Практические руководства для крупных языковых моделей
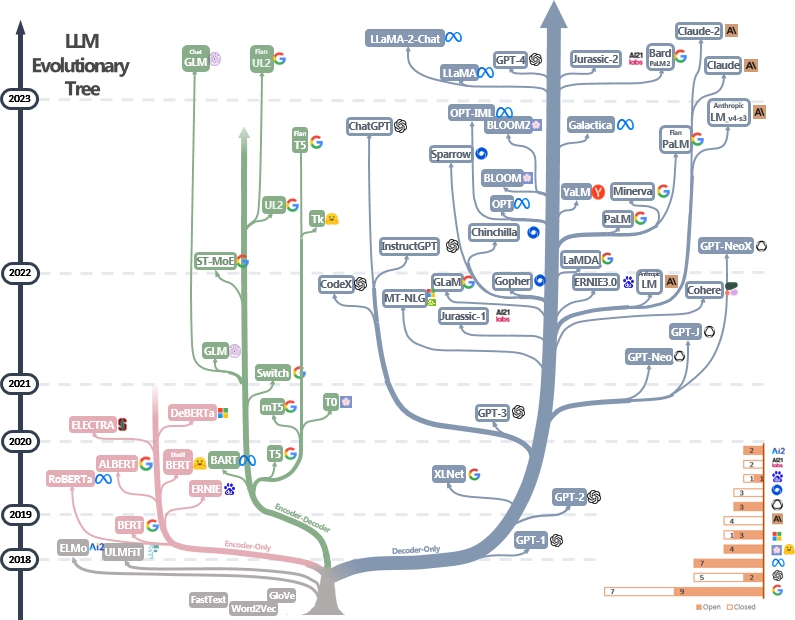
Куратор (все еще активно обновлен) список практических руководств по ресурсам LLMS. Он основан на нашем опросе: используйте силу LLM на практике: опрос по Chatgpt и за его пределами и усилия @xinyadu. Опрос частично основан на второй половине этого блога. Мы также строим эволюционное дерево современных крупных языковых моделей (LLMS), чтобы проследить разработку языковых моделей в последние годы и подчеркивает некоторые из самых известных моделей.
Эти источники направлены на то, чтобы помочь практикующим врачам ориентироваться в обширном ландшафте крупных языковых моделей (LLMS) и их применения в приложениях по обработке естественного языка (NLP). Мы также включаем их ограничения на использование на основе информации о лицензировании модели и данных. Если вы найдете какие -либо ресурсы в нашем репозитории полезными, пожалуйста, не стесняйтесь использовать их (не забудьте процитировать нашу газету!?). Мы приветствуем запросы на привлечение, чтобы уточнить эту фигуру!
@article { yang2023harnessing ,
title = { Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond } ,
author = { Jingfeng Yang and Hongye Jin and Ruixiang Tang and Xiaotian Han and Qizhang Feng and Haoming Jiang and Bing Yin and Xia Hu } ,
year = { 2023 } ,
eprint = { 2304.13712 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}Последние новости?
- Мы добавили раздел использования и ограничений.
- Мы использовали PowerPoint, чтобы построить рисунок и выпустили исходный файл PPTX для нашего GIF -карты. [27.04.2023]
- Мы выпустили исходный файл для неподвижной версии PPTX и заменили фигуру в этом репо все еще. [29.04.2023]
- Добавьте Alexatm, Unilm, Unilmv2 к фигуру и исправьте логотип для TK. [29.04.2023]
- Добавить раздел использования и ограничений (для коммерческих и исследовательских целей). Кредиты доктору Ду. [5/8/2023]
Другие практические руководства для LLMS
- Почему все публичное воспроизведение GPT-3 провалилось? В каких задачах мы должны использовать GPT-3.5/CHATGPT? 2023, блог
- Строительные приложения LLM для производства , 2023, блог
- Искусственный интеллект, ориентированный на данные , 2023, репо/блог/бумага
Каталог
- Практические руководства для крупных языковых моделей
- Практическое руководство для моделей
- Языковые модели в стиле Bert: Encoder-Decoder или Encoder только
- Языковые модели в стиле GPT: только декодер
- Практическое руководство для данных
- Предварительные данные
- Стоимость данных
- Данные тестирования/пользовательские данные
- Практическое руководство для задач НЛП
- Традиционные задачи NLU
- Задачи поколения
- Знание задачи
- Способности с масштабированием
- Конкретные задачи
- Реальные "задачи" '
- Эффективность
- Надежность
- Эталонный настройка инструкций
- Выравнивание
- Выравнивание безопасности (безвредно)
- Выравнивание правдивости (честно)
- Практические руководства по подсказке (полезные)
- Усилия по выравниванию общины с открытым исходным кодом
- Использование и реструктуры (модели и данные)
Практическое руководство для моделей
Языковые модели в стиле Bert: Encoder-Decoder или Encoder только
- Берт Берт: предварительное обучение глубоких двунаправленных трансформаторов для понимания языка , 2018, Paper
- Роберта Роберта: надежно оптимизированный подход Берта, предварительно подготовленный , 2019, Paper
- Distilbert Distilbert, дистиллированная версия Bert: меньше, быстрее, дешевле и легче , 2019, бумага
- Альберт Альберт: Lite Bert для самоуверенного изучения языковых представлений , 2019, Paper
- Unilm Unified Language Model Предварительное обучение для понимания естественного языка и поколения , 2019 г.
- Electra Electra: предварительно тренировочные текстовые кодеры в виде дискриминаторов, а не генераторы , 2020, бумага
- T5 "Изучение пределов обучения передачи с помощью унифицированного трансформатора текста в текст" . Colin Raffel et al. JMLR 2019. Бумага
- GLM "GLM-130B: открытая двуязычная предварительно обученная модель" . 2022. Бумага
- Alexatm "Alexatm 20b: несколько выстрелов с использованием крупномасштабной многоязычной модели SEQ2SEQ" . Салех Солтан и соавт. Arxiv 2022. Бумага
- ST-MEA ST-ME: проектирование стабильных и передаваемых редких экспертных моделей . 2022 бумага
Языковые модели в стиле GPT: только декодер
- GPT улучшает понимание языка за счет генеративного предварительного обучения . 2018. Бумага
- Языковые модели GPT-2-неконтролируемые многозадачные ученики . 2018. Бумага
- Языковые модели GPT-3-это несколько выстрелов » . Neurips 2020. Бумага
- Опт «Опт: открытые предварительно обученные модели языка трансформатора» . 2022. Бумага
- Палм "пальма: масштабирование языка моделирование с помощью путей" . Aakanksha Chowdhery et al. Arxiv 2022. Бумага
- Bloom "Bloom: модель многоязычного языка с открытым доступом 176B-параметра" . 2022. Бумага
- MT-NLG "Использование DeepSpeed и Megatron для обучения Megatron-Tuging NLG 530B, крупномасштабной генеративной языковой модели" . 2021. Бумага
- Гламур "Гламур: эффективное масштабирование языковых моделей с смесью экспертов" . ICML 2022. Бумага
- Gopher "Massing Language Models: методы, анализ и понимание обучения Gopher" . 2021. Бумага
- Чиншилла "тренировка вычислительной оптимальной крупной языковой модели" . 2022. Бумага
- Ламда "Ламда: Языковые модели для диалоговых приложений" . 2021. Бумага
- Лама "Лама: открытые и эффективные языковые модели фундамента" . 2023. Бумага
- GPT-4 "GPT-4 Технический отчет" . 2023. Бумага
- Bloomberggpt bloomberggpt: большая языковая модель для финансов , 2023, Paper
- GPT-NEOX-20B: «GPT-NEOX-20B: модель авторегрессии с открытым исходным кодом» . 2022. Бумага
- Палм 2: «Палм 2 Технический отчет» . 2023. Tech.Report
- Llama 2: «Llama 2: Open Foundation и тонкие модели чата» . 2023. Бумага
- Клод 2: «Модельная карта и оценки для моделей Claude» . 2023. Модель карта
Практическое руководство для данных
Предварительные данные
- Redpajama , 2023. Репо
- Своение: набор данных с разнообразным текстом на 800 ГБ для языкового моделирования , Arxiv 2020. Paper
- Как цель предварительного обучения влияет на то, что крупные языковые модели узнают о лингвистических свойствах? , ACL 2022. Бумага
- Законы масштабирования для моделей нейронного языка , 2020. Бумага
- Искусственный интеллект, ориентированный на данные: опрос , 2023. Бумага
- Как GPT получает свои способности? Отслеживание возникающих способностей языковых моделей в их источниках , 2022. Блог
Стоимость данных
- Сенчатовая классификация с нулевым выстрелом.
- Языковые модели-это несколько выстрелов , NIPS 2020. Бумага
- Помогает ли генерация синтетических данных LLMS клиническое добычу текста? Arxiv 2023 Paper
Данные тестирования/пользовательские данные
- Жесткое изучение моделей крупных языков в понимании естественного языка: опрос , Arxiv 2023. Paper
- О надежности CHATGPT: состязательная и оболочная перспектива Arxiv, 2023.
- SuperGlue: более липкий эталон для систем понимания языка общего назначения Arxiv 2019. Paper
Практическое руководство для задач НЛП
Мы создаем поток принятия решений для выбора LLMS или тонких моделей ~ Protect Feetnotemark для приложений NLP пользователя. Поток принятия решений помогает пользователям оценить, соответствуют ли их нижестоящие приложения NLP на конкретные условия и, основываясь на этой оценке, определяют, являются ли LLMS или тонкие модели, наиболее подходящими для их приложений.
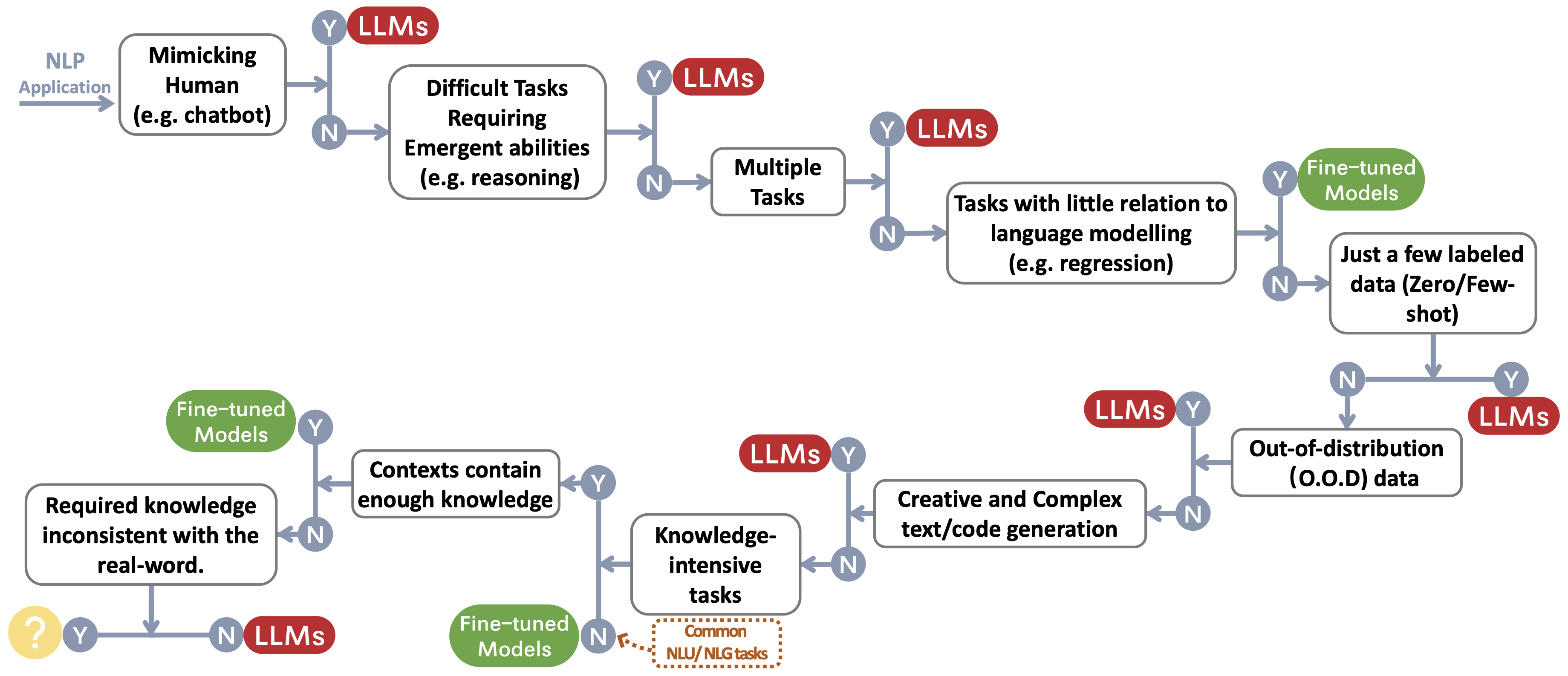
Традиционные задачи NLU
- Основной для классификации токсичных комментариев на набор данных гражданских комментариев Arxiv 2023 Paper
- Является ли CHATGPT-решатель задач обработки естественного языка? Arxiv 2023 бумага
- Брингевы большие языковые модели для суммирования новостей Arxiv 2022 Paper
Задачи поколения
- Суммизация и оценка новостей в эпоху GPT-3 Arxiv 2022
- Catgpt - хороший переводчик? Да с GPT-4 в качестве бумаги Arxiv 2023
- Многоязычные системы машинного перевода от Microsoft для WMT21 Shared Task , WMT2021 Paper
- Может ли тоже понять Chatgpt? Сравнительное исследование CATGPT и тонко настроенного Bert , Arxiv 2023, Paper
Знание задачи
- Измерение массивного понимания многозадачного языка , ICLR 2021 Paper
- Помимо имитационной игры: количественная оценка и экстраполирование возможностей языковых моделей , Arxiv 2022 Paper
- Приз обратного масштабирования , 2022
- Атлас: несколько выстрелов с помощью моделей извлечения на дополнение к извлечению , Arxiv 2022 Paper
- Большие языковые модели кодируют клинические знания , Arxiv 2022 Paper
Способности с масштабированием
- Обучение вычислительной оптимальной большой языковой модели , Neurips 2022 Paper
- Законы масштабирования для моделей нейронного языка , Arxiv 2020 Paper
- Решение задач по математике с обратной связью на основе процессов и результатов , Arxiv 2022 Paper
- Цепочка мышления подсказки вызывает рассуждения в моделях крупных языков , Neurips 2022 Paper
- Эффективные способности крупных языковых моделей , TMLR 2022 Paper
- Обратное масштабирование может стать U-образной формой , Arxiv 2022 Paper
- На пути к рассуждениям в крупных языковых моделях: опрос , Arxiv 2022 Paper
Конкретные задачи
- Изображение как иностранный язык: бейт-предварительная подготовка для всех задач видения и языка зрения , Arixv 2022 Paper
- Пали: совместно масштабированная многоязычная модель языка , Arxiv 2022 Paper
- AUGGPT: использование CHATGPT для увеличения текстовых данных , ARXIV 2023 Paper
- GPT-3-хороший аннотатор данных? , Arxiv 2022 бумага
- Хотите снизить стоимость маркировки? GPT-3 может помочь , выводы EMNLP 2021 Paper
- GPT3MIX: использование крупномасштабных языковых моделей для увеличения текста , выводы EMNLP 2021 Paper
- LLM для сопоставления между пациентами: повышение данных с учетом конфиденциальности в направлении лучшей производительности и обобщения , Arxiv 2023 Paper
- CHATGPT опередиет работников толпы для задач, аннотация текста , Arxiv 2023 Paper
- G-Eval: NLG-оценка с использованием GPT-4 с лучшим выравниванием человека , Arxiv 2023 Paper
- GPTSCORE: оцените по мере желания , Arxiv 2023 Paper
- Большие языковые модели являются современными оценщиками качества перевода , Arxiv 2023 Paper
- Catgpt хорошим оценщиком NLG? Предварительное исследование , Arxiv 2023 Paper
Реальные "задачи" '
- Спарки искусственного общего интеллекта: ранние эксперименты с GPT-4 , Arxiv 2023 Paper
Эффективность
- Расходы
- Языковая модель OpenAI GPT-3: технический обзор , 2020. Пост в блоге
- Измерение интенсивности углерода ИИ в облачных экземплярах , FACCT 2022. Бумага
- В ИИ всегда лучше? , Природа статья 2023 года. Статья
- Языковые модели-это несколько учеников , Neurips 2020. Paper
- Цены , Openai. Пост в блоге
- Задержка
- Хелм: Целостная оценка языковых моделей , Arxiv 2022. Paper
- Параметр-эффективная тонкая настройка
- Лора: Адаптация с низким уровнем моделей крупных языков , Arxiv 2021. Paper
- Настройка префикса: оптимизация непрерывных подсказок для генерации , ACL 2021. Бумага
- P-Tuning: Настройка быстрого настройки может быть сопоставимой с тонкой настройкой по масштабам и задачам , ACL 2022. Бумага
- P-Tuning V2: Настройка быстрого настройки может быть сопоставимой с точной настройкой повсеместно по масштабам и задачам , Arxiv 2022. Paper
- Предварительная система
- Ноль: оптимизация памяти для обучения моделей параметров Trillion , Arxiv 2019. Paper
- Megatron-LM: обучение многомиллиардных моделей языков параметров с использованием модели параллелизма , Arxiv 2019. Paper
- Эффективное крупномасштабное обучение модели языка на кластерах графических процессоров с использованием Megatron-LM , Arxiv 2021. Paper
- Снижение активации реформирования в больших моделях трансформатора , Arxiv 2021. Paper
Надежность
- Надежность и калибровка
- Калибровать перед использованием: улучшение производительности языковых моделей , ICML 2021.
- Спецификация: мягкая калибровка на основе быстрого на основе приглашения при смягчении изменчивости производительности при суммировании клинических заметок , Arxiv 2023. Paper
- Ложные предубеждения
- Модели с большими языками могут быть ленивыми учениками: анализировать ярлыки в обучении в контексте , выводы ACL 2023 Paper
- Яркое обучение на крупных языковых моделях в Понимании естественного языка: опрос , 2023 Paper
- Смягчение гендерного смещения в системе подписания , www 2020 Paper
- Калибровать перед использованием: улучшение производительности языковых моделей , ICML 2021 Paper
- Обучение ярлыку в глубоких нейронных сетях , Paper Nature Machine Intelligence 2020
- Понимают ли быстрые модели смысл их подсказок? , NAACL 2022 бумага
- Проблемы безопасности
- Системная карта GPT-4 , 2023 бумага
- Наука об обнаружении текстов, сгенерированных LLM , Arxiv 2023 Paper
- Как стереотипы передаются на языке: обзор и внедрение структуры Aocial и стереотипов Communication (SCSC) , обзор Communication Research, Paper 2019
- Гендерные оттенки: неравенство точности в межсекции в коммерческой гендерной классификации , FACCT 2018 Paper
Эталонный настройка инструкций
- ФЛАН: МОДЕЛИ МОДЕЛИНАЛЬНЫХ Языков-это ученики с нулевым выстрелом , Arxiv 2021 Paper
- T0: многозадачная подготовка
- Обобщение по перекрестной задаче с помощью инструкций по краудсорсингу естественного языка , ACL 2022 Paper
- TK-Instruct: Super-NaturalInstructions: обобщение с помощью декларативных инструкций по 1600+ задачам NLP , EMNLP 2022 Paper
- FLAN-T5/PALM: масштабирование языковых моделей , ARXIV 2022
- Коллекция FLAN: проектирование данных и методов для эффективной настройки инструкций , Arxiv 2023 Paper
- OPT-IML: Масштабная модель языка.
Выравнивание
- Глубокое подкрепление обучение от человеческих предпочтений , NIPS 2017 Paper
- Обучение суммированию от обратной связи с человеком , Arxiv 2020 Paper
- Общий помощник по языку в качестве лаборатории для выравнивания , Arxiv 2021 Paper
- Обучение полезного и безвредного помощника по подкреплению обучения от обратной связи с человеком , Arxiv 2022 Paper
- Учебные языковые модели для поддержки ответов с проверенными цитатами , Arxiv 2022 Paper
- Инструктор: модели обучения языковым моделям, чтобы следовать инструкциям с отзывами человека , Arxiv 2022 Paper
- Улучшение выравнивания диалоговых агентов с помощью целевых человеческих суждений , Arxiv 2022 Paper
- Законы масштабирования для переоптимизации модели вознаграждения , Arxiv 2022 Paper
- Масштабируемый надзор: измерение прогресса в масштабируемом надзоре за крупными языковыми моделями , Arxiv 2022 Paper
Выравнивание безопасности (безвредно)
- Red Teaming Language Models с языковыми моделями , Arxiv 2022 Paper
- Конституционный AI: безвредность от обратной связи AI , Arxiv 2022 Paper
- Способность к моральной самокоррекции в моделях крупных языков , Arxiv 2023 Paper
- OpenAI: наш подход к безопасности ИИ , блог 2023
Выравнивание правдивости (честно)
- Подкрепление обучения для языковых моделей , блог 2023
Практические руководства по подсказке (полезные)
- Поваренная книга Openai . Блог
- Оперативная инженерия . Блог
- CHATGPT приглашенная инженерия для разработчиков! Курс
Усилия по выравниванию общины с открытым исходным кодом
- Самоубийство: выравнивание языковой модели с самого сгенерированными инструкциями , Arxiv 2022 Paper
- Альпака . Репо
- Викуна . Репо
- Долли . Блог
- Темно-скорость-чат . Блог
- GPT4ALL . Репо
- Открытый . Репо
- Чатглм . Репо
- Мох . Репо
- Ламини . Репо/блог
Использование и ограничения
Мы строим таблицу, обобщающая ограничения на использование LLMS (например, для коммерческих и исследовательских целей). В частности, мы предоставляем информацию из моделей и перспективы их предварительных данных. Мы призываем пользователей в сообществе обратиться к информации лицензирования для публичных моделей и данных и использовать их ответственным образом. Мы призываем разработчиков уделять особое внимание лицензированию, сделать их прозрачными и всеобъемлющими, предотвратить любое нежелательное и непредвиденное использование.
| LLMS | Модель | Данные |
|---|
| Лицензия | Коммерческое использование | Другие заметные ограничения | Лицензия | Корпус |
| Только энкодер |
|
| Берт серия моделей (общий домен) | Apache 2.0 | ✅ | | Публичный | BookScorpus, английская Википедия |
| Роберта | MIT Лицензия | ✅ | | Публичный | BookCorpus, CC-News, OpenWebText, истории |
| ЭРНИ | Apache 2.0 | ✅ | | Публичный | Английская Википедия |
| Скиберт | Apache 2.0 | ✅ | | Публичный | BERT CORPUS, 1,14 млн. Документ от Semantic Scholar |
| Legalbert | CC BY-SA 4.0 | | | Общественность (кроме данных из проекта доступа к прецедентному праву) | Законодательство ЕС, судебные дела США и т. Д. |
| Биоберт | Apache 2.0 | ✅ | | PubMed | PubMed, PMC |
| Энкодер-декодер |
|
| T5 | Apache 2.0 | ✅ | | Публичный | C4 |
| Flan-T5 | Apache 2.0 | ✅ | | Публичный | C4, смесь задач (рис. 2 в бумаге) |
| БАРТ | Apache 2.0 | ✅ | | Публичный | Роберта Корпус |
| GLM | Apache 2.0 | ✅ | | Публичный | Bookscorpus и английская Википедия |
| Чатглм | Чатглм лицензия | | Бесполезно для незаконных целей или военных исследований, не вредит общественным интересам общества | N/a | 1t токены китайского и английского корпуса |
| Только декодер |
| GPT2 | Измененная лицензия MIT | ✅ | Используйте GPT-2 ответственно и четко укажите, что ваш контент был создан с использованием GPT-2. | Публичный | Веб -текст |
| GPT-neo | MIT Лицензия | ✅ | | Публичный | Куча |
| GPT-J | Apache 2.0 | ✅ | | Публичный | Куча |
| ---> Долли | CC от NC 4.0 | | | CC от NC 4.0, при условии использования данных, сгенерированных OpenAI | Своя, самозащитная конструкция |
| ---> gpt4all-j | Apache 2.0 | ✅ | | Публичный | Набор данных GPT4ALL-J |
| Пифия | Apache 2.0 | ✅ | | Публичный | Куча |
| ---> Долли V2 | MIT Лицензия | ✅ | | Публичный | Свои, DataBricks-Dolly-15K |
| Опт | Лицензионное соглашение OPT-175B | | Нет развития, связанного с исследованиями наблюдения и вооруженных сил, нет вреда общественным интересам общества | Публичный | Роберта Корпус, Своение, pushishift.io reddit |
| ---> Opt-Iml | Лицензионное соглашение OPT-175B | | То же самое, чтобы выбрать | Публичный | Opt Corpus, расширенная версия Super-NaturalInstructions |
| Ялм | Apache 2.0 | ✅ | | Неуказано | Куча, команды собирали тексты на русском языке |
| ЦВЕСТИ | Лицензия Bigscience Rail | ✅ | Без использования генерации ложной информации с целью причинения вреда другим;
Контент без явно не отказываясь от того, что текст генерируется машиной | Публичный | Корпус корней (Lauren¸con et al., 2022) |
| ---> Блумз | Лицензия Bigscience Rail | ✅ | То же самое, чтобы расцвести | Публичный | Корпус Корпус, XP3 |
| Галактика | CC BY-NC 4.0 | | | N/a | Галактика Корпус |
| Лама | Некоммерческая лицензия на заказ | | Нет развития, связанного с исследованиями наблюдения и вооруженных сил, нет вреда общественным интересам общества | Публичный | Commoncrawl, C4, Github, Wikipedia и т. Д. |
| ---> Альпака | CC от NC 4.0 | | | CC от NC 4.0, при условии использования данных, сгенерированных OpenAI | Llama Corpus, самостоятельная конструкция |
| ---> Викуна | CC от NC 4.0 | | | С учетом условий использования данных, сгенерированных OpenAI;
Практика конфиденциальности ShareGPT | Llama Corpus, 70 тыс. Разговоры с sharegpt.com |
| ---> gpt4all | GPL Licensed Llama | | | Публичный | Набор данных GPT4ALL |
| Openllama | Apache 2.0 | ✅ | | Публичный | Редпаджама |
| Codegeex | Лицензия Codegeex | | Бесполезно для незаконных целей или военных исследований | Публичный | Куча, кодекарт и т. Д. |
| StarCoder | Лицензия BigCode OpenRail-M v1 | ✅ | Без использования генерации ложной информации с целью причинения вреда другим;
Контент без явно не отказываясь от того, что текст генерируется машиной | Публичный | Стек |
| MPT-7B | Apache 2.0 | ✅ | | Публичный | MC4 (английский), стек, redpajama, s2orc |
| Сокол | TII Falcon LLM Лицензия | ✅/ | Доступно по лицензии, разрешающему коммерческое использование | Публичный | RefinedWeb |
Звездная история


