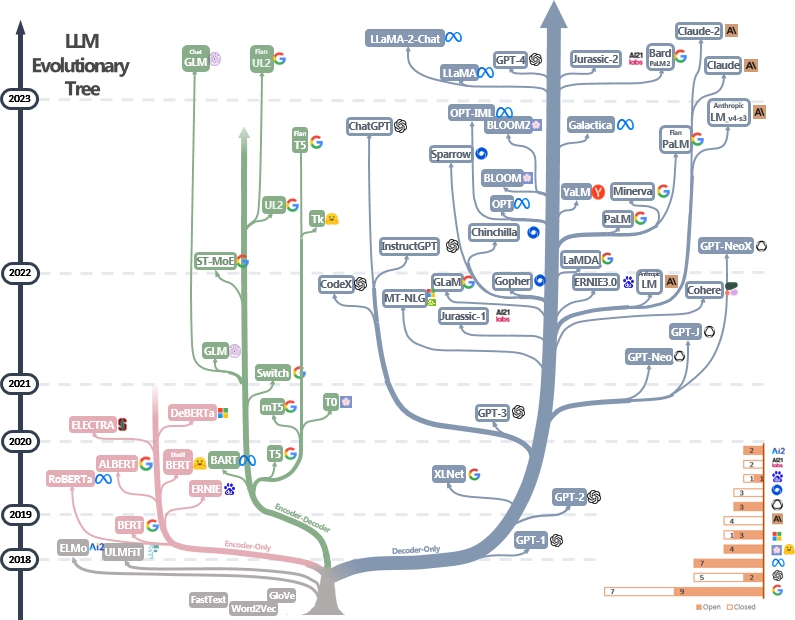
Une liste organisée (toujours activement mise à jour) des ressources de guide pratiques des LLM. Il est basé sur notre document d'enquête: exploiter la puissance des LLM dans la pratique: une enquête sur le chatppt et au-delà et les efforts de @xinyadu. L'enquête est en partie basée sur la seconde moitié de ce blog. Nous construisons également un arbre évolutif de modèles modernes de grands langues (LLM) pour retracer le développement de modèles de langue ces dernières années et met en évidence certains des modèles les plus connus.
Ces sources visent à aider les praticiens à naviguer dans le vaste paysage des modèles de grande langue (LLM) et leurs applications dans les applications de traitement du langage naturel (PNL). Nous incluons également leurs restrictions d'utilisation en fonction du modèle et des informations sur les licences de données. Si vous trouvez des ressources dans notre référentiel utiles, n'hésitez pas à les utiliser (n'oubliez pas de citer notre papier!?). Nous accueillons des demandes de traction pour affiner ce chiffre!
@article { yang2023harnessing ,
title = { Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond } ,
author = { Jingfeng Yang and Hongye Jin and Ruixiang Tang and Xiaotian Han and Qizhang Feng and Haoming Jiang and Bing Yin and Xia Hu } ,
year = { 2023 } ,
eprint = { 2304.13712 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}Dernières nouvelles?
- Nous avons ajouté la section d'utilisation et de restrictions.
- Nous avons utilisé PowerPoint pour tracer la figure et publié le fichier source PPTX pour notre figure GIF. [27/04/2023]
- Nous avons publié le fichier source de la version immobile PPTX et avons remplacé la figure de ce dépôt par la version immobile. [29/04/2023]
- Ajoutez Alexatm, unilm, unilmv2 à la figure et corrigez le logo pour TK. [29/04/2023]
- Ajoutez une section d'utilisation et de restrictions (à des fins commerciales et de recherche). Crédits au Dr Du. [5/8/2023]
Autres guides pratiques pour les LLM
- Pourquoi toute la reproduction publique de GPT-3 a-t-elle échoué? Dans quelles tâches devrions-nous utiliser GPT-3.5 / Chatgpt? 2023, blog
- Building LLM Applications for Production , 2023, blog
- Intelligence artificielle centrée sur les données , 2023, repo / blog / document
Catalogue
- Les guides pratiques pour les modèles de grande langue
- Guide pratique pour les modèles
- Modèles de langue de style Bert: coder-décodeur ou encodeur uniquement
- Modèles de langue de style GPT: le décodeur uniquement
- Guide pratique pour les données
- Données de prélèvement
- Données de finening
- Tester les données / données utilisateur
- Guide pratique pour les tâches PNL
- Tâches traditionnelles de la NLU
- Tâches de génération
- Tâches à forte intensité de connaissances
- Capacités à l'échelle
- Tâches spécifiques
- `` Tâches '' du monde réel
- Efficacité
- Fiabilité
- Réglage de l'instruction de référence
- Alignement
- Alignement de sécurité (inoffensif)
- Alignement de véracité (honnête)
- Guides pratiques pour inviter (utile)
- Efforts d'alignement de la communauté open source
- Utilisation et restrictions (modèles et données)
Guide pratique pour les modèles
Modèles de langue de style Bert: coder-décodeur ou encodeur uniquement
- Bert Bert: pré-formation des transformateurs bidirectionnels profonds pour la compréhension du langage , 2018, document
- Roberta Roberta: une approche de pré-formation Bert optimisée à optimisation , 2019, journal
- Distilbert Distilbert, une version distillée de Bert: plus petit, plus rapide, moins cher et plus léger , 2019, papier
- Albert Albert: A Lite Bert pour l'apprentissage auto-supervisé des représentations linguistiques , 2019, journal
- UNILM Unifiez Language Model Pre-Tra-Train pour la compréhension et la génération du langage naturel , article 2019
- Electra Electra: Encodeurs de texte pré-formation comme discriminateurs plutôt que générateurs , 2020, papier
- T5 "Exploration des limites de l'apprentissage du transfert avec un transformateur de texte à texte unifié" . Colin Raffel et al. JMLR 2019. Papier
- GLM "GLM-130B: un modèle pré-formé bilingue ouvert" . 2022. Papier
- Alexatm "Alexatm 20b: apprentissage à quelques coups à l'aide d'un modèle SEQ2SEQ multilingue à grande échelle" . Saleh Soltan et al. Arxiv 2022. Papier
- ST-MOE ST-MOE: Concevoir des modèles d'experts clairsemés stables et transférables . 2022 papier
Modèles de langue de style GPT: le décodeur uniquement
- GPT améliorant la compréhension du langage par la pré-formation générative . 2018. Papier
- Les modèles de langue GPT-2 sont des apprenants multitâches non surveillés . 2018. Papier
- GPT-3 "Les modèles de langage sont des apprenants à quelques tirs" . Neirips 2020. Papier
- OPT "OPT: ouvrez les modèles de langage de transformateur pré-formé" . 2022. Papier
- PALM "PAMPE: Échelle de la modélisation du langage avec des voies" . Aakanksha Chowdhery et al. Arxiv 2022. Papier
- Bloom "Bloom: un modèle de langage multilingue à accès ouvert 176B-paramètre" . 2022. Papier
- MT-NLG "Utilisation de Deeppeed et Megatron pour former NLG 530B, un modèle de langue génératif à grande échelle" . 2021. Papier
- Glam "glam: mise à l'échelle efficace des modèles de langage avec mélange des experts" . ICML 2022. Papier
- Gopher "Modèles de langage d'échelle: méthodes, analyse et perspectives de la formation Gopher" . 2021. Papier
- Chinchilla "Formation de modèles de grande langue en calcul en calcul" . 2022. Papier
- LAMDA "LAMDA: Modèles de langue pour les applications de dialogue" . 2021. Papier
- LLAMA "LLAMA: Modèles de langue de base ouverts et efficaces" . 2023. Papier
- GPT-4 "Rapport technique GPT-4" . 2023. Papier
- Bloomberggpt Bloomberggpt: un grand modèle de langue pour la finance , 2023, papier
- GPT-NEOX-20B: "GPT-NEOX-20B: Un modèle de langage autorégressif open source" . 2022. Papier
- PALM 2: "Rapport technique de Palm 2" . 2023. Tech.Report
- LLAMA 2: "LLAMA 2: Modèles de chat à fondation ouverte et à réglage fin" . 2023. Papier
- Claude 2: "Carte de modèle et évaluations pour les modèles Claude" . 2023. Carte modèle
Guide pratique pour les données
Données de prélèvement
- Redpajama , 2023. Repo
- La pile: un ensemble de données de 800 Go de texte diversifié pour la modélisation du langage , Arxiv 2020. Papier
- Comment l'objectif de pré-formation affecte-t-il ce que les modèles de langue importants apprennent sur les propriétés linguistiques? , ACL 2022. Papier
- Échelle des lois pour les modèles de langage neuronal , 2020. Papier
- Intelligence artificielle centrée sur les données: une enquête , 2023. Papier
- Comment GPT obtient-il sa capacité? Tracer les capacités émergentes des modèles de langage à leurs sources , 2022. Blog
Données de finening
- Benchmarking Classification de texte à tirs zéro: ensembles de données, approche d'évaluation et d'impression , EMNLP 2019. Papier
- Les modèles linguistiques sont des apprenants à quelques coups , NIPS 2020. Papier
- La génération de données synthétiques de LLMS aide-t-elle à l'exploration de texte clinique? Papier Arxiv 2023
Tester les données / données utilisateur
- Apprentissage de raccourci des modèles de grandes langues dans la compréhension du langage naturel: une enquête , Arxiv 2023. Paper
- Sur la robustesse de Chatgpt: une perspective contradictoire et hors distribution Arxiv, 2023. Paper
- SuperGlue: une référence plus collante pour les systèmes de compréhension du langage à usage général Arxiv 2019. Paper
Guide pratique pour les tâches PNL
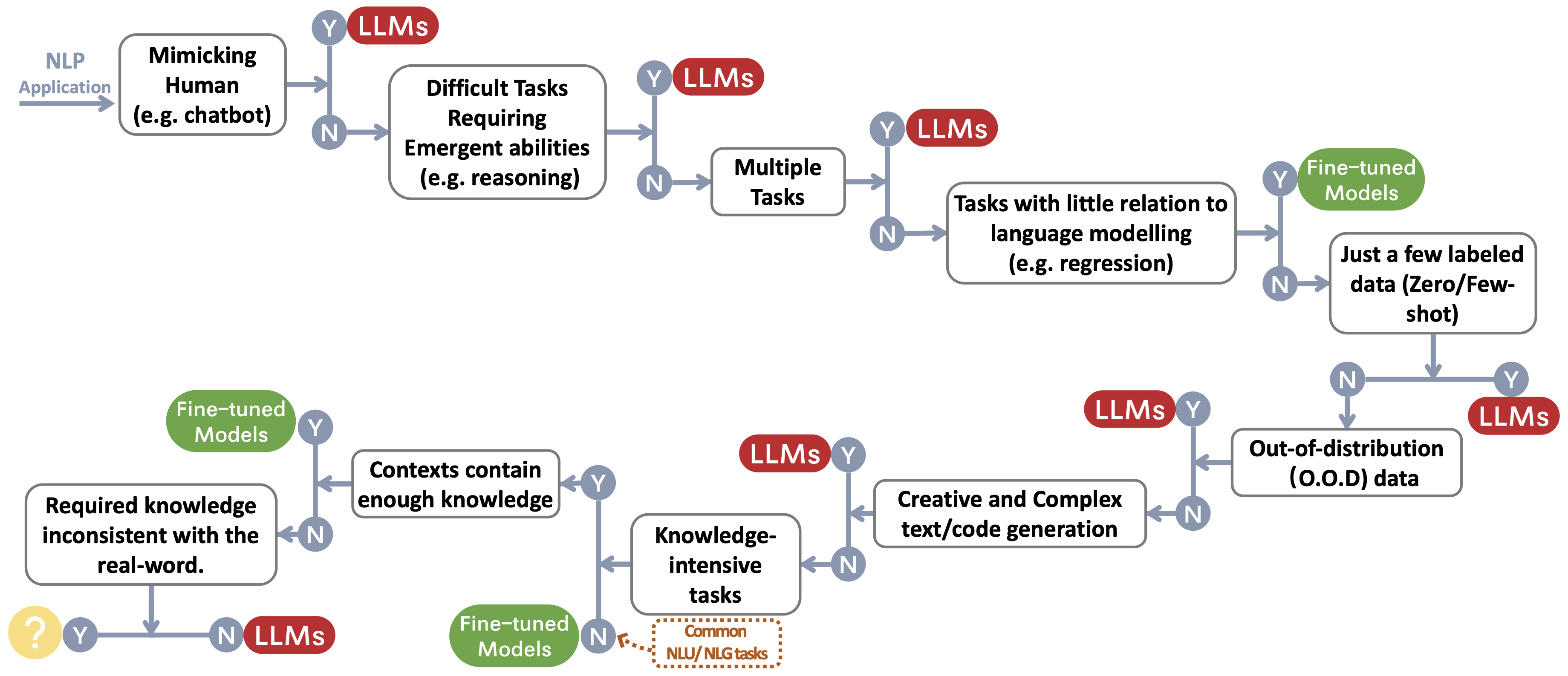
Nous construisons un flux de décision pour choisir des LLM ou des modèles affinés ~ Protect FootNotemark pour les applications NLP de l'utilisateur. Le flux de décision aide les utilisateurs à évaluer si leurs applications NLP en aval pour remplir des conditions spécifiques et, en fonction de cette évaluation, déterminent si les LLM ou les modèles affinés sont le choix le plus approprié pour leurs applications.
Tâches traditionnelles de la NLU
- Une référence pour la classification des commentaires toxiques sur le jeu de données de commentaires civils Arxiv 2023 Papier
- Chatgpt est-il un solveur de tâches de traitement du langage naturel à usage général? Arxiv 2023paper
- Benchmarking Modèles de grande langue pour le résumé des nouvelles Arxiv 2022 Papier
Tâches de génération
- Résumé des nouvelles et évaluation à l'ère du document GPT-3 Arxiv 2022
- Chatgpt est-il un bon traducteur? Oui avec GPT-4 comme papier moteur Arxiv 2023
- Systèmes de traduction machine multilingue de Microsoft pour la tâche partagée WMT21 , papier WMT2021
- Chatgpt peut-il aussi comprendre? Une étude comparative sur Chatgpt et Bert à réglage fin , Arxiv 2023, papier
Tâches à forte intensité de connaissances
- Mesurer la compréhension massive du langage multitâche , document ICLR 2021
- Au-delà du jeu d'imitation: quantifier et extrapoler les capacités des modèles de langue , papier Arxiv 2022
- Prix de mise à l'échelle inverse , lien 2022
- Atlas: apprentissage à quelques coups avec des modèles de langage augmenté de récupération , papier arxiv 2022
- Des modèles de grands langues codent les connaissances cliniques , article Arxiv 2022
Capacités à l'échelle
- Formation de modèles de grand langage calculées en calcul , document des Neirips 2022
- Échelle des lois pour les modèles de langage neuronal , article Arxiv 2020
- Résolution de problèmes de mots mathématiques avec les commentaires basés sur les processus et les résultats , article Arxiv 2022
- Chaîne de pensée suscitant un raisonnement dans des modèles de grands langues , Papitre des Neirips 2022
- Capacités émergentes des modèles de grande langue , TMLR 2022 Paper
- La mise à l'échelle inverse peut devenir en forme de U , papier arxiv 2022
- Vers le raisonnement dans les modèles de grande langue: une enquête , Arxiv 2022 Paper
Tâches spécifiques
- Image comme langue étrangère: Beit Pretoring pour toutes les tâches de vision et de vision en langue , article Arixv 2022
- Pali: un modèle d'image de langue multilingue à l'échelle conjointe , papier Arxiv 2022
- Auggpt: tirage du chatppt pour l'augmentation des données de texte , papier arxiv 2023
- GPT-3 est-il un bon annotateur de données? , Papier arxiv 2022
- Vous voulez réduire le coût d'étiquetage? GPT-3 peut aider , EMNLP FINDATIONS 2021 Papier
- GPT3MIX: Tiration des modèles de langue à grande échelle pour l'augmentation du texte , Papier EMNLP Résultats 2021
- LLM pour l'appariement du patient du patient: augmentation des données consacrées à la confidentialité vers de meilleures performances et généralisabilité , article Arxiv 2023
- Chatgpt surpasse les foules-travailleurs pour les tâches de l'annotation textuelle , papier Arxiv 2023
- G-EVAL: Évaluation NLG utilisant GPT-4 avec un meilleur alignement humain , papier Arxiv 2023
- GPTSCORE: Évaluez comme vous le souhaitez , papier Arxiv 2023
- Les modèles de grands langues sont des évaluateurs à la pointe de la technologie de la qualité de la traduction , article Arxiv 2023
- Chatgpt est-il un bon évaluateur NLG? Une étude préliminaire , article Arxiv 2023
`` Tâches '' du monde réel
- Sparks of Artificiel General Intelligence: Early Experiments with GPT-4 , Arxiv 2023 Paper
Efficacité
- Coût
- Modèle de langue GPT-3 d'Openai: un aperçu technique , 2020. Article de blog
- Mesurer l'intensité du carbone de l'IA dans les instances de nuage , FACCT 2022. Paper
- Dans l'IA, est-il toujours plus grand? , Article de la nature 2023. Article
- Les modèles de langue sont des apprenants à quelques tirs , Neirips 2020. Papier
- Prix , openai. Article de blog
- Latence
- Helm: Évaluation holistique des modèles de langage , Arxiv 2022. Papier
- Affinement final à paramètres
- LORA: Adaptation de faible rang des modèles de grands langues , Arxiv 2021. Papier
- Préfixe-réglage: optimisation des invites continues pour la génération , ACL 2021. Papier
- Pinage P: Le réglage rapide peut être comparable à un réglage fin à travers les échelles et les tâches , ACL 2022. Paper
- P-Tuning V2: le réglage rapide peut être comparable à un réglage fin universellement à travers les échelles et les tâches , Arxiv 2022. Paper
- Système de pré-formation
- Zero: Optimisations de la mémoire vers des modèles de paramètres de milliards de dollars , Arxiv 2019. Paper
- MEGATRON-LM: Formation de plusieurs milliards de modèles de langage de paramètres utilisant le parallélisme du modèle , Arxiv 2019. Paper
- Formation efficace du modèle de langue à grande échelle sur les grappes GPU à l'aide de Megatron-LM , Arxiv 2021. Paper
- Réduction de l'activation Recomputant dans de grands modèles de transformateurs , Arxiv 2021. Paper
Fiabilité
- Robustesse et étalonnage
- Calibrer avant utilisation: améliorant les performances à quelques coups des modèles de langage , ICML 2021. Paper
- SPEC: un étalonnage bas basé sur une invite sur l'atténuation de la variabilité des performances dans les notes cliniques Résumé , Arxiv 2023. Paper
- Biais fallacieux
- Les modèles de grands langues peuvent être des apprenants paresseux: analyser les raccourcis dans l'apprentissage dans le contexte , les résultats de l'ACL 2023 Paper
- Apprentissage de raccourci des modèles de grandes langues dans la compréhension du langage naturel: une enquête , 2023 document
- ATTENTIONNEMENT LES BIAS SESSAUX DANS LE SYSTÈME DE CONNUTER , WWW 2020 PAPIER
- Calibrer avant utilisation: améliorant les performances à quelques coups des modèles de langage , papier ICML 2021
- Apprentissage de raccourci dans les réseaux de neurones profonds , Nature Machine Intelligence 2020 Paper
- Les modèles basés sur des invites comprennent-ils vraiment la signification de leurs invites? , Papier NAACL 2022
- Problèmes de sécurité
- Carte système GPT-4 , papier 2023
- La science de la détection des textes générés par LLM , papier Arxiv 2023
- Comment les stéréotypes sont partagés dans le langage: une revue et une introduction des catégories et des stéréotypes (SCSC) Cadre de communication , Revue de la recherche en communication, article 2019
- Nuances de genre: disparités de précision intersectionnelle dans la classification commerciale des sexes , FACCT 2018 Paper
Réglage de l'instruction de référence
- Flan: Les modèles de langues à finetune sont des apprenants à tirs zéro , le papier Arxiv 2021
- T0: La formation invitée multitâche permet une généralisation des tâches zéro-shot , papier Arxiv 2021
- Généralisation de la tâche croisée via des instructions de crowdsourcing en langage naturel , papier ACL 2022
- TK-INSTRUCT: Super-Naturalinstructions: Généralisation via des instructions déclaratives sur plus de 1600 tâches NLP , Papier EMNLP 2022
- Flan-T5 / Palm: Modèles de langage d'instructions à l'échelle , papier Arxiv 2022
- La collecte de flan: conception de données et méthodes de réglage des instructions efficaces , papier arxiv 2023
- OPT-IML: Échelle du modèle de langue Instruction Meta Learning à travers l'objectif de la généralisation , Arxiv 2023 Paper
Alignement
- Apprentissage en renforcement profond des préférences humaines , NIPS 2017 Paper
- Apprendre à résumer à partir de la rétroaction humaine , article Arxiv 2020
- Un assistant de langue générale en tant que laboratoire d'alignement , article Arxiv 2021
- Formation d'un assistant utile et inoffensif avec apprentissage du renforcement des commentaires humains , article Arxiv 2022
- Enseigner des modèles de langue pour soutenir les réponses avec des citations vérifiées , papier arxiv 2022
- InstructGPT: Modèles de la langue de formation à suivre les instructions avec commentaires humains , article Arxiv 2022
- Amélioration de l'alignement des agents de dialogue via des jugements humains ciblés , article Arxiv 2022
- Échelle des lois pour la suroptimisation du modèle de récompense , article Arxiv 2022
- Support évolutif: mesurer les progrès sur la surveillance évolutive pour les modèles de grands langues , papier Arxiv 2022
Alignement de sécurité (inoffensif)
- Modèles de langage d'équipe rouge avec des modèles de langage , papier arxiv 2022
- IA constitutionnelle: inofficiation de la rétroaction de l'IA , article Arxiv 2022
- La capacité d'auto-correction morale dans les modèles de grande langue , papier arxiv 2023
- Openai: Notre approche de la sécurité de l'IA , blog 2023
Alignement de véracité (honnête)
- Apprentissage du renforcement pour les modèles de langue , blog 2023
Guides pratiques pour inviter (utile)
- Openai Cookbook . Bloguer
- Ingénierie rapide . Bloguer
- Chatgpt ingénierie rapide pour les développeurs! Cours
Efforts d'alignement de la communauté open source
- Auto-instruction: Alignez le modèle de langue avec des instructions auto-générées , papier Arxiv 2022
- Alpaga . Repo
- Vicuna . Repo
- Dolly . Bloguer
- Chat de profondeur . Bloguer
- Gpt4all . Repo
- Openassitant . Repo
- Chatglm . Repo
- Mousse . Repo
- Lamini . Repo / blog
Utilisation et restrictions
Nous construisons un tableau résumant les restrictions d'utilisation des LLM (par exemple à des fins commerciales et de recherche). En particulier, nous fournissons les informations des modèles et le point de vue de leurs données de pré-formation. Nous exhortons les utilisateurs de la communauté à se référer aux informations de licence pour les modèles et les données publics et les utiliser de manière responsable. Nous exhortons les développeurs à prêter une attention particulière aux licences, à les rendre transparentes et complètes, afin d'éviter toute utilisation indésirable et imprévue.
| LLMS | Modèle | Données |
|---|
| Licence | Usage commercial | Autres restrictions notables | Licence | Corpus |
| Encodeur uniquement |
|
| Série de modèles Bert (domaine général) | Apache 2.0 | ✅ | | Publique | Bookscorpus, Wikipedia anglais |
| Roberta | Licence MIT | ✅ | | Publique | Bookcorpus, cc-news, openwebtext, histoires |
| Ernie | Apache 2.0 | ✅ | | Publique | Wikipedia anglais |
| Scibert | Apache 2.0 | ✅ | | Publique | Bert Corpus, 1,14 m papiers de chercheur sémantique |
| Legalbert | CC BY-SA 4.0 | | | Public (sauf les données du projet d'accès aux jurisprudences) | Législation de l'UE, affaires judiciaires américaines, etc. |
| Biobert | Apache 2.0 | ✅ | | Pubment | PubMed, PMC |
| Coder-décodeur |
|
| T5 | Apache 2.0 | ✅ | | Publique | C4 |
| Flan-T5 | Apache 2.0 | ✅ | | Publique | C4, mélange de tâches (figure 2 sur papier) |
| Barbe | Apache 2.0 | ✅ | | Publique | Corpus Roberta |
| Glm | Apache 2.0 | ✅ | | Publique | Bookscorpus et Wikipedia anglais |
| Chatglm | Licence ChatGlm | | Aucune utilisation à des fins illégales ou de recherche militaire, aucun nuire à l'intérêt public de la société | N / A | 1t jetons de corpus chinois et anglais |
| Décodeur uniquement |
| Gpt2 | Licence MIT modifiée | ✅ | Utilisez GPT-2 de manière responsable et indiquez clairement que votre contenu a été créé à l'aide de GPT-2. | Publique | Webtext |
| Gpt-neo | Licence MIT | ✅ | | Publique | Pile |
| Gpt-j | Apache 2.0 | ✅ | | Publique | Pile |
| ---> Dolly | CC par NC 4.0 | | | CC par NC 4.0, sous réserve des termes d'utilisation des données générées par OpenAI | Pile, auto-instruction |
| ---> gpt4all-j | Apache 2.0 | ✅ | | Publique | Ensemble de données GPT4ALL-J |
| Pythie | Apache 2.0 | ✅ | | Publique | Pile |
| ---> Dolly V2 | Licence MIT | ✅ | | Publique | Pile, Databricks-Dolly-15K |
| OPTER | Contrat de licence OPT-175B | | Aucun développement relatif à la recherche sur la surveillance et aux militaires, aucun préjudice de la société | Publique | Roberta Corpus, The Pile, Pushshift.io Reddit |
| ---> opt-iMl | Contrat de licence OPT-175B | | Idem à opter | Publique | Opt Corpus, version étendue de Super-Naturalin Instructions |
| Yalm | Apache 2.0 | ✅ | | Indéterminé | Pile, les équipes ont collecté des textes en russe |
| FLORAISON | La licence de rail BigScience | ✅ | Aucune utilisation de la génération d'informations de fausses informations vérifiables dans le but de nuire aux autres;
Contenu sans décliner expressément que le texte est généré par la machine | Publique | Roots Corpus (Lauren¸con et al., 2022) |
| ---> Bloomz | La licence de rail BigScience | ✅ | Même chose à fleurir | Publique | Roots Corpus, XP3 |
| Galactica | CC BY-NC 4.0 | | | N / A | Le Galactica Corpus |
| Lama | Licence sur mesure non commerciale | | Aucun développement relatif à la recherche sur la surveillance et aux militaires, aucun préjudice de la société | Publique | Commoncrawl, C4, Github, Wikipedia, etc. |
| ---> Alpaca | CC par NC 4.0 | | | CC par NC 4.0, sous réserve des termes d'utilisation des données générées par OpenAI | Corpus lama, auto-instructeur |
| ---> vicuna | CC par NC 4.0 | | | Sous réserve des termes d'utilisation des données générées par OpenAI;
Pratiques de confidentialité de Sharegpt | Llama Corpus, 70k conversations sur sharegpt.com |
| ---> gpt4all | LLAMA GPL ADMÉCÉ | | | Publique | Ensemble de données gpt4all |
| Ouvrir | Apache 2.0 | ✅ | | Publique | Redpajama |
| Codegeex | La licence Codegeex | | Aucune utilité à des fins illégales ou de recherche militaire | Publique | Pile, code de code, etc. |
| Coder d'étoile | Licence BigCode OpenRail-M V1 | ✅ | Aucune utilisation de la génération d'informations de fausses informations vérifiables dans le but de nuire aux autres;
Contenu sans décliner expressément que le texte est généré par la machine | Publique | La pile |
| MPT-7B | Apache 2.0 | ✅ | | Publique | MC4 (anglais), The Stack, Redpajama, S2ORC |
| faucon | Licence Tii Falcon LLM | ✅ / | Disponible sous une licence permettant une utilisation commerciale | Publique | RefinedWeb |
Histoire des étoiles


