SDGym
v0.9.1 - 2024-08-29
该存储库是datacebo项目的合成数据保险库项目的一部分。

合成数据健身房(SDGYM)是用于建模和生成合成数据的基准测试框架。测量不同合成数据建模技术的性能和记忆使用 - 经典统计,深度学习等等!
SDGYM库与合成数据保险库生态系统集成在一起。您可以将其任何合成器,数据集或指标用于基准测试。您还可以自定义该过程以包括自己的工作。
使用PIP或CONDA安装SDGYM。我们建议使用虚拟环境避免与设备上的其他软件发生冲突。
pip install sdgymconda install -c pytorch -c conda-forge sdgym有关使用SDGYM的更多信息,请访问SDGYM文档。
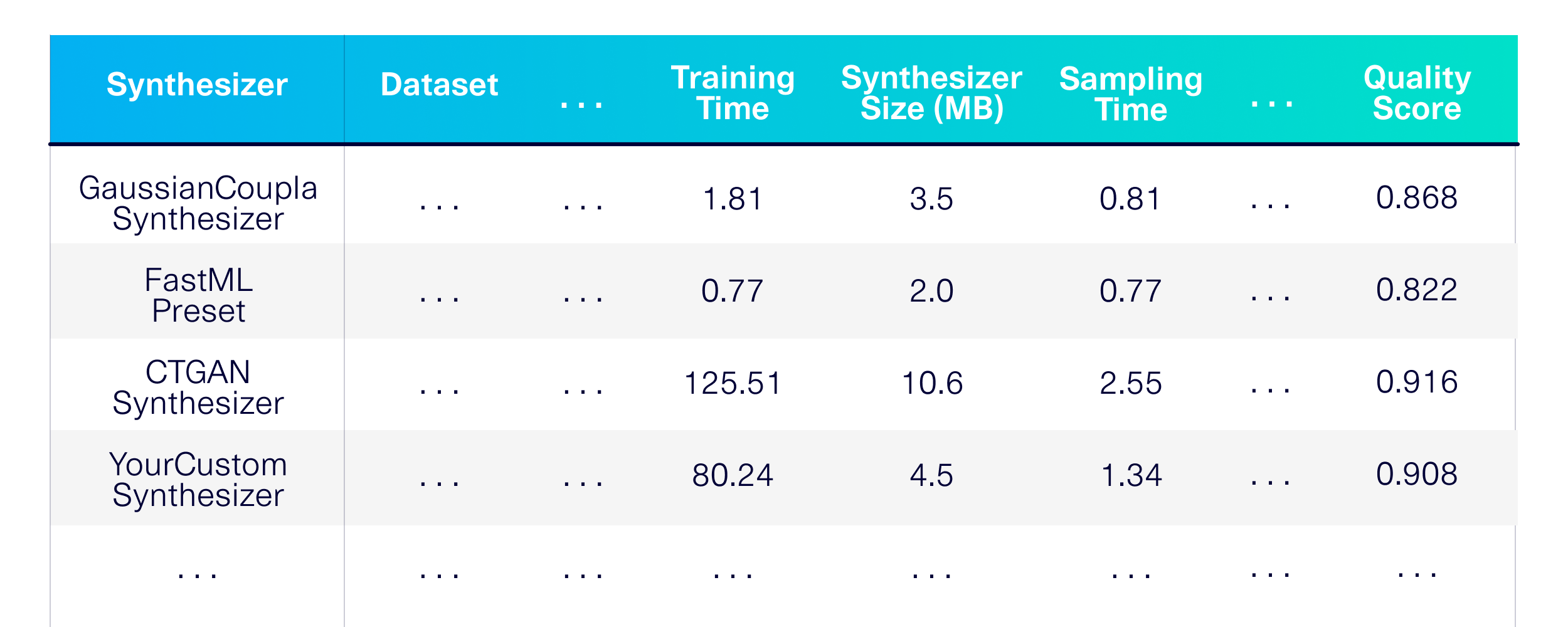
让我们对单表进行基准合成数据生成。首先,让我们定义要使用哪些建模技术。让我们从SDV库中选择一些合成器,以及其他一些用于基准的合成器。
# these synthesizers come from the SDV library
# each one uses different modeling techniques
sdv_synthesizers = [ 'GaussianCopulaSynthesizer' , 'CTGANSynthesizer' ]
# these basic synthesizers are available in SDGym
# as baselines
baseline_synthesizers = [ 'UniformSynthesizer' ]现在,我们可以对不同的技术进行基准测试:
import sdgym
sdgym . benchmark_single_table (
synthesizers = ( sdv_synthesizers + baseline_synthesizers )
)结果是在各种可公开可用的数据集上进行了详细的性能,内存和质量评估。
基准您自己的合成数据生成技术。通过指定训练逻辑(使用机器学习)和采样逻辑来定义合成器。
def my_training_logic ( data , metadata ):
# create an object to represent your synthesizer
# train it using the data
return synthesizer
def my_sampling_logic ( trained_synthesizer , num_rows ):
# use the trained synthesizer to create
# num_rows of synthetic data
return synthetic_data在“自定义合成器指南”中了解更多信息。
SDGYM库包含许多可立即包含的公开数据集。使用get_available_datasets功能列出这些功能。
sdgym . get_available_datasets () dataset_name size_MB num_tables
KRK_v1 0.072128 1
adult 3.907448 1
alarm 4.520128 1
asia 1.280128 1
...
您还可以在Amazon S3存储桶上存储在计算机上的任何自定义私有数据集。
my_datasets_folder = 's3://my-datasets-bucket'
有关更多信息,请参见文档以获取自定义数据集。
访问SDGYM文档以了解更多信息!

合成数据保险库项目最初是在2016年在MIT的数据中创建的。经过4年的企业研究和吸引力,我们于2020年创建了Datacebo,目的是发展该项目。如今,Datacebo已成为SDV的骄傲开发人员,SDV是合成数据生成和评估的最大生态系统。它是支持合成数据的多个库的所在地,包括:
开始使用SDV软件包 - 一种完全集成的解决方案,您的一站式商店以获取合成数据。或者,使用独立的库满足特定需求。


