SDGym
v0.9.1 - 2024-08-29
Ce référentiel fait partie du projet Synthetic Data Vault, un projet de DataceBo.

Le Synthetic Data Gym (SDGYM) est un cadre d'analyse comparative pour la modélisation et la génération de données synthétiques. Mesurer les performances et l'utilisation de la mémoire dans différentes techniques de modélisation des données synthétiques - statistiques classiques, apprentissage en profondeur et plus encore!
La bibliothèque SDGYM s'intègre à l'écosystème de vault de données synthétiques. Vous pouvez utiliser l'un de ses synthétiseurs, ensembles de données ou métriques pour l'analyse comparative. Vous pouvez également personnaliser le processus pour inclure votre propre travail.
Installez SDGYM à l'aide de PIP ou Conda. Nous vous recommandons d'utiliser un environnement virtuel pour éviter les conflits avec d'autres logiciels sur votre appareil.
pip install sdgymconda install -c pytorch -c conda-forge sdgymPour plus d'informations sur l'utilisation de SDGYM, visitez la documentation SDGYM.
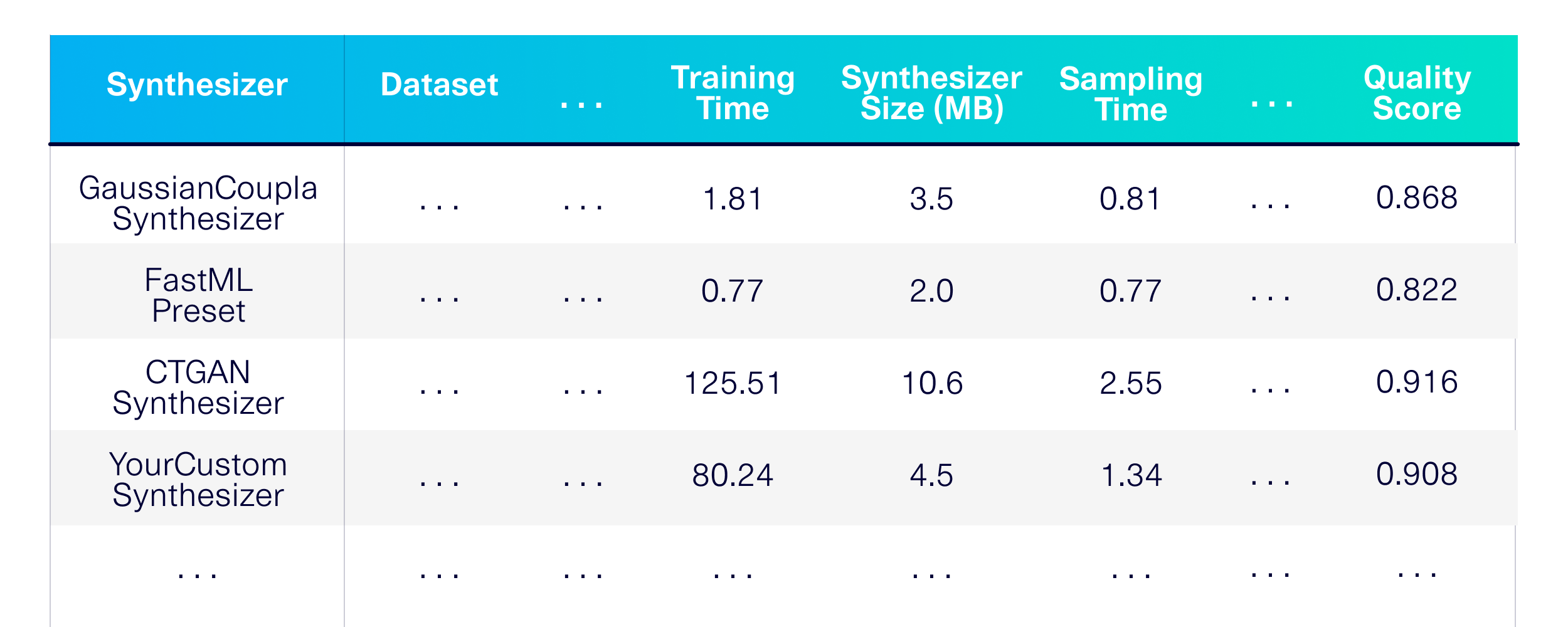
Benchmark Génération de données synthétiques pour les tables uniques. Tout d'abord, définissons les techniques de modélisation que nous voulons utiliser. Choisissons quelques synthétiseurs de la bibliothèque SDV et quelques autres à utiliser comme lignes de base.
# these synthesizers come from the SDV library
# each one uses different modeling techniques
sdv_synthesizers = [ 'GaussianCopulaSynthesizer' , 'CTGANSynthesizer' ]
# these basic synthesizers are available in SDGym
# as baselines
baseline_synthesizers = [ 'UniformSynthesizer' ]Maintenant, nous pouvons comparer les différentes techniques:
import sdgym
sdgym . benchmark_single_table (
synthesizers = ( sdv_synthesizers + baseline_synthesizers )
)Le résultat est une évaluation détaillée des performances, de la mémoire et de la qualité à travers les synthétiseurs sur une variété d'ensembles de données accessibles au public.
Préparez vos propres techniques de génération de données synthétiques. Définissez votre synthétiseur en spécifiant la logique de formation (en utilisant l'apprentissage automatique) et la logique d'échantillonnage.
def my_training_logic ( data , metadata ):
# create an object to represent your synthesizer
# train it using the data
return synthesizer
def my_sampling_logic ( trained_synthesizer , num_rows ):
# use the trained synthesizer to create
# num_rows of synthetic data
return synthetic_dataEn savoir plus dans le Guide des synthétiseurs personnalisés.
La bibliothèque SDGYM comprend de nombreux ensembles de données accessibles au public que vous pouvez inclure immédiatement. Énumérez-les à l'aide de la fonction get_available_datasets .
sdgym . get_available_datasets () dataset_name size_MB num_tables
KRK_v1 0.072128 1
adult 3.907448 1
alarm 4.520128 1
asia 1.280128 1
...
Vous pouvez également inclure tous les ensembles de données privés personnalisés qui sont stockés sur votre ordinateur sur un seau Amazon S3.
my_datasets_folder = 's3://my-datasets-bucket'
Pour plus d'informations, consultez les DOC pour les ensembles de données personnalisés.
Visitez la documentation SDGYM pour en savoir plus!

Le projet Synthetic Data Vault a été créé pour la première fois chez MIT's Data to AI Lab en 2016. Après 4 ans de recherche et de traction avec l'entreprise, nous avons créé Datacebo en 2020 dans le but de développer le projet. Aujourd'hui, Datacebo est le fier développeur de SDV, le plus grand écosystème de génération et d'évaluation de données synthétiques. Il abrite plusieurs bibliothèques qui prennent en charge les données synthétiques, notamment:
Commencez à utiliser le package SDV - une solution entièrement intégrée et votre guichet unique pour les données synthétiques. Ou utilisez les bibliothèques autonomes pour des besoins spécifiques.


