LLMsPracticalGuide
1.0.0
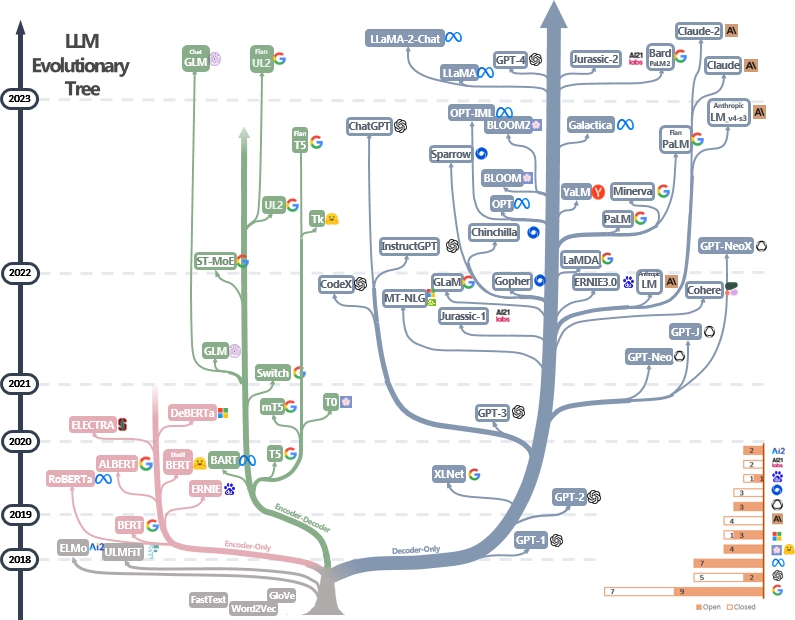
LLMSの実用的なガイドリソースのキュレーションされた(まだアクティブに更新されている)リスト。それは私たちの調査論文に基づいています:実際にLLMSの力を活用する:@xinyaduのChatGptおよびBeyondの調査と努力。調査は、このブログの後半に部分的に基づいています。また、近年の言語モデルの開発を追跡するために、現代の大手言語モデル(LLMS)の進化ツリーを構築し、最もよく知られているモデルのいくつかを強調しています。
これらの情報源は、開業医が大規模な言語モデル(LLM)の広大な景観と、自然言語処理(NLP)アプリケーションでのアプリケーションをナビゲートするのを支援することを目的としています。また、モデルとデータライセンス情報に基づいた使用制限も含めます。リポジトリ内のリソースが役立つ場合は、お気軽に使用してください(私たちの論文を引用することを忘れないでください!?)。この数字を改良するためのプルリクエストを歓迎します!
@article { yang2023harnessing ,
title = { Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond } ,
author = { Jingfeng Yang and Hongye Jin and Ruixiang Tang and Xiaotian Han and Qizhang Feng and Haoming Jiang and Bing Yin and Xia Hu } ,
year = { 2023 } ,
eprint = { 2304.13712 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
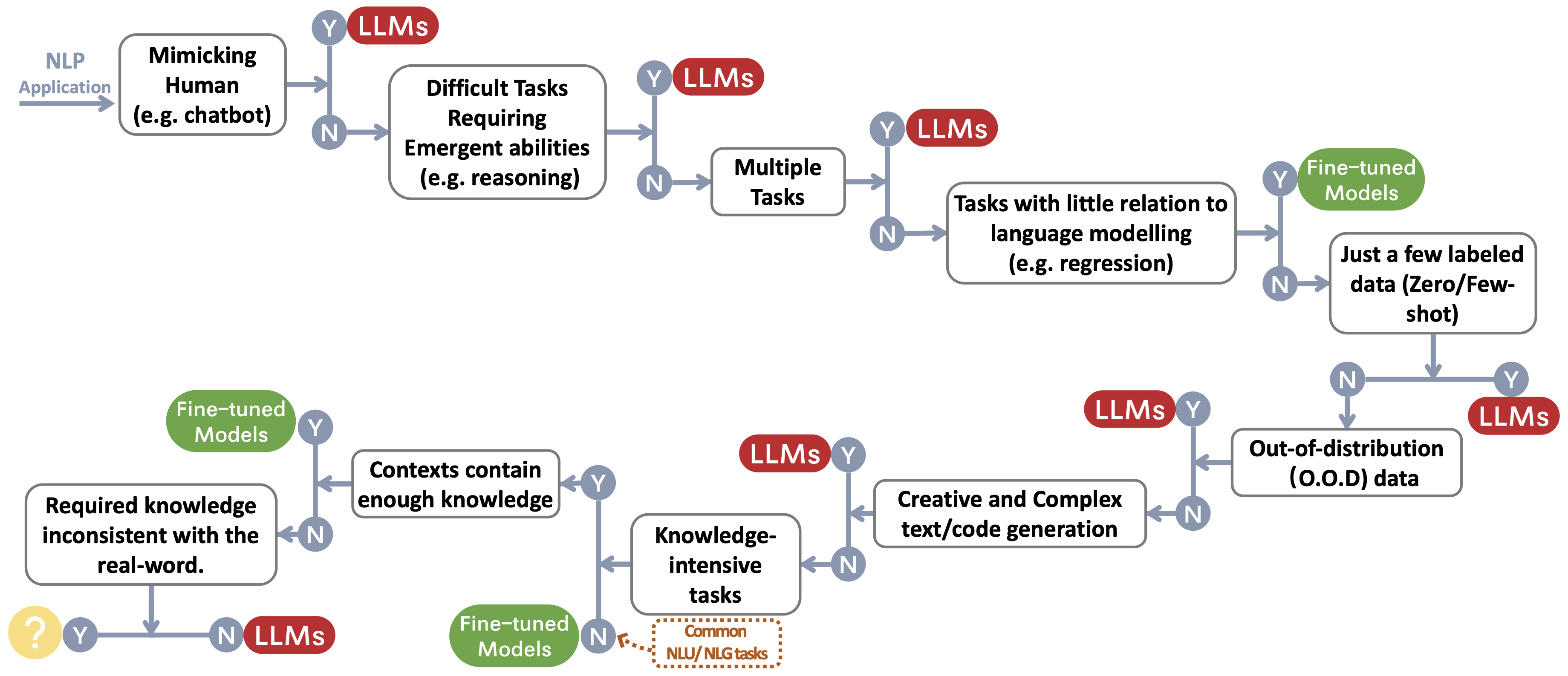
}LLMSまたは微調整されたモデルを選択するための決定フローを構築します〜ユーザーのNLPアプリケーション用のfootnotemarkを保護します。決定フローは、ユーザーが手元の下流のNLPアプリケーションが特定の条件を満たしているかどうかを評価するのに役立ち、その評価に基づいて、LLMSまたは微調整されたモデルがアプリケーションに最も適した選択であるかどうかを判断します。
LLMSの使用制限を要約するテーブルを構築します(たとえば、商業および研究の目的で)。特に、モデルからの情報とその事前販売データの視点を提供します。コミュニティのユーザーに、パブリックモデルとデータのライセンス情報を参照し、責任ある方法で使用するように促します。開発者に、ライセンスに特別な注意を払って、透明で包括的にして、不要で予期せぬ使用を防ぐように促します。
| LLMS | モデル | データ | |||
|---|---|---|---|---|---|
| ライセンス | 商業用 | その他の顕著な制限 | ライセンス | コーパス | |
| エンコーダのみ | |||||
| モデルのバートシリーズ(一般的なドメイン) | Apache 2.0 | ✅ | 公共 | Bookscorpus、英語ウィキペディア | |
| ロベルタ | MITライセンス | ✅ | 公共 | BookCorpus、CC-News、OpenWebtext、Stories | |
| アーニー | Apache 2.0 | ✅ | 公共 | 英語のウィキペディア | |
| Scibert | Apache 2.0 | ✅ | 公共 | Bert Corpus、セマンティック・スカラーの1.14mの論文 | |
| LegalBert | CC by-sa 4.0 | パブリック(判例法アクセスプロジェクトからのデータを除く) | EUの法律、米国の訴訟など | ||
| Biobert | Apache 2.0 | ✅ | PubMed | PubMed、PMC | |
| エンコーダデコーダー | |||||
| T5 | Apache 2.0 | ✅ | 公共 | C4 | |
| flan-t5 | Apache 2.0 | ✅ | 公共 | C4、タスクの混合(紙の図2) | |
| バート | Apache 2.0 | ✅ | 公共 | ロベルタコーパス | |
| GLM | Apache 2.0 | ✅ | 公共 | bookscorpusと英語のウィキペディア | |
| chatglm | Chatglmライセンス | 違法な目的や軍事研究には役に立たず、社会の公益に害を及ぼすことはありません | n/a | 中国語と英語のコーパスの1トークン | |
| デコーダーのみ | |||||
| GPT2 | 変更されたMITライセンス | ✅ | GPT-2を責任を持って使用し、GPT-2を使用してコンテンツが作成されたことを明確に示します。 | 公共 | webtext |
| gpt-neo | MITライセンス | ✅ | 公共 | パイル | |
| GPT-J | Apache 2.0 | ✅ | 公共 | パイル | |
| --->ドリー | NC 4.0によるCC | NC 4.0によるCC、OpenAIによって生成されたデータの使用条件の対象となります | 杭、自己インストラクション | ||
| ---> gpt4all-j | Apache 2.0 | ✅ | 公共 | gpt4all-jデータセット | |
| ピティア | Apache 2.0 | ✅ | 公共 | パイル | |
| ---> Dolly V2 | MITライセンス | ✅ | 公共 | パイル、Databricks-Dolly-15K | |
| Opt | OPT-175Bライセンス契約 | 監視研究と軍事に関連する開発はなく、社会の公益に害を及ぼすことはありません | 公共 | Roberta Corpus、The Pile、Pushshift.io Reddit | |
| ---> opt-iml | OPT-175Bライセンス契約 | オプトと同じです | 公共 | Super-NaturalInstructionsの拡張バージョン、Opt Corpus | |
| ヤルム | Apache 2.0 | ✅ | 不特定 | パイル、チームはロシア語でテキストを収集しました | |
| 咲く | BigScience Railライセンス | ✅ | 他の人を傷つける目的で、検証可能な虚偽の情報を生成することはありません。 テキストがマシンで生成されていることを明示的に否認することなくコンテンツ | 公共 | ルーツコーパス(ローレンコンet al。、2022) |
| ---> Bloomz | BigScience Railライセンス | ✅ | 咲くのと同じ | 公共 | ルーツコーパス、XP3 |
| ギャラクティカ | CC BY-NC 4.0 | n/a | Galactica Corpus | ||
| ラマ | 非営利のオーダーメイドライセンス | 監視研究と軍事に関連する開発はなく、社会の公益に害を及ぼすことはありません | 公共 | CommonCrawl、C4、Github、Wikipediaなど | |
| ---> alpaca | NC 4.0によるCC | NC 4.0によるCC、OpenAIによって生成されたデータの使用条件の対象となります | Llama Corpus、自己内容 | ||
| ---> Vicuna | NC 4.0によるCC | OpenAIによって生成されたデータの使用条件に従います。 Sharegptのプライバシープラクティス | Llama Corpus、Sharegpt.comからの70Kの会話 | ||
| ---> gpt4all | GPLライセンスラマ | 公共 | gpt4allデータセット | ||
| Openllama | Apache 2.0 | ✅ | 公共 | レッドパジャマ | |
| CodeGeex | CodeGeexライセンス | 違法な目的や軍事研究には役に立ちません | 公共 | パイル、コードパローなど | |
| スターコダー | BigCode OpenRail-M V1ライセンス | ✅ | 他の人を傷つける目的で、検証可能な虚偽の情報を生成することはありません。 テキストがマシンで生成されていることを明示的に否認することなくコンテンツ | 公共 | スタック |
| MPT-7B | Apache 2.0 | ✅ | 公共 | MC4(英語)、スタック、Redpajama、S2ORC | |
| ファルコン | TII Falcon LLMライセンス | ✅/ | 商用利用を可能にするライセンスの下で利用可能 | 公共 | 洗練された覚醒 |


