Os guias práticos para grandes modelos de linguagem
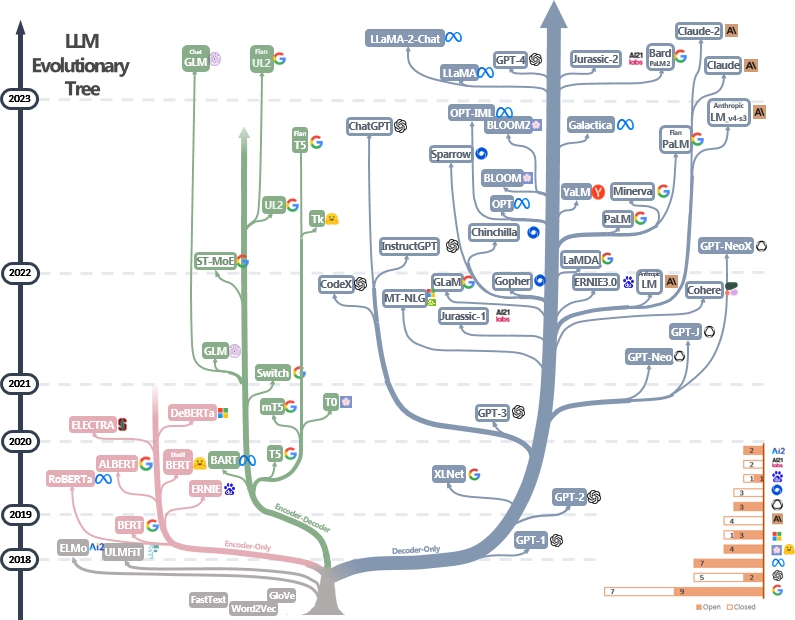
Uma lista com curadoria (ainda atualizada ativamente) de recursos práticos do LLMS. É baseado em nosso documento de pesquisa: aproveitando o poder do LLMS na prática: uma pesquisa sobre ChatGPT e além e esforços do @Xinyadu. A pesquisa é parcialmente baseada na segunda metade deste blog. Também construímos uma árvore evolutiva de modelos modernos de grandes idiomas (LLMS) para rastrear o desenvolvimento de modelos de idiomas nos últimos anos e destaca alguns dos modelos mais conhecidos.
Essas fontes visam ajudar os profissionais a navegar no vasto cenário de grandes modelos de idiomas (LLMS) e suas aplicações em aplicativos de processamento de linguagem natural (PNL). Também incluímos suas restrições de uso com base no modelo e nas informações de licenciamento de dados. Se você encontrar algum recurso em nosso repositório útil, sinta -se à vontade para usá -los (não se esqueça de citar nosso artigo!?). Congratulamo -nos com pedidos de puxar para refinar esta figura!
@article { yang2023harnessing ,
title = { Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond } ,
author = { Jingfeng Yang and Hongye Jin and Ruixiang Tang and Xiaotian Han and Qizhang Feng and Haoming Jiang and Bing Yin and Xia Hu } ,
year = { 2023 } ,
eprint = { 2304.13712 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}Últimas notícias?
- Adicionamos seção de uso e restrições.
- Usamos o PowerPoint para plotar a figura e liberamos o arquivo de origem PPTX para a nossa figura GIF. [27/04/2023]
- Lançamos o arquivo de origem para a versão Still PPTX e substituímos a figura neste repositório pela versão Still. [29/4/2023]
- Adicione Alexatm, Unilm, Unilmv2 à figura e corrija o logotipo para Tk. [29/4/2023]
- Adicione a seção de uso e restrições (para fins comerciais e de pesquisa). Créditos para o Dr. Du. [5/8/2023]
Outros guias práticos para LLMS
- Por que toda a reprodução pública do GPT-3 falhou? Em quais tarefas devemos usar o GPT-3.5/ChatGPT? 2023, blog
- Building LLM Aplicações para produção , 2023, blog
- Inteligência artificial centrada em dados , 2023, repo/blog/papel
Catálogo
- Os guias práticos para grandes modelos de linguagem
- Guia prático para modelos
- Modelos de idiomas no estilo Bert: codificador-decodificador ou codificador
- Modelos de idiomas no estilo GPT: somente decodificador
- Guia prático para dados
- Dados de pré -treinamento
- Dados de Finetuning
- Dados de teste/dados do usuário
- Guia prático para tarefas de PNL
- Tarefas tradicionais da NLU
- Tarefas de geração
- Tarefas intensivas em conhecimento
- Habilidades com escala
- Tarefas específicas
- Tarefas do mundo real
- Eficiência
- Confiabilidade
- Ajuste de instrução de referência
- Alinhamento
- Alinhamento de segurança (inofensivo)
- Alinhamento da veracidade (honesto)
- Guias práticos para solicitar (útil)
- Esforços de alinhamento da comunicação de código aberto
- Uso e restações (modelos e dados)
Guia prático para modelos
Modelos de idiomas no estilo Bert: codificador-decodificador ou codificador
- Bert Bert: pré-treinamento de transformadores bidirecionais profundos para entendimento de idiomas , 2018, artigo
- Roberta Roberta: Uma abordagem de pré -treinamento de Bert robustamente otimizada , 2019, artigo
- Distilbert Distilbert, Uma versão destilada de Bert: menor, mais rápido, mais barato e mais leve , 2019, artigo
- Albert Albert: Um Lite Bert para o aprendizado auto-supervisionado de representações de idiomas , 2019, artigo
- UNILM Unified Language Model pré-treinamento para compreensão e geração de linguagem natural , artigo de 2019
- Electra Electra: codificadores de texto pré-treinamento como discriminadores em vez de geradores , 2020, papel
- T5 "Explorando os limites do aprendizado de transferência com um transformador de texto em texto unificado" . Colin Raffel et al. JMLR 2019. Paper
- GLM "GLM-130B: um modelo pré-treinado bilíngue aberto" . 2022. Papel
- Alexatm "Alexatm 20b: aprendizado de poucos tiros usando um modelo multilíngue seq2seq em larga escala" . Saleh Soltan et al. Arxiv 2022. Papel
- ST-MOE ST-MOE: Projetando modelos especializados de especialistas estáveis e transferíveis . 2022 Papel
Modelos de idiomas no estilo GPT: somente decodificador
- GPT melhorando a compreensão da linguagem por pré-treinamento generativo . 2018. Paper
- Os modelos de idiomas GPT-2 são aprendizes multitarefa sem supervisão . 2018. Paper
- GPT-3 "Modelos de idiomas são poucos alunos" . Neurips 2020. Papel
- OPT "OPT: Abra os modelos de linguagem de transformadores pré-treinados" . 2022. Papel
- Palm "Palm: escala de modelagem de linguagem com caminhos" . Aakanksha Chowdhery et al. Arxiv 2022. Papel
- Bloom "Bloom: um modelo de linguagem multilíngue de acesso aberto de 176b-parâmetros" . 2022. Papel
- Mt-nlg "Usando DeepSpeed e Megatron para treinar o Megatron-Turing NLG 530B, um modelo de linguagem generativa em larga escala" . 2021. Papel
- Glam "Glam: escala eficiente de modelos de linguagem com mistura de especialistas" . ICML 2022. Papel
- Gopher "Modelos de linguagem de escala: métodos, análises e idéias do treinamento de Gopher" . 2021. Papel
- Chinchilla "Treinando com computação ótima de grandes modelos de idiomas" . 2022. Papel
- Lamda "Lamda: modelos de idiomas para aplicativos de diálogo" . 2021. Papel
- LLAMA "LLAMA: MODELOS DE LÍNGUA DE FASTILHA ABERTA E EFICENTE" . 2023. Papel
- GPT-4 "Relatório Técnico GPT-4" . 2023. Papel
- Bloomberggpt Bloomberggpt: um grande modelo de linguagem para finanças , 2023, papel
- GPT-Neox-20B: "GPT-Neox-20B: um modelo de linguagem autoregressiva de código aberto" . 2022. Papel
- Palm 2: "Relatório Técnico Palm 2" . 2023. Tech.Report
- Llama 2: "Llama 2: Fundação aberta e modelos de bate-papo ajustados" . 2023. Papel
- Claude 2: "Modelo Card e avaliações para modelos Claude" . 2023. Modelo Card
Guia prático para dados
Dados de pré -treinamento
- Redpajama , 2023. Repo
- A pilha: um conjunto de dados de 800 GB de texto diversificado para modelagem de idiomas , Arxiv 2020. Paper
- Como o objetivo de pré-treinamento afeta o que os grandes modelos de linguagem aprendem sobre propriedades linguísticas? , ACL 2022. Papel
- Leis de dimensionamento para modelos de idiomas neurais , 2020. Papel
- Inteligência artificial centrada em dados: uma pesquisa , 2023. Paper
- Como o GPT obtém sua capacidade? Rastreando habilidades emergentes dos modelos de idiomas em suas fontes , 2022. Blog
Dados de Finetuning
- Classificação de texto com tiro zero de benchmarking: conjuntos de dados, avaliação e interrupção da abordagem , EMNLP 2019. Paper
- Modelos de idiomas são poucos alunos , Nips 2020. Papel
- A geração de dados sintéticos de LLMs ajuda a mineração de texto clínico? Arxiv 2023 Papel
Dados de teste/dados do usuário
- Aprendizagem de atalho de grandes modelos de idiomas em entendimento da linguagem natural: uma pesquisa , Arxiv 2023. Paper
- Sobre a robustez do chatgpt: uma perspectiva adversária e fora da distribuição Arxiv, 2023. Paper
- Supercola: um benchmark mais pegajoso para sistemas de compreensão de idiomas de uso geral Arxiv 2019. Paper
Guia prático para tarefas de PNL
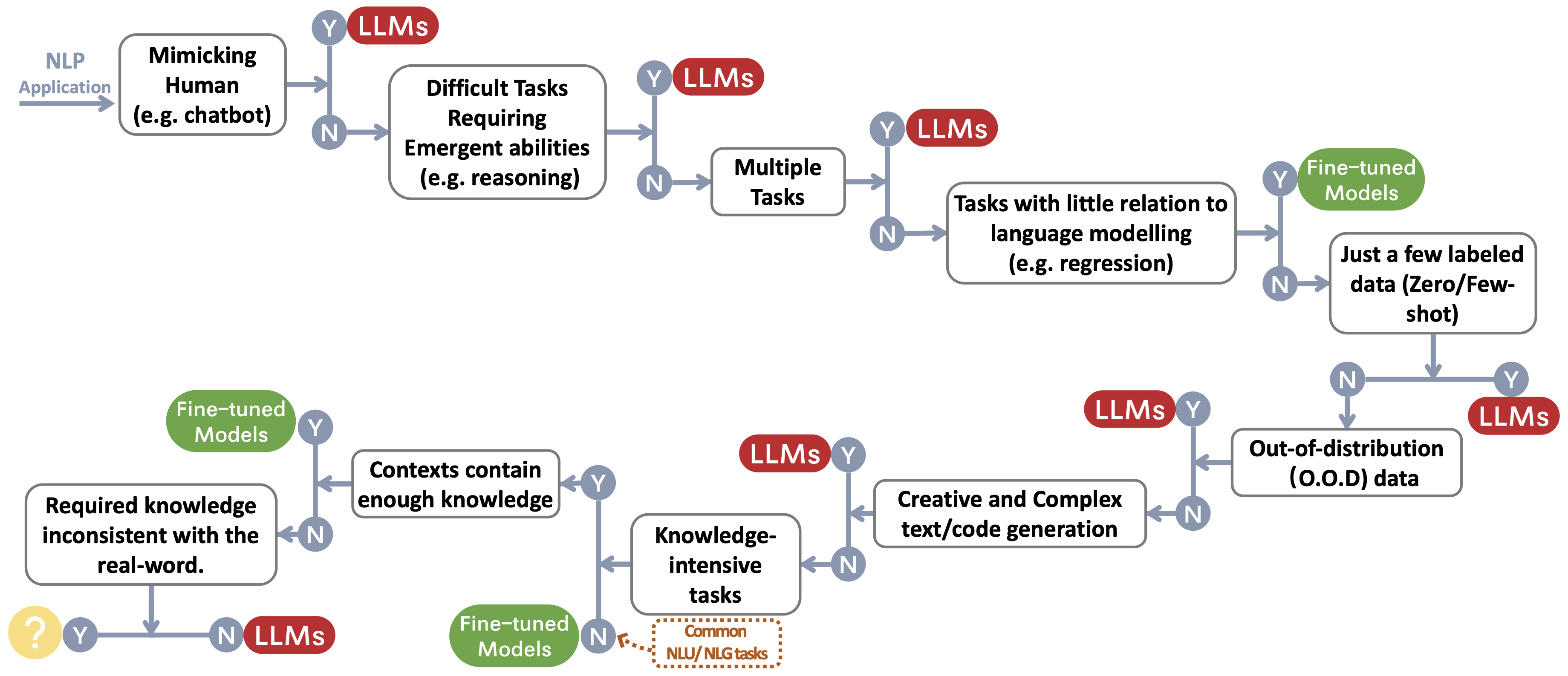
Construímos um fluxo de decisão para escolher LLMs ou modelos de ajuste fino ~ Protect Footnotemark para os aplicativos NLP do usuário. O fluxo de decisão ajuda os usuários a avaliar se seus aplicativos de PNL a jusante em questão atendem às condições específicas e, com base nessa avaliação, determinar se LLMS ou modelos ajustados são a escolha mais adequada para seus aplicativos.
Tarefas tradicionais da NLU
- Uma referência para a classificação de comentários tóxicos sobre o conjunto de dados de comentários civis Arxiv 2023 Paper
- O Chatgpt é um solucionador de tarefas de processamento de linguagem natural de uso geral? Arxiv 2023 Papa
- Benchmarking Grandes modelos de idiomas para o artigo de resumo de notícias Arxiv 2022 Paper
Tarefas de geração
- Resumo de notícias e avaliação na era do papel GPT-3 Arxiv 2022
- Chatgpt é um bom tradutor? Sim com o GPT-4 como o motor do motor Arxiv 2023
- Sistemas multilíngues de tradução de máquinas da Microsoft para tarefa compartilhada WMT21 , papel WMT2021
- O ChatGpt também pode entender? Um estudo comparativo sobre ChatGPT e Bert Fined Bert , Arxiv 2023, Paper
Tarefas intensivas em conhecimento
- Medindo o entendimento maciço da linguagem multitarefa , ICLR 2021 Paper
- Além do jogo de imitação: quantificando e extrapolando os recursos dos modelos de linguagem , Arxiv 2022 Paper
- Prêmio de escala inversa , link 2022
- Atlas: Aprendizagem com poucos tiros com modelos de idiomas aumentados de recuperação , Arxiv 2022 Paper
- Modelos de idiomas grandes codificam conhecimento clínico , Arxiv 2022 Paper
Habilidades com escala
- Treinamento Compute-Optimal Language Models , Neurips 2022 Paper
- Leis de escala para modelos de idiomas neurais , Arxiv 2020 Paper
- Resolvendo problemas de palavras matemáticas com feedback baseado em processos e resultados , Arxiv 2022 Paper
- Cadeia de pensamento provocando provas o raciocínio em grandes modelos de idiomas , Neurips 2022 Paper
- Habilidades emergentes de grandes modelos de idiomas , papel TMLR 2022
- A escala inversa pode se tornar em forma de U , Arxiv 2022 Paper
- Rumo ao raciocínio em grandes modelos de idiomas: uma pesquisa , Arxiv 2022 Paper
Tarefas específicas
- Imagem como uma língua estrangeira: Beit pré-treinamento para todas as tarefas de visão e linguagem da visão , papel Arixv 2022
- Pali: Um modelo de imagem multilíngue em escala em conjunto , Arxiv 2022 Paper
- Auggpt: alavancando ChatGPT para aumento de dados de texto , Arxiv 2023 Paper
- O GPT-3 é um bom anotador de dados? , Arxiv 2022 Paper
- Quer reduzir o custo de rotulagem? GPT-3 pode ajudar , descobertas do EMNLP 2021
- GPT3MIX: alavancando modelos de idiomas em larga escala para aumento de texto , descobertas do EMNLP 2021
- LLM para correspondência de julgamento do paciente: Aumentação de dados com reconhecimento de privacidade para melhor desempenho e generalização , Arxiv 2023 Paper
- O ChatGPT supera os trabalhadores de multidões para tarefas de antação de texto , Arxiv 2023 Paper
- G-EVAL: Avaliação NLG usando GPT-4 com melhor alinhamento humano , Arxiv 2023 Paper
- GPTSCORE: Avalie como você deseja , Arxiv 2023 Paper
- Modelos de idiomas grandes são avaliadores de última geração da qualidade da tradução , Arxiv 2023 Paper
- O ChatGPT é um bom avaliador NLG? Um estudo preliminar , Arxiv 2023 Paper
Tarefas do mundo real
- Sparks de Inteligência Geral Artificial: Experiências iniciais com GPT-4 , Arxiv 2023 Paper
Eficiência
- Custo
- Modelo de idioma GPT-3 do OpenAI: uma visão geral técnica , 2020. Postagem do blog
- Medindo a intensidade do carbono da IA em instâncias de nuvem , FACCT 2022. Paper
- Na IA, é maior sempre melhor? , Artigo da natureza 2023. Artigo
- Modelos de idiomas são poucos alunos , Neurips 2020. Papel
- Preço , Openai. Postagem do blog
- Latência
- Helm: Avaliação holística de modelos de linguagem , Arxiv 2022. Papel
- Ajuste fino com eficiência de parâmetro
- Lora: Adaptação de baixo rank de grandes modelos de linguagem , Arxiv 2021. Papel
- Tuneamento de prefixos: otimizando os avisos contínuos para a geração , ACL 2021. Papel
- Tuneing P: A ajuste imediato pode ser comparável ao ajuste fino em escalas e tarefas , ACL 2022. Papel
- P2 de ajuste P2: ajuste rápido pode ser comparável ao ajuste fino universalmente em escalas e tarefas , Arxiv 2022. Paper
- Sistema de pré -treinamento
- Zero: Otimizações de memória para treinar modelos de parâmetros de trilhões , Arxiv 2019. Paper
- Megatron-LM: Treinando modelos de linguagem de parâmetros de bilhões de bilhões usando o paralelismo do modelo , ARXIV 2019. Paper
- Treinamento de modelo de linguagem em larga escala eficiente em clusters de GPU usando Megatron-LM , Arxiv 2021. Papel
- Reduzindo a recomputação de ativação em grandes modelos de transformadores , Arxiv 2021. Paper
Confiabilidade
- Robustez e calibração
- Calibre antes do uso: Melhorando o desempenho de poucos modelos de idiomas , ICML 2021. Paper
- Especial: Uma calibração suave baseada em prompt sobre a variabilidade de desempenho em mitigação no resumo de notas clínicas , Arxiv 2023. Paper
- Preconceitos espúrios
- Modelos de idiomas grandes podem ser aprendizes preguiçosos: analisar atalhos no aprendizado no contexto , descobertas do papel da ACL 2023
- Aprendizagem de atalho de grandes modelos de idiomas no entendimento da linguagem natural: uma pesquisa , 2023 papel
- Mitigando o viés de gênero no sistema de legendas , www 2020 papel
- Calibre antes do uso: Melhorando o desempenho de poucos modelos de idiomas , o papel ICML 2021
- Aprendizagem de atalho em redes neurais profundas , Paper Nature Machine Intelligence 2020
- Os modelos rápidos baseados realmente entendem o significado de seus avisos? , NAACL 2022 Paper
- Questões de segurança
- Cartão do sistema GPT-4 , papel 2023
- The Science of Detecting LLM Textos gerados
- Como os estereótipos são compartilhados através da linguagem: uma revisão e introdução da estrutura da Comunicação de Categorias e Estereótipos (SCSC) , Revisão da Pesquisa de Comunicação, Artigo de 2019
- Tons de gênero: Disparidades de precisão interseccional na classificação comercial de gênero , documento FACCT 2018
Ajuste de instrução de referência
- Flan: Modelos de idiomas FinetUned são alunos de tiro zero , Arxiv 2021 Paper
- T0: O treinamento solicitado por várias tarefas permite a generalização de tarefas zero , Arxiv 2021 Paper
- Generalização cruzada por meio de instruções de crowdsourcing de idiomas naturais , papel ACL 2022
- TK-Instruct: Supernaturalinstructions: Generalização por meio de instruções declarativas em 1600+ tarefas de NLP , papel EMNLP 2022
- FLAN-T5/PALM: Modelos de linguagem de instrução-instrução , Arxiv 2022 Paper
- A coleção de flan: projetando dados e métodos para ajuste eficaz de instruções , Arxiv 2023 Paper
- OPT-IML: Sconing Language Model Instrução Meta Learning através da lente da generalização , Arxiv 2023 Paper
Alinhamento
- Aprendizagem de reforço profundo com as preferências humanas , papel NIPS 2017
- Aprendendo a resumir a partir do feedback humano , Arxiv 2020 Paper
- Um assistente de idioma geral como laboratório de alinhamento , Arxiv 2021 Paper
- Treinando um assistente útil e inofensivo com aprendizado de reforço com feedback humano , Arxiv 2022 Paper
- Ensinar modelos de idiomas para apoiar respostas com citações verificadas , Arxiv 2022 Paper
- InstructGPT: Treinando modelos de idiomas para seguir as instruções com feedback humano , Arxiv 2022 Paper
- Melhorando o alinhamento de agentes de diálogo por meio de julgamentos humanos direcionados , Arxiv 2022 Paper
- Leis de dimensionamento para o modelo de otimização do modelo de recompensa , Arxiv 2022 Paper
- Supervisão escalável: medindo o progresso na supervisão escalável para grandes modelos de idiomas , Arxiv 2022 Paper
Alinhamento de segurança (inofensivo)
- Modelos de idiomas em equipes vermelhas com modelos de idiomas , Arxiv 2022 Paper
- AI constitucional: inofensibilidade do feedback da IA , Arxiv 2022 Paper
- A capacidade de autocorreção moral em grandes modelos de idiomas , Arxiv 2023 Paper
- OpenAI: nossa abordagem à segurança da IA , 2023 Blog
Alinhamento da veracidade (honesto)
- Aprendizagem de reforço para modelos de idiomas , 2023 blog
Guias práticos para solicitar (útil)
- Livro de receitas do Openai . Blog
- Engenharia rápida . Blog
- Chatgpt Prompt Engineering for Developers! Curso
Esforços de alinhamento da comunicação de código aberto
- Auto-instrução: alinhando o modelo de linguagem com instruções auto-geradas , Arxiv 2022 Paper
- Alpaca . Repo
- Vicuna . Repo
- Dolly . Blog
- DeepSpeed-Chat . Blog
- Gpt4all . Repo
- OpenAssitant . Repo
- Chatglm . Repo
- Musgo . Repo
- Lamini . Repo/blog
Uso e restrições
Construímos uma tabela resumindo as restrições de uso do LLMS (por exemplo, para fins comerciais e de pesquisa). Em particular, fornecemos as informações dos modelos e a perspectiva de seus dados de pré -treinamento. Instamos os usuários da comunidade a se referir às informações de licenciamento para modelos e dados públicos e usá -los de maneira responsável. Instamos os desenvolvedores a prestar atenção especial ao licenciamento, torná -los transparentes e abrangentes, para evitar qualquer uso indesejado e imprevisto.
| Llms | Modelo | Dados |
|---|
| Licença | Uso comercial | Outras restrições notáveis | Licença | Corpus |
| Somente codificador |
|
| Série de modelos Bert (domínio geral) | Apache 2.0 | ✅ | | Público | Bookscorpus, Wikipedia em inglês |
| Roberta | MIT Licença | ✅ | | Público | Bookcorpus, CC-News, OpenWebtext, Histórias |
| Ernie | Apache 2.0 | ✅ | | Público | Wikipedia inglesa |
| Scibert | Apache 2.0 | ✅ | | Público | Bert Corpus, 1.14 milhões de artigos da semântica Scholar |
| Legalbert | CC BY-SA 4.0 | | | Público (exceto dados do projeto de acesso à jurisprudência) | Legislação da UE, processos judiciais dos EUA, etc. |
| BioBert | Apache 2.0 | ✅ | | PubMed | PubMed, PMC |
| Encoder-Decoder |
|
| T5 | Apache 2.0 | ✅ | | Público | C4 |
| Flan-t5 | Apache 2.0 | ✅ | | Público | C4, Mistura de tarefas (Fig 2 em papel) |
| Bart | Apache 2.0 | ✅ | | Público | Roberta Corpus |
| Glm | Apache 2.0 | ✅ | | Público | Bookscorpus e Wikipedia inglesa |
| Chatglm | Licença de chatglm | | Sem uso para fins ilegais ou pesquisa militar, sem prejudicar o interesse público da sociedade | N / D | 1T tokens de corpus chinês e inglês |
| Apenas decodificador |
| GPT2 | Licença MIT modificada | ✅ | Use GPT-2 com responsabilidade e claramente indica que seu conteúdo foi criado usando o GPT-2. | Público | WebText |
| GPT-Neo | MIT Licença | ✅ | | Público | Pilha |
| GPT-J | Apache 2.0 | ✅ | | Público | Pilha |
| ---> Dolly | CC por NC 4.0 | | | CC por NC 4.0, sujeito a termos de uso dos dados gerados pelo OpenAI | Pilha, auto-instrução |
| ---> gpt4all-j | Apache 2.0 | ✅ | | Público | Conjunto de dados GPT4all-j |
| Pythia | Apache 2.0 | ✅ | | Público | Pilha |
| ---> dolly v2 | MIT Licença | ✅ | | Público | Pilha, Databricks-Dolly-15k |
| OPTAR | Contrato de licença OPT-175B | | Nenhum desenvolvimento relacionado à pesquisa de vigilância e militar, sem prejudicar o interesse público da sociedade | Público | Roberta Corpus, The Pile, PushShift.io Reddit |
| ---> opt-iml | Contrato de licença OPT-175B | | o mesmo para optar | Público | Opt Corpus, versão estendida de super-insuficiência natural |
| Yalm | Apache 2.0 | ✅ | | Não especificado | Pilha, equipes colecionaram textos em russo |
| FLORESCER | A licença ferroviária da Bigscience | ✅ | Nenhum uso da geração de informações verificamente falsas com o objetivo de prejudicar os outros;
Conteúdo sem se isentar expressamente que o texto é gerado pela máquina | Público | Roots Corpus (Lauren¸con et al., 2022) |
| ---> Bloomz | A licença ferroviária da Bigscience | ✅ | O mesmo para florescer | Público | Roots Corpus, xp3 |
| Galactica | CC BY-NC 4.0 | | | N / D | O corpus de Galactica |
| Lhama | Licença sob medida não comercial | | Nenhum desenvolvimento relacionado à pesquisa de vigilância e militar, sem prejudicar o interesse público da sociedade | Público | CommonCrawl, C4, Github, Wikipedia, etc. |
| ---> Alpaca | CC por NC 4.0 | | | CC por NC 4.0, sujeito a termos de uso dos dados gerados pelo OpenAI | LLAMA CORPUS, auto-estrutura |
| ---> Vicuna | CC por NC 4.0 | | | Sujeito a termos de uso dos dados gerados pelo OpenAI;
Práticas de privacidade do compartilhamento | LLAMA CORPUS, 70K Conversas de ShareGpt.com |
| ---> gpt4all | Llama licenciada da GPL | | | Público | DATASET GPT4ALL |
| Openllama | Apache 2.0 | ✅ | | Público | Redpajama |
| CodegeEx | A licença CodeGeEx | | Sem uso para fins ilegais ou pesquisa militar | Público | Pilha, codeparrot, etc. |
| Starcoder | Licença BigCode OpenRail-M V1 | ✅ | Nenhum uso da geração de informações verificamente falsas com o objetivo de prejudicar os outros;
Conteúdo sem se isentar expressamente que o texto é gerado pela máquina | Público | A pilha |
| MPT-7B | Apache 2.0 | ✅ | | Público | Mc4 (inglês), The Stack, Redpajama, S2orc |
| falcão | Licença Tii Falcon LLM | ✅// | Disponível sob uma licença que permita o uso comercial | Público | RefinedWeb |
História da estrela


