대형 언어 모델의 실용 가이드
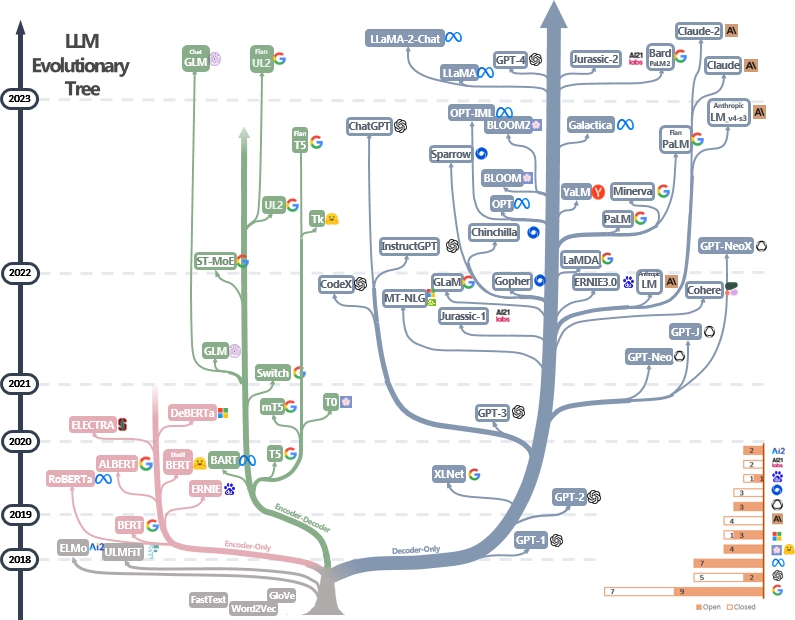
LLM의 실제 가이드 리소스의 선별 된 (아직도 적극적으로 업데이트 된) 목록. 설문 조사 논문을 기반으로합니다. 실제로 LLM의 힘을 활용 : Chatgpt에 대한 설문 조사 및 @xinyadu의 노력. 설문 조사는이 블로그의 후반부를 부분적으로 기반으로합니다. 우리는 또한 최근 몇 년 동안 언어 모델의 개발을 추적하고 가장 잘 알려진 모델을 강조하기 위해 현대적인 대형 언어 모델 (LLM)의 진화 트리를 구축합니다.
이 소스는 실무자들이 LLM (Large Language Model)의 광대 한 환경과 NLP (Natural Language Processing) 응용 프로그램의 응용 프로그램을 탐색하는 데 도움이됩니다. 또한 모델 및 데이터 라이센스 정보를 기반으로 한 사용 제한을 포함합니다. 저장소에서 도움이되는 리소스를 찾으면 자유롭게 사용하십시오 (논문을 인용하는 것을 잊지 마십시오!?). 이 그림을 개선하기위한 풀 요청을 환영합니다!
@article { yang2023harnessing ,
title = { Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond } ,
author = { Jingfeng Yang and Hongye Jin and Ruixiang Tang and Xiaotian Han and Qizhang Feng and Haoming Jiang and Bing Yin and Xia Hu } ,
year = { 2023 } ,
eprint = { 2304.13712 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
}최신 뉴스?
- 사용 및 제한 섹션을 추가했습니다.
- 우리는 PowerPoint를 사용하여 그림을 플로팅하고 GIF 그림에 대한 소스 파일 PPTX를 공개했습니다. [4/27/2023]
- 우리는 Still 버전 PPTX의 소스 파일을 출시 하고이 리포지어의 그림을 Still 버전으로 바 꾸었습니다. [4/29/2023]
- Alexatm, Unilm, Unilmv2를 그림에 추가하고 TK의 로고를 수정하십시오. [4/29/2023]
- 사용 및 제한 (상업 및 연구 목적) 섹션을 추가하십시오. Dr. du에 대한 크레딧. [5/8/2023]
LLM에 대한 기타 실용 가이드
- GPT-3의 모든 대중 재생산이 실패한 이유는 무엇입니까? GPT-3.5/chatgpt를 사용해야하는 작업은 무엇입니까? 2023, 블로그
- 생산을위한 LLM 애플리케이션 구축 , 2023, 블로그
- 데이터 중심 인공 지능 , 2023, Repo/Blog/Paper
목록
- 대형 언어 모델의 실용 가이드
- 모델을위한 실용 가이드
- 버트 스타일 언어 모델 : 인코더 디코더 또는 인코더 전용
- GPT 스타일 언어 모델 : 디코더 전용
- 데이터를위한 실용 가이드
- 사전 배치 데이터
- 미세 조정 데이터
- 테스트 데이터/사용자 데이터
- NLP 작업을위한 실용 가이드
- 전통적인 NLU 작업
- 세대 작업
- 지식 집약적 인 작업
- 스케일링 기능
- 특정 작업
- 실제``작업 ''
- 능률
- 신뢰성
- 벤치 마크 명령 튜닝
- 조정
- 안전 조정 (무해함)
- 진실성 정렬 (정직)
- 프롬프트를위한 실용 안내서 (도움이)
- 오픈 소스 커뮤니케이션의 조정 노력
- 사용 및 제한 (모델 및 데이터)
모델을위한 실용 가이드
버트 스타일 언어 모델 : 인코더 디코더 또는 인코더 전용
- Bert Bert : 언어 이해를위한 깊은 양방향 변압기의 사전 훈련 , 2018, 종이
- Roberta Roberta : 강력하게 최적화 된 Bert Pretraining 접근 , 2019, Paper
- Distilbert Distilbert, Bert의 증류 된 버전 : 작고, 빠르고, 저렴하며 가벼워 , 2019, 종이
- Albert Albert : 언어 표현에 대한 자체 감독 학습을위한 라이트 버트 , 2019, 종이
- UNILM Unified Language Model 자연어 이해 및 세대를위한 사전 훈련 , 2019 논문
- Electra Electra : 발전기보다는 판별 자로서 사전 훈련 텍스트 인코더 , 2020, 종이
- T5 "통합 텍스트-텍스트 변압기로 전송 학습의 한계를 탐색합니다." 콜린 래퍼 et al. JMLR 2019. 종이
- GLM "GLM-130B : 개방형 이중 언어 미리 훈련 된 모델" . 2022. 종이
- Alexatm "Alexatm 20B : 대규모 다국어 SEQ2Seq 모델을 사용한 소수의 학습" . Saleh Soltan et al. Arxiv 2022. 종이
- ST-MOE ST-MOE : 안정적이고 전송 가능한 스파 스 전문간 모델을 설계합니다 . 2022 종이
GPT 스타일 언어 모델 : 디코더 전용
- GPT 생성 사전 훈련에 의한 언어 이해 향상 . 2018. 종이
- GPT-2 언어 모델은 감독되지 않은 멀티 태스킹 학습자입니다 . 2018. 종이
- GPT-3 "언어 모델은 소수의 학습자입니다." Neurips 2020. 종이
- opt "opt : 사전 훈련 된 변압기 언어 모델 열기" . 2022. 종이
- Palm "Palm : 경로로 언어 모델링을 스케일링" . Aakanksha Chowdhery et al. Arxiv 2022. 종이
- Bloom "Bloom : 176b 패러마 미터 오픈 액세스 다국어 언어 모델" . 2022. 종이
- MT-NLG "대규모 생성 언어 모델 인 Megatron-Turing NLG 530B를 훈련시키기 위해 DeepSpeed 및 Megatron을 사용합니다." 2021. 종이
- Glam "Glam : 혼합 된 언어 모델의 효율적인 스케일링" . ICML 2022. 용지
- Gopher "언어 모델 스케일링 : Gopher 훈련의 방법, 분석 및 통찰력" . 2021. 종이
- Chinchilla "훈련 컴퓨팅 최적의 대형 언어 모델" . 2022. 종이
- Lamda "Lamda : 대화 응용 프로그램을위한 언어 모델" . 2021. 종이
- 라마 "라마 : 개방적이고 효율적인 기초 언어 모델" . 2023. 종이
- GPT-4 "GPT-4 기술 보고서" . 2023. 종이
- Bloomberggpt Bloomberggpt : 금융을위한 큰 언어 모델 , 2023, 종이
- GPT-NEOX-20B : "GPT-NEOX-20B : 오픈 소스 자동 회귀 언어 모델" . 2022. 종이
- Palm 2 : "Palm 2 기술 보고서" . 2023. Tech. Report
- 라마 2 : "라마 2 : 오픈 파운데이션 및 미세 조정 된 채팅 모델" . 2023. 종이
- 클로드 2 : "클로드 모델에 대한 모델 카드 및 평가" . 2023. 모델 카드
데이터를위한 실용 가이드
사전 배치 데이터
- 레드 파자마 , 2023. Repo
- 더미 : 언어 모델링을위한 다양한 텍스트의 800GB 데이터 세트 , ARXIV 2020.
- 사전 훈련 목표는 언어 적 특성에 대해 큰 언어 모델에 어떤 영향을 미칩니 까? , ACL 2022. 용지
- 신경 언어 모델의 스케일링 법 , 2020. 종이
- 데이터 중심 인공 지능 : 설문 조사 , 2023. 논문
- GPT는 어떻게 능력을 얻습니까? 언어 모델의 출현 능력 추적 , 2022 년. 블로그
미세 조정 데이터
- 제로 샷 텍스트 분류 벤치마킹 : 데이터 세트, 평가 및 수입 접근 방식 , EMNLP 2019. 용지
- 언어 모델은 소수의 학습자 , NIPS 2020. 종이입니다
- LLM의 합성 데이터 생성이 임상 텍스트 마이닝에 도움이됩니까? Arxiv 2023 종이
테스트 데이터/사용자 데이터
- 자연어 이해에서 대형 언어 모델의 바로 가기 학습 : 설문 조사 , ARXIV 2023. 논문
- chatgpt의 견고성 : 2023 년의 적대적이고 배포되지 않은 관점 Arxiv. 논문.
- SuperGlue : 일반적인 목적 언어 이해 시스템을위한 끈적 끈적한 벤치 마크 ARXIV 2019.
NLP 작업을위한 실용 가이드
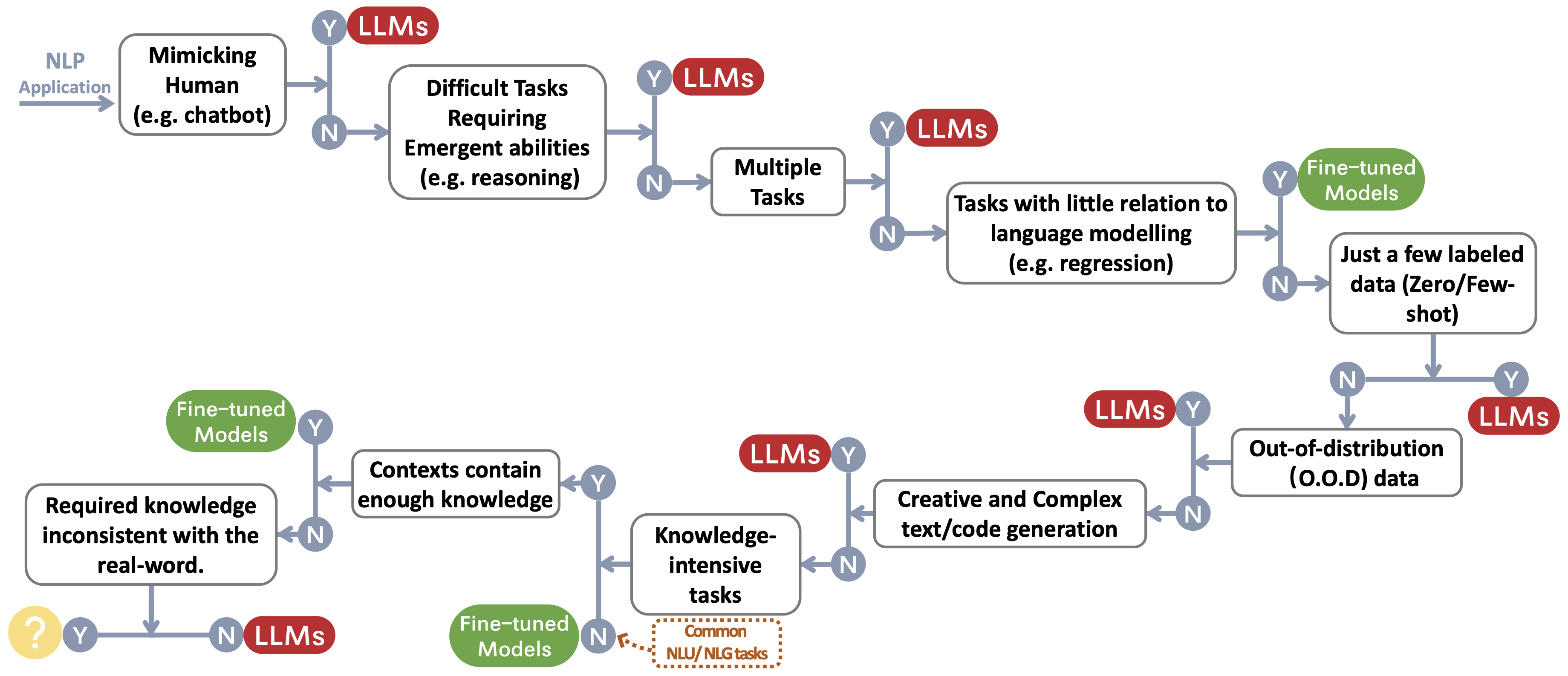
우리는 사용자의 NLP 응용 프로그램을 위해 LLM 또는 미세 조정 모델 ~ Protect Footnotemark를 선택하기위한 결정 흐름을 구축합니다. 의사 결정 흐름은 사용자가 자신의 다운 스트림 NLP 응용 프로그램이 특정 조건을 충족하는지 여부를 평가하고 해당 평가에 따라 LLM 또는 미세 조정 모델이 응용 프로그램에 가장 적합한 선택인지 결정하는 데 도움이됩니다.
전통적인 NLU 작업
- 민사 의견 데이터 세트 ARXIV 2023 논문에 대한 독성 의견 분류 벤치 마크
- Chatgpt는 일반 목적 자연 언어 처리 작업 솔버입니까? Arxiv 2023paper
- 뉴스 요약을위한 대형 언어 모델 벤치마킹 ARXIV 2022 PAPER
세대 작업
- GPT-3 ARXIV 2022 PAPER 시대의 뉴스 요약 및 평가
- Chatgpt는 좋은 번역가입니까? 예, GPT-4를 엔진 ARXIV 2023 용지로 사용합니다
- WMT21 공유 작업, WMT2021 논문 용 Microsoft의 다국어 기계 번역 시스템
- Chatgpt도 이해할 수 있습니까? Chatgpt 및 미세 조정 된 Bert에 대한 비교 연구 , Arxiv 2023, 종이
지식 집약적 인 작업
- 대규모 멀티 태스킹 언어 이해 측정 , ICLR 2021 용지
- 모방 게임 이외 : 언어 모델의 능력을 정량화하고 외삽, Arxiv 2022 Paper
- 역 스케일링 상 , 2022 링크
- 아틀라스 : 검색어 증강 언어 모델을 사용한 소수의 학습 , ARXIV 2022 PAPER
- 대형 언어 모델은 임상 지식 인코딩 , ARXIV 2022 PAPER
스케일링 기능
- 훈련 컴퓨팅 최적의 대형 언어 모델 , Neurips 2022 용지
- 신경 언어 모델에 대한 스케일링 법 , ARXIV 2020 종이
- 프로세스 및 결과 기반 피드백으로 수학 단어 문제 해결 , ARXIV 2022 PAPER
- 프롬프트의 사슬이 큰 언어 모델, Neurips 2022 논문에서 추론을 유발합니다.
- 대형 언어 모델의 출현 능력 , TMLR 2022 종이
- 역 스케일링은 u 자형, Arxiv 2022 용지가 될 수 있습니다
- 대형 언어 모델의 추론을 향해 : 설문 조사 , ARXIV 2022 PAPER
특정 작업
- 외국어로서의 이미지 : 모든 비전 및 비전 언어 작업에 대한 사전 여지 , ARIXV 2022 PAPER
- PALI : 공동 스케일 다국어 언어 이미지 모델 , ARXIV 2022 PAPER
- AugGpt : 텍스트 데이터 확대를위한 chatgpt 활용 , ARXIV 2023 PAPER
- GPT-3은 좋은 데이터 주석이 있습니까? , Arxiv 2022 종이
- 라벨링 비용을 줄이고 싶습니까? GPT-3은 도움이 될 수 있습니다 . EMNLP 발견 2021 용지
- gpt3mix : 텍스트 확대를위한 대규모 언어 모델 활용 , EMNLP 발견 2021 논문
- LLM 환자-트리얼 매칭 : 더 나은 성능 및 일반화를 향한 개인 정보 보유 데이터 확대 , ARXIV 2023 PAPER
- chatgpt는 텍스트 나누기 작업에 대한 군중 노동자보다 우수합니다 .
- G-Eval : 더 나은 인간 정렬을 가진 GPT-4를 사용한 NLG 평가 , ARXIV 2023 PAPER
- GPTSCORE : 원하는대로 평가 , ARXIV 2023 용지
- 대형 언어 모델은 번역 품질의 최첨단 평가자 , ARXIV 2023 PAPER입니다.
- Chatgpt는 좋은 NLG 평가자입니까? 예비 연구 , Arxiv 2023 종이
실제``작업 ''
- 인공 일반 정보의 불꽃 : GPT-4를 사용한 초기 실험 , ARXIV 2023 PAPER
능률
- 비용
- OpenAi의 GPT-3 언어 모델 : 기술 개요 , 2020. 블로그 게시물
- 클라우드 인스턴스에서 AI의 탄소 강도 측정 , FACCT 2022. 용지
- AI에서는 항상 더 낫습니까? , 자연 기사 2023. 기사
- 언어 모델은 소수의 학습자 , Neurips 2020. 종이입니다
- 가격 , Openai. 블로그 게시물
- 숨어 있음
- 헬름 : 언어 모델의 전체적인 평가 , ARXIV 2022.
- 매개 변수 효율적인 미세 조정
- LORA : 대형 언어 모델의 저 순위 적응 , ARXIV 2021. 용지
- 접두사 조정 : 세대를위한 연속 프롬프트 최적화 , ACL 2021.
- P-TUNING : 신속한 튜닝은 스케일 및 작업에 걸친 미세 조정과 비교할 수 있습니다 . ACL 2022.
- P- 튜닝 v2 : 프롬프트 튜닝은 스케일과 작업에 걸쳐 보편적으로 미세 조정과 비교할 수 있습니다 . Arxiv 2022.
- 사전 계약 시스템
- 0 : 훈련 1 조 매개 변수 모델에 대한 메모리 최적화 , ARXIV 2019. 용지
- Megatron-LM : 모델 병렬 처리, ARXIV 2019를 사용한 수십억 개의 매개 변수 언어 모델 교육.
- Megatron-LM, ARXIV 2021을 사용한 GPU 클러스터에 대한 효율적인 대규모 언어 모델 교육.
- 대형 변압기 모델에서 활성화 재 계산 감소 , ARXIV 2021. 용지
신뢰성
- 견고성과 교정
- 사용하기 전에 교정 : 언어 모델의 소수의 성능 향상 , ICML 2021. 용지
- 사양 : 임상 음표의 성능 변동성을 완화하는 것에 대한 소프트 프롬프트 기반 교정 요약 , ARXIV 2023.
- 가짜 편견
- 대형 언어 모델이 게으른 학습자 일 수 있습니다 : 텍스트 내 학습의 단축키 , ACL 2023 논문의 발견
- 자연어 이해에서 대형 언어 모델의 바로 가기 학습 : 설문 조사 , 2023 논문
- 캡션 시스템의 성 편견 완화 , www 2020 종이
- 사용 전 교정 : 언어 모델의 소수의 성능 향상 , ICML 2021 Paper
- 깊은 신경망에서의 바로 가기 학습 , 자연 기계 인텔리전스 2020 종이
- 프롬프트 기반 모델은 프롬프트의 의미를 실제로 이해합니까? , NAACL 2022 종이
- 안전 문제
- GPT-4 시스템 카드 , 2023 종이
- LLM 생성 텍스트 탐지 과학 , Arxiv 2023 논문
- 언어를 통해 고정 관념을 공유하는 방법 : Aocial 범주 및 고정 관념 커뮤니케이션 (SCSC) 프레임 워크, 커뮤니케이션 연구 검토, 2019 논문의 검토 및 소개
- 젠더 음영 : 상업적 성별 분류의 교차 정확도 불균형 , FACCT 2018 논문
벤치 마크 명령 튜닝
- FLAN : Finetuned Language Models는 제로 샷 학습자 , ARXIV 2021 PAPER입니다.
- T0 : 멀티 태스킹 프롬프트 교육은 제로 샷 작업 일반화, ARXIV 2021 논문을 가능하게합니다 .
- 자연어 크라우드 소싱 지침을 통한 교차 작업 일반화 , ACL 2022 논문
- TK-Instruct : 초음파 인 스트루션 : 1600+ NLP 작업에 대한 선언 지침을 통한 일반화 , EMNLP 2022 Paper
- FLAN-T5/PALM : 스케일링 명령-결절 언어 모델 , ARXIV 2022 용지
- FLAN 컬렉션 : 효과적인 교육 튜닝을위한 데이터 및 방법 설계 , ARXIV 2023 PAPER
- OPT-IML : 일반화 렌즈를 통한 언어 모델 교육 메타 학습 , ARXIV 2023 PAPER
조정
- 인간 선호도로부터의 깊은 강화 학습 , NIPS 2017 논문
- 인간의 피드백에서 요약하는 법 배우기 , Arxiv 2020 Paper
- 조정 실험실로서 일반 언어 보조원 , ARXIV 2021 PAPER
- 인간 피드백으로부터 강화 학습을 통해 도움이되고 무해한 조수 훈련 , Arxiv 2022 Paper
- 검증 된 따옴표로 답변을 지원하기위한 언어 모델 교육 , Arxiv 2022 종이
- InstructGpt : 인간 피드백으로 지시를 따르는 언어 모델 , ARXIV 2022 PAPER
- 대상 인간 판단을 통한 대화 에이전트의 조정 개선 , ARXIV 2022 PAPER
- 보상 모델과 최적화를위한 스케일링 법 , ARXIV 2022 논문
- 확장 가능한 감독 : 대형 언어 모델에 대한 확장 가능한 감독의 진행 상황 , ARXIV 2022 PAPER
안전 조정 (무해함)
- 언어 모델이있는 빨간 팀 언어 모델 , Arxiv 2022 종이
- 헌법 AI : AI 피드백, ARXIV 2022 논문의 무해함
- 대형 언어 모델에서 도덕적 자기 수정 능력 , ARXIV 2023 PAPER
- Openai : AI Safety에 대한 우리의 접근 , 2023 블로그
진실성 정렬 (정직)
- 언어 모델에 대한 강화 학습 , 2023 블로그
프롬프트를위한 실용 안내서 (도움이)
- Openai 요리 책 . 블로그
- 프롬프트 엔지니어링 . 블로그
- 개발자를위한 ChatGpt 프롬프트 엔지니어링! 강의
오픈 소스 커뮤니케이션의 조정 노력
- 자체 강조 : 자체 생성 지침과 언어 모델을 정렬 , ARXIV 2022 PAPER
- 알파카 . 레포
- 비쿠나 . 레포
- 돌리 . 블로그
- 깊은 속도 chat . 블로그
- gpt4all . 레포
- OpenAsSitant . 레포
- chatglm . 레포
- 이끼 . 레포
- 라미니 . 리포/블로그
사용 및 제한
우리는 LLMS 사용 제한 (예 : 상업 및 연구 목적)을 요약 한 표를 구축합니다. 특히, 우리는 모델의 정보와 해독 데이터의 관점을 제공합니다. 우리는 커뮤니티 사용자가 공개 모델 및 데이터에 대한 라이센스 정보를 참조하고 책임있는 방식으로 사용하도록 촉구합니다. 우리는 개발자가 라이센스에 특별한주의를 기울이고, 원치 않는 예상치 못한 사용을 방지하기 위해 면허에 특별한주의를 기울이고 투명하고 포괄적으로 만들 것을 촉구합니다.
| LLMS | 모델 | 데이터 |
|---|
| 특허 | 상업적 사용 | 다른 주목할만한 제한 | 특허 | 신체 |
| 인코더 전용 |
|
| 버트 시리즈의 모델 (일반 도메인) | 아파치 2.0 | ✅ | | 공공의 | BookScorpus, 영어 Wikipedia |
| 로베르타 | MIT 라이센스 | ✅ | | 공공의 | BookCorpus, CC-News, OpenWebText, 이야기 |
| 어니 | 아파치 2.0 | ✅ | | 공공의 | 영어 Wikipedia |
| Scibert | 아파치 2.0 | ✅ | | 공공의 | Bert Corpus, Semantic Scholar의 1.14m 논문 |
| legalbert | CC BY-SA 4.0 | | | 공개 (Case Law Access Project의 데이터 제외) | EU 법률, 미국 법원 사건 등 |
| Biobert | 아파치 2.0 | ✅ | | PubMed | PubMed, PMC |
| 인코더 디코더 |
|
| T5 | 아파치 2.0 | ✅ | | 공공의 | C4 |
| FLAN-T5 | 아파치 2.0 | ✅ | | 공공의 | C4, 작업 혼합 (종이 2) |
| 바트 | 아파치 2.0 | ✅ | | 공공의 | 로베르타 코퍼스 |
| GLM | 아파치 2.0 | ✅ | | 공공의 | Bookscorpus 및 영어 Wikipedia |
| chatglm | chatglm 라이센스 | | 불법적 인 목적이나 군사 연구에 사용되지 않음, 사회의 대중의 이익에 해를 끼치 지 않음 | N/A | 중국어와 영어 코퍼스의 1T 토큰 |
| 디코더 전용 |
| GPT2 | 수정 된 MIT 라이센스 | ✅ | GPT-2를 책임감있게 사용하고 컨텐츠가 GPT-2를 사용하여 작성되었음을 명확하게 나타냅니다. | 공공의 | 웹 텍스트 |
| gpt-neo | MIT 라이센스 | ✅ | | 공공의 | 말뚝 |
| GPT-J | 아파치 2.0 | ✅ | | 공공의 | 말뚝 |
| ---> 돌리 | NC 4.0의 CC | | | CC NC 4.0의 CC, OpenAI에서 생성 된 데이터의 사용에 따라 | 더미, 자기 강조 |
| ---> gpt4all-j | 아파치 2.0 | ✅ | | 공공의 | GPT4ALL-J 데이터 세트 |
| 피티아 | 아파치 2.0 | ✅ | | 공공의 | 말뚝 |
| ---> 돌리 V2 | MIT 라이센스 | ✅ | | 공공의 | 파일, 데이터 릭스 -dolly-15k |
| 고르다 | OPT-175B 라이센스 계약 | | 감시 연구 및 군사와 관련된 발전 없음, 사회의 공익에 해를 끼치 지 않음 | 공공의 | Roberta Corpus, 더미, pushshift.io reddit |
| ---> OPT-IML | OPT-175B 라이센스 계약 | | 선택과 동일합니다 | 공공의 | Opt Corpus, 확장 된 슈퍼-자연 신사 |
| yalm | 아파치 2.0 | ✅ | | 지정되지 않은 | 더미, 팀은 러시아어로 텍스트를 수집했습니다 |
| 꽃 | Bigscience 레일 라이센스 | ✅ | 다른 사람들에게 해를 끼칠 목적으로 유명한 허위 정보를 생성하는 사용은 없습니다.
텍스트가 기계가 생성된다는 것을 명시 적으로 부인하지 않고 콘텐츠 | 공공의 | 뿌리 코퍼스 (Lauren¸con et al., 2022) |
| ---> Bloomz | Bigscience 레일 라이센스 | ✅ | 꽃과 동일합니다 | 공공의 | 뿌리 코퍼스, xp3 |
| galactica | CC By-NC 4.0 | | | N/A | galactica 코퍼스 |
| 야마 | 비상업적 맞춤형 라이센스 | | 감시 연구 및 군사와 관련된 발전 없음, 사회의 공익에 해를 끼치 지 않음 | 공공의 | CommonCrawl, C4, Github, Wikipedia 등 |
| ---> 알파카 | NC 4.0의 CC | | | CC NC 4.0의 CC, OpenAI에서 생성 된 데이터의 사용에 따라 | 라마 코퍼스, 자기 강조 |
| ---> VICUNA | NC 4.0의 CC | | | OpenAI에 의해 생성 된 데이터의 사용에 따라;
ShareGpt의 개인 정보 보호 관행 | Llama Corpus, sharegpt.com의 70k 대화 |
| ---> gpt4all | GPL 라이센스 라마 | | | 공공의 | gpt4all 데이터 세트 |
| Openllama | 아파치 2.0 | ✅ | | 공공의 | 레드 파자마 |
| Codegeex | CodeGeex 라이센스 | | 불법적 인 목적이나 군사 연구에 사용되지 않습니다 | 공공의 | 더미, 코드 가르 로트 등 |
| 스타 코더 | BigCode OpenRail-M V1 라이센스 | ✅ | 다른 사람들에게 해를 끼칠 목적으로 유명한 허위 정보를 생성하는 사용은 없습니다.
텍스트가 기계가 생성된다는 것을 명시 적으로 부인하지 않고 콘텐츠 | 공공의 | 스택 |
| MPT-7B | 아파치 2.0 | ✅ | | 공공의 | MC4 (영어), 스택, Redpajama, S2ORC |
| 매 | Tii Falcon LLM 라이센스 | ✅/ | 상업용 사용 허용 라이센스에 따라 사용 가능합니다 | 공공의 | 정제 된 월 |
스타 역사


