Las guías prácticas para modelos de idiomas grandes
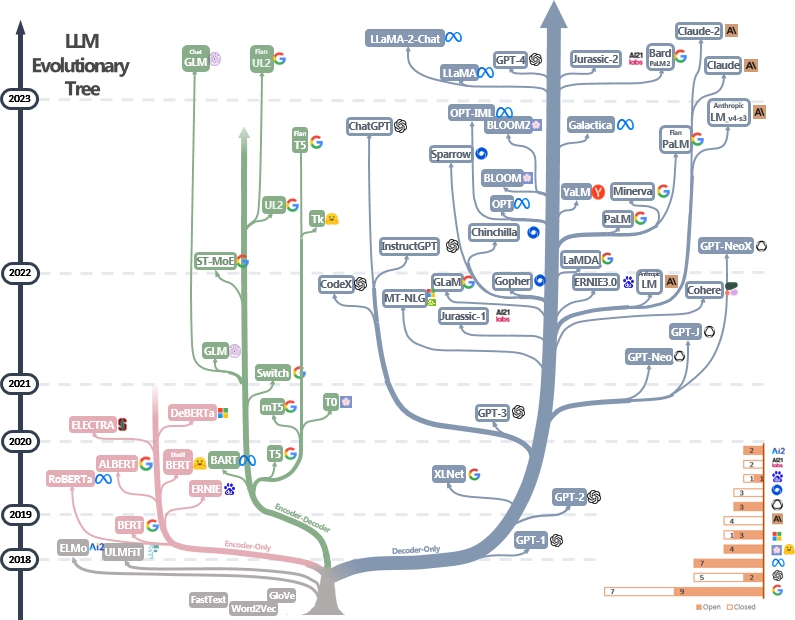
Una lista curada (aún actualizada activamente) de recursos de la guía práctica de LLM. Se basa en nuestro documento de encuesta: aprovechando el poder de los LLM en la práctica: una encuesta sobre chatgpt y más allá y esfuerzos de @xinyadu. La encuesta se basa parcialmente en la segunda mitad de este blog. También construimos un árbol evolutivo de modelos modernos de lenguaje grande (LLMS) para rastrear el desarrollo de modelos de idiomas en los últimos años y destaca algunos de los modelos más conocidos.
Estas fuentes tienen como objetivo ayudar a los profesionales a navegar el vasto panorama de los modelos de idiomas grandes (LLM) y sus aplicaciones en aplicaciones de procesamiento del lenguaje natural (PNL). También incluimos sus restricciones de uso basadas en el modelo y la información de licencia de datos. Si encuentra útiles recursos en nuestro repositorio, no dude en usarlos (¡no olvides citar nuestro documento?). ¡Agradecemos las solicitudes de extracción para refinar esta cifra!
@article { yang2023harnessing ,
title = { Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond } ,
author = { Jingfeng Yang and Hongye Jin and Ruixiang Tang and Xiaotian Han and Qizhang Feng and Haoming Jiang and Bing Yin and Xia Hu } ,
year = { 2023 } ,
eprint = { 2304.13712 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}¿Últimas noticias?
- Agregamos la sección de uso y restricciones.
- Utilizamos PowerPoint para trazar la figura y lanzamos el archivo fuente PPTX para nuestra figura GIF. [27/04/2023]
- Lanzamos el archivo fuente para la versión fija PPTX y reemplazamos la figura en este repositorio con la versión fija. [29/04/2023]
- Agregue Alexatm, Unilm, UNILMV2 a la figura y corrija el logotipo para TK. [29/04/2023]
- Agregue la sección de uso y restricciones (para fines comerciales y de investigación). Créditos al Dr. Du. [5/8/2023]
Otras guías prácticas para LLMS
- ¿Por qué falló toda la reproducción pública de GPT-3? ¿En qué tareas debemos usar GPT-3.5/CHATGPT? 2023, blog
- Building LLM Aplicaciones para la producción , 2023, blog
- Inteligencia artificial centrada en datos , 2023, Repo/Blog/Paper
Catalogar
- Las guías prácticas para modelos de idiomas grandes
- Guía práctica para modelos
- Modelos de idiomas de estilo Bert: codificador-decodificador o solo codificador
- Modelos de idiomas de estilo GPT: solo decodificador
- Guía práctica para datos
- Datos previos a la altura
- Datos de finete
- Prueba de datos/datos del usuario
- Guía práctica para tareas de PNL
- Tareas tradicionales de la NLU
- Tareas de generación
- Tareas intensivas en conocimiento
- Habilidades con escala
- Tareas específicas
- '' Tareas del mundo real '
- Eficiencia
- Integridad
- Ajuste de instrucciones de referencia
- Alineación
- Alineación de seguridad (inofensiva)
- Alineación de veracidad (honesto)
- Guías prácticas para solicitar (útil)
- Esfuerzos de alineación de la comunicación de código abierto
- Uso y restricciones (modelos y datos)
Guía práctica para modelos
Modelos de idiomas de estilo Bert: codificador-decodificador o solo codificador
- Bert Bert: Prerreining de transformadores bidireccionales profundos para la comprensión del lenguaje , 2018, documento
- Roberta Roberta: un enfoque de prepertinamiento de Bert de manera robusta , 2019, documento
- Distilbert Distilbert, una versión destilada de Bert: más pequeño, más rápido, más barato y más ligero , 2019, papel
- Albert Albert: A Lite Bert para el aprendizaje auto-supervisado de las representaciones del idioma , 2019, documento
- Modelo de lenguaje unificado unilm pretruante para la comprensión del lenguaje natural y la generación de la generación de 2019
- Electra Electra: codificadores de texto previos al entrenamiento como discriminadores en lugar de generadores , 2020, papel
- T5 "Explorando los límites del aprendizaje de transferencia con un transformador de texto a texto unificado" . Colin Raffel et al. JMLR 2019. Documento
- GLM "GLM-130B: un modelo pre-entrenado bilingüe abierto" . 2022. Papel
- Alexatm "Alexatm 20B: Aprendizaje de pocos disparos usando un modelo SEQ2SEQ multilingüe a gran escala" . Saleh Soltan et al. arxiv 2022. papel
- ST-MOE ST-MOE: Diseño de modelos de expertos escasos estables y transferibles . Papel 2022
Modelos de idiomas de estilo GPT: solo decodificador
- GPT Mejora de la comprensión del lenguaje mediante la pretraben generativa . 2018. Documento
- Los modelos de idiomas GPT-2 son estudiantes de múltiples tareas no supervisados . 2018. Documento
- GPT-3 "Los modelos de idiomas son alumnos de pocos disparos" . Neurips 2020. Papel
- OPT "OPT: Open Modelos de lenguaje de transformador previamente capacitado" . 2022. Papel
- Palm "Palm: modelado de lenguaje de escala con vías" . Aakanksha Chowdhery et al. arxiv 2022. papel
- Bloom "Bloom: un modelo de lenguaje multilingüe de acceso abierto de 176b-parámetro" . 2022. Papel
- MT-NLG "Uso de Deepeed y Megatron para entrenar a NLG 530B de megatron, un modelo de lenguaje generativo a gran escala" . 2021. Papel
- Glam "glamour: escala eficiente de modelos de lenguaje con mezcla de expertos" . ICML 2022. Papel
- Gopher "Modelos de escala de lenguaje: métodos, análisis e ideas de la capacitación Gopher" . 2021. Papel
- Chinchilla "Modelos de lenguaje grande de computo óptimo" de entrenamiento " . 2022. Papel
- Lamda "Lamda: modelos de idioma para aplicaciones de diálogo" . 2021. Papel
- Llama "Llama: modelos de idiomas de base abiertos y eficientes" . 2023. Papel
- GPT-4 "Informe técnico GPT-4" . 2023. Papel
- Bloombeggpt Bloombergppt: un modelo de lenguaje grande para finanzas , 2023, papel
- GPT-NEOX-20B: "GPT-NOOX-20B: un modelo de lenguaje autorregresivo de código abierto" . 2022. Papel
- Palm 2: "Informe técnico de Palm 2" . 2023. Tech.Report
- Llama 2: "Llama 2: Foundation Open y modelos de chat ajustados" . 2023. Papel
- Claude 2: "Tarjeta modelo y evaluaciones para modelos Claude" . 2023. Tarjeta modelo
Guía práctica para datos
Datos previos a la altura
- Redpajama , 2023. Repo
- La pila: un conjunto de datos de 800 GB de texto diverso para modelado de idiomas , ARXIV 2020. Paper
- ¿Cómo afecta el objetivo de la capacitación previa a lo que aprenden los modelos de lenguaje grande sobre las propiedades lingüísticas? , ACL 2022. Papel
- Leyes de escala para modelos de lenguaje neuronal , 2020. Paper
- Inteligencia artificial centrada en datos: una encuesta , 2023. Paper
- ¿Cómo obtiene GPT su capacidad? Rastreando habilidades emergentes de modelos de idiomas a sus fuentes , 2022. Blog
Datos de finete
- Benchmarking Clasificación de texto de disparo cero: conjuntos de datos, evaluación y enfoque de implicación , EMNLP 2019. Paper
- Los modelos de idiomas son alumnos de pocos disparos , NIPS 2020. Paper
- ¿La generación de datos sintéticos de LLM ayuda a la minería de texto clínico? Arxiv 2023 papel
Prueba de datos/datos del usuario
- Aprendizaje de acceso directo de modelos de lenguaje grande en la comprensión del lenguaje natural: una encuesta , ARXIV 2023. Paper
- Sobre la robustez de ChatGPT: una perspectiva adversaria y desactualizada ARXIV, 2023. Documento
- Supergeglue: un punto de referencia más pegajoso para los sistemas de comprensión de lenguaje de uso general ARXIV 2019. Paper
Guía práctica para tareas de PNL
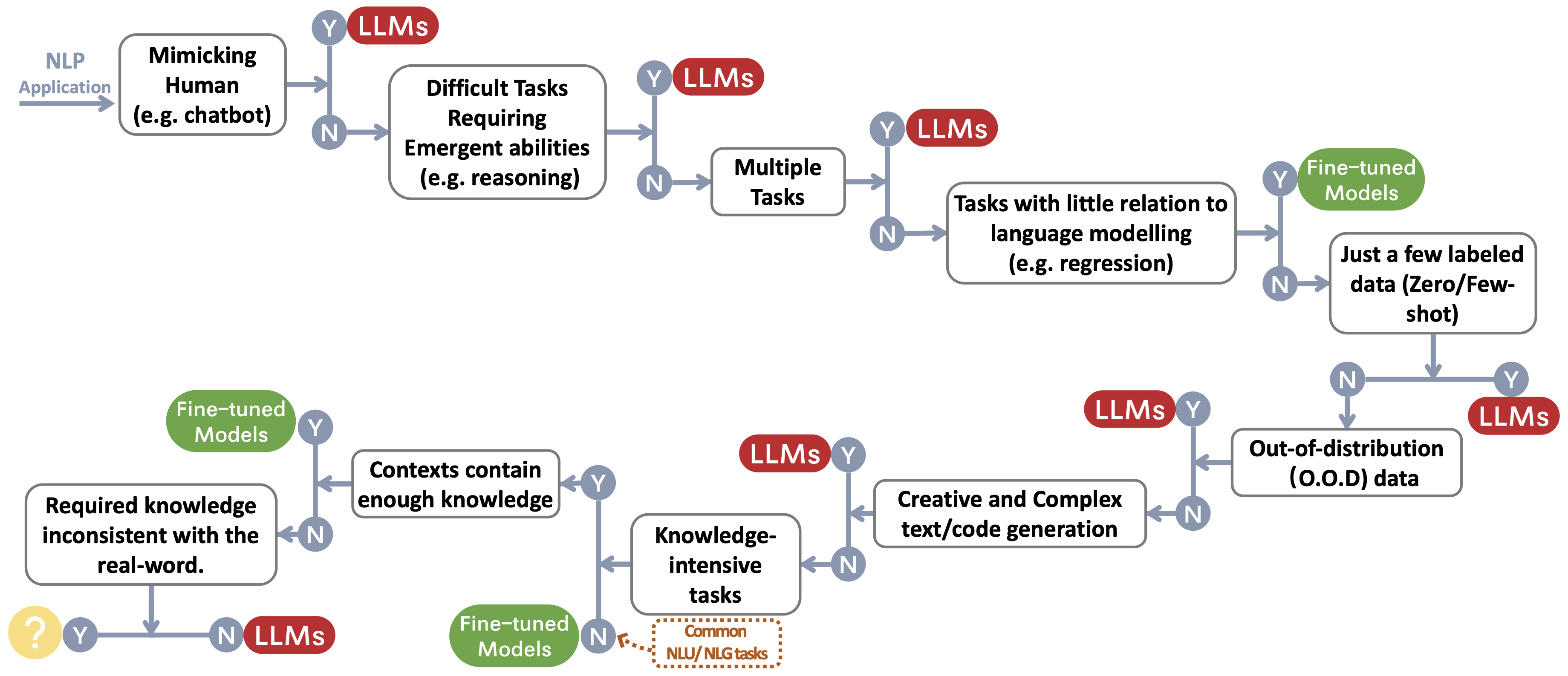
Construimos un flujo de decisión para elegir LLM o modelos ajustados ~ protectora foteTemark para las aplicaciones NLP del usuario. El flujo de decisión ayuda a los usuarios a evaluar si sus aplicaciones NLP aguas abajo cumplen con condiciones específicas y, en base a esa evaluación, determinar si los LLM o los modelos ajustados son la opción más adecuada para sus aplicaciones.
Tareas tradicionales de la NLU
- Un punto de referencia para la clasificación de comentarios tóxicos en el conjunto de datos de comentarios civiles ARXIV 2023 Documento
- ¿Chatgpt es un solucionador de tareas de procesamiento de lenguaje natural de uso general? Arxiv 2023 Paper
- Benchmarking Modelos de idiomas grandes para resumen de noticias ARXIV 2022 Paper
Tareas de generación
- Resumen de noticias y evaluación en la era del documento GPT-3 ARXIV 2022
- ¿Chatgpt es un buen traductor? Sí con GPT-4 como el motor ARXIV 2023 Paper
- Sistemas de traducción automática multilingüe de Microsoft para tarea compartida WMT21 , papel WMT2021
- ¿Chatgpt también puede entender? Un estudio comparativo sobre ChatGPT y Bert , ARXIV 2023, Paper
Tareas intensivas en conocimiento
- Medición de la comprensión masiva del lenguaje multitarea , papel ICLR 2021
- Más allá del juego de imitación: cuantificar y extrapolar las capacidades de los modelos de idiomas , documento ARXIV 2022
- Premio de escala inversa , enlace 2022
- Atlas: aprendizaje de pocos disparos con modelos de lenguaje aumentado de recuperación , documento ARXIV 2022
- Los modelos de idiomas grandes codifican el conocimiento clínico , Arxiv 2022 Paper
Habilidades con escala
- Entrenamiento modelos de lenguaje grande de cómputo , neuripas 2022 papel
- Leyes de escala para modelos de lenguaje neuronal , documento ARXIV 2020
- Resolviendo problemas de palabras matemáticas con retroalimentación basada en procesos y resultados , documento ARXIV 2022
- La cadena de pensamiento provoca razonamiento en modelos de idiomas grandes , Neurips 2022 Paper
- Habilidades emergentes de modelos de idiomas grandes , TMLR 2022 Paper
- La escala inversa puede volverse en forma de U , papel ARXIV 2022
- Hacia el razonamiento en modelos de idiomas grandes: una encuesta , Arxiv 2022 Paper
Tareas específicas
- Imagen como idioma extranjero: preperante para todas las tareas de visión y lenguaje de visión , documento ARIXV 2022
- Pali: un modelo de imagen de lenguaje multilingüe de escala conjunta , papel ARXIV 2022
- AUGGPT: Aprovechando el chatGPT para el aumento de datos de texto , documento ARXIV 2023
- ¿GPT-3 es un buen anotador de datos? , Arxiv 2022 Paper
- ¿Quieres reducir el costo de etiquetado? GPT-3 puede ayudar , EMNLP Findings 2021 Paper
- GPT3MIX: Aprovechando modelos de lenguaje a gran escala para el aumento de texto , Hallazgos de EMNLP 2021 Paper
- LLM para la coincidencia del paciente-juicio: aumento de datos consciente de la privacidad hacia un mejor rendimiento y generalización , documento ARXIV 2023
- ChatGPT supera a los trabajadores de la multitud para tareas de anotación de texto , documento ARXIV 2023
- G-EVAL: Evaluación NLG utilizando GPT-4 con mejor alineación humana , documento ARXIV 2023
- GPTSCORE: Evalúe como desee , documento ARXIV 2023
- Los modelos de idiomas grandes son evaluadores de última generación de la calidad de la traducción , documento ARXIV 2023
- ¿Chatgpt es un buen evaluador NLG? Un estudio preliminar , documento ARXIV 2023
'' Tareas del mundo real '
- Chispas de inteligencia general artificial: primeros experimentos con GPT-4 , documento ARXIV 2023
Eficiencia
- Costo
- Modelo de lenguaje GPT-3 de Openai: una visión general técnica , 2020. Publicación de blog
- Medición de la intensidad de carbono de IA en instancias de nubes , FACCT 2022. Paper
- En AI, ¿es más grande siempre mejor? , Artículo de la naturaleza 2023. Artículo
- Los modelos de idiomas son alumnos de pocos disparos , Neurips 2020. Paper
- Precios , OpenAi. Blog
- Estado latente
- Helm: Evaluación holística de modelos de idiomas , ARXIV 2022. Paper
- Ajuste fino de los parámetros
- Lora: adaptación de bajo rango de modelos de idiomas grandes , ARXIV 2021. Paper
- Autorización de prefijo: optimización de indicaciones continuas para la generación , ACL 2021. Paper
- A-ANUNCIO P: El ajuste de inmediato puede ser comparable al ajuste fino a través de escalas y tareas , ACL 2022. Paper.
- P-ajuste P V2: el ajuste rápido puede ser comparable al ajuste fino universalmente a través de escalas y tareas , ARXIV 2022. Paper.
- Sistema previo
- Cero: Optimizaciones de memoria hacia los modelos de parámetros de billones de entrenamiento , ARXIV 2019. Paper
- Megatron-LM: capacitación de modelos de lenguaje de parámetros multimillonas utilizando paralelismo del modelo , ARXIV 2019. Paper
- Capacitación de modelos de lenguaje a gran escala eficiente en grupos de GPU utilizando Megatron-LM , ARXIV 2021. Paper
- Reducción de la recomputación de activación en modelos de transformadores grandes , ARXIV 2021. Paper
Integridad
- Robustez y calibración
- Calibrar antes de su uso: Mejora del rendimiento de pocos disparos de los modelos de idiomas , ICML 2021. Paper
- Spec: una calibración suave basada en un aviso para mitigar la variabilidad del rendimiento en el resumen de notas clínicas , ARXIV 2023. Paper
- Sesgos espurios
- Los modelos de idiomas grandes pueden ser alumnos perezosos: analizar accesos directos en el aprendizaje en contexto , hallazgos de papel ACL 2023
- Aprendizaje de acceso directo de modelos de idiomas grandes en la comprensión del lenguaje natural: una encuesta , 2023 Papel
- Mitigar el sesgo de género en el sistema de subtítulos , papel www 2020
- Calibrar antes de su uso: Mejora del rendimiento de pocos disparos de los modelos de idiomas , papel ICML 2021
- Aprendizaje de acceso directo en redes neuronales profundas , Nature Machine Intelligence 2020 Paper
- ¿Los modelos basados en el aviso realmente entienden el significado de sus indicaciones? , Naacl 2022 Paper
- Problemas de seguridad
- Tarjeta del sistema GPT-4 , papel 2023
- La ciencia de la detección de textos generados por LLM , documento ARXIV 2023
- Cómo se comparten los estereotipos a través del lenguaje: una revisión e introducción de las categorías aociales y el marco de comunicación de estereotipos (SCSC) , Revisión de la investigación de comunicación, 2019 Papel
- Sombras de género: disparidades de precisión interseccional en la clasificación de género comercial , documento FACCT 2018
Ajuste de instrucciones de referencia
- Flan: los modelos de lenguaje Finetuned son estudiantes de cero disparos , papel arxiv 2021
- T0: la capacitación de múltiples tareas permite la generalización de tareas de disparo cero , documento ARXIV 2021
- Generalización de la tarea cruzada a través de instrucciones de crowdsourcing de lenguaje natural , documento de ACL 2022
- TK-Instructo: Super-NaturalInstructions: Generalización a través de instrucciones declarativas en tareas de más de 1600+ PNLP , EMNLP 2022 Paper
- Flan-T5/Palm: modelos de lenguaje de instrucción de escala , papel ARXIV 2022 Paper
- La recopilación de Flan: Diseño de datos y métodos para un ajuste efectivo de instrucciones , documento ARXIV 2023
- OPT-IML: Meta de aprendizaje de instrucción del modelo de lenguaje de escala a través de la lente de generalización , documento ARXIV 2023
Alineación
- Aprendizaje de refuerzo profundo de las preferencias humanas , NIPS 2017 Paper
- Aprender a resumir de la retroalimentación humana , documento ARXIV 2020
- Un asistente general de idiomas como laboratorio para la alineación , documento ARXIV 2021
- Entrenamiento de un asistente útil e inofensivo con refuerzo aprendiendo de comentarios humanos , documento ARXIV 2022
- Enseñanza de modelos de idiomas para respaldar respuestas con citas verificadas , documento ARXIV 2022
- INSTRUCTGPT: Modelos de lenguaje de capacitación para seguir las instrucciones con comentarios humanos , documento ARXIV 2022
- Mejora de la alineación de los agentes del diálogo a través de juicios humanos dirigidos , documento ARXIV 2022
- Leyes de escala para el modelo de recompensa en exceso de optimización , documento ARXIV 2022
- Supervisión escalable: Medición del progreso en supervisión escalable para modelos de idiomas grandes , documento ARXIV 2022
Alineación de seguridad (inofensiva)
- Modelos de lenguaje de equipo rojo con modelos de idiomas , documento ARXIV 2022
- AI constitucional: inofensiva por retroalimentación de IA , documento ARXIV 2022
- La capacidad de la autocorrección moral en modelos de idiomas grandes , Arxiv 2023 Paper
- OpenAI: Nuestro enfoque para la seguridad de IA , blog 2023
Alineación de veracidad (honesto)
- Aprendizaje de refuerzo para modelos de idiomas , blog 2023
Guías prácticas para solicitar (útil)
- Libro de cocina de Operai . Blog
- Ingeniería rápida . Blog
- Chatgpt Ingeniería rápida para desarrolladores! Curso
Esfuerzos de alineación de la comunicación de código abierto
- Autoestructo: Modelo de lenguaje de alineación con instrucciones autogeneradas , papel ARXIV 2022
- Alpaca . Repositorio
- Vicuna . Repositorio
- Dolly . Blog
- Deepeed-chat . Blog
- GPT4All . Repositorio
- OpenAsitant . Repositorio
- Chatglm . Repositorio
- Musgo . Repositorio
- Lamini . Repositorio/blog
Uso y restricciones
Construimos una tabla que resume las restricciones de uso de LLMS (por ejemplo, por ejemplo, para fines comerciales y de investigación). En particular, proporcionamos la información de los modelos y la perspectiva de sus datos previos al ejercicio. Instamos a los usuarios de la comunidad a que se refieran a la información de licencia para modelos y datos públicos y los usen de manera responsable. Instamos a los desarrolladores a prestar especial atención a las licencias, hacerlos transparentes e integrales, para evitar cualquier uso no deseado e imprevisto.
| LLMS | Modelo | Datos |
|---|
| Licencia | Uso comercial | Otras restricciones notables | Licencia | Cuerpo |
| Solo codificador |
|
| Serie de modelos Bert (dominio general) | Apache 2.0 | ✅ | | Público | BookScorpus, Wikipedia en inglés |
| Roberta | Licencia de MIT | ✅ | | Público | BookCorpus, CC-News, OpenWebText, Historias |
| Ernie | Apache 2.0 | ✅ | | Público | Wikipedia en inglés |
| Escibrí | Apache 2.0 | ✅ | | Público | Bert Corpus, 1.14m documentos de Semantic Scholar |
| Legalbert | CC BY-SA 4.0 | | | Público (excepto datos del proyecto de acceso a la jurisprudencia) | Legislación de la UE, casos de la corte estadounidense, etc. |
| Biobert | Apache 2.0 | ✅ | | Pubmed | PubMed, PMC |
| Codificador |
|
| T5 | Apache 2.0 | ✅ | | Público | C4 |
| Flan-t5 | Apache 2.0 | ✅ | | Público | C4, mezcla de tareas (Fig. 2 en papel) |
| Barbar | Apache 2.0 | ✅ | | Público | Roberta Corpus |
| GLM | Apache 2.0 | ✅ | | Público | Bookscorpus e inglés wikipedia |
| Chatglm | Licencia de chatglm | | Sin uso para fines ilegales o investigación militar, sin dañar el interés público de la sociedad | N / A | 1T Tokens of Chinese and English Corpus |
| Solo decodificador |
| GPT2 | Licencia MIT modificada | ✅ | Use GPT-2 de manera responsable y claramente indica que su contenido se creó usando GPT-2. | Público | Teatro web |
| Gpt-neo | Licencia de MIT | ✅ | | Público | Montón |
| GPT-J | Apache 2.0 | ✅ | | Público | Montón |
| ---> dolly | CC por NC 4.0 | | | CC por NC 4.0, sujeto a los términos de uso de los datos generados por OpenAI | Pila, autoinstruido |
| ---> gpt4all-j | Apache 2.0 | ✅ | | Público | Conjunto de datos GPT4All-J |
| pitia | Apache 2.0 | ✅ | | Público | Montón |
| ---> dolly v2 | Licencia de MIT | ✅ | | Público | Pila, Databricks-Dolly-15k |
| OPTAR | Acuerdo de licencia OPT-175B | | No hay desarrollo relacionado con la investigación de vigilancia y los militares, sin dañar el interés público de la sociedad | Público | Roberta Corpus, la pila, Pushshift.io Reddit |
| ---> opt-iml | Acuerdo de licencia OPT-175B | | Lo mismo para optar | Público | OPT Corpus, Versión extendida de Super-NaturalInstructions |
| Yalm | Apache 2.0 | ✅ | | No especificado | Pila, los equipos recolectaron textos en ruso |
| FLORACIÓN | La licencia de ferrocarril BigScience | ✅ | No es un uso de generar información verificablemente falsa con el propósito de dañar a otros;
contenido sin renunciar expresamente a que el texto se genera la máquina | Público | Roots Corpus (Lauren¸con et al., 2022) |
| ---> BOOMZ | La licencia de ferrocarril BigScience | ✅ | Lo mismo para florecer | Público | Roots Corpus, XP3 |
| Galáctica | CC BY-NC 4.0 | | | N / A | El corpus de Galactica |
| Llama | Licencia a medida no comercial | | No hay desarrollo relacionado con la investigación de vigilancia y los militares, sin dañar el interés público de la sociedad | Público | CommonCrawl, C4, Github, Wikipedia, etc. |
| ---> Alpaca | CC por NC 4.0 | | | CC por NC 4.0, sujeto a los términos de uso de los datos generados por OpenAI | Corpus de Llama, autoinstructo |
| ---> vicuna | CC por NC 4.0 | | | Sujeto a los términos de uso de los datos generados por OpenAI;
Prácticas de privacidad de ShareGPT | Llama Corpus, 70k conversaciones de sharegpt.com |
| ---> gpt4all | GPL Licensed Llama | | | Público | Conjunto de datos GPT4All |
| Abierto | Apache 2.0 | ✅ | | Público | Redpajama |
| CodeGeex | La licencia de codegeex | | Sin uso para fines ilegales o investigación militar | Público | Pila, CodeProt, etc. |
| Codificador de estrellas | Licencia BigCode OpenRail-M V1 | ✅ | No es un uso de generar información verificablemente falsa con el propósito de dañar a otros;
contenido sin renunciar expresamente a que el texto se genera la máquina | Público | La pila |
| MPT-7B | Apache 2.0 | ✅ | | Público | MC4 (inglés), The Stack, Redpajama, S2ORC |
| halcón | Tii Falcon LLM Licencia | ✅/ | Disponible bajo una licencia que permite el uso comercial | Público | Valgada refinada |
Historia de la estrella


