SDGym
v0.9.1 - 2024-08-29
Этот репозиторий является частью проекта «Синтетические данные хранилища данных», проект от DataCebo.

Синтетическое тренажерный зал (SDGYM) представляет собой сравнительную систему для моделирования и генерации синтетических данных. Измерить производительность и использование памяти в различных методах моделирования синтетических данных - классическая статистика, глубокое обучение и многое другое!
Библиотека SDGYM интегрируется с экосистемой хранилища синтетических данных. Вы можете использовать любой из его синтезаторов, наборов данных или метрик для сравнительного анализа. Вы также можете настроить процесс, чтобы включить свою собственную работу.
Установите SDGYM с помощью PIP или CONDA. Мы рекомендуем использовать виртуальную среду, чтобы избежать конфликтов с другим программным обеспечением на вашем устройстве.
pip install sdgymconda install -c pytorch -c conda-forge sdgymДля получения дополнительной информации об использовании SDGYM посетите документацию SDGYM.
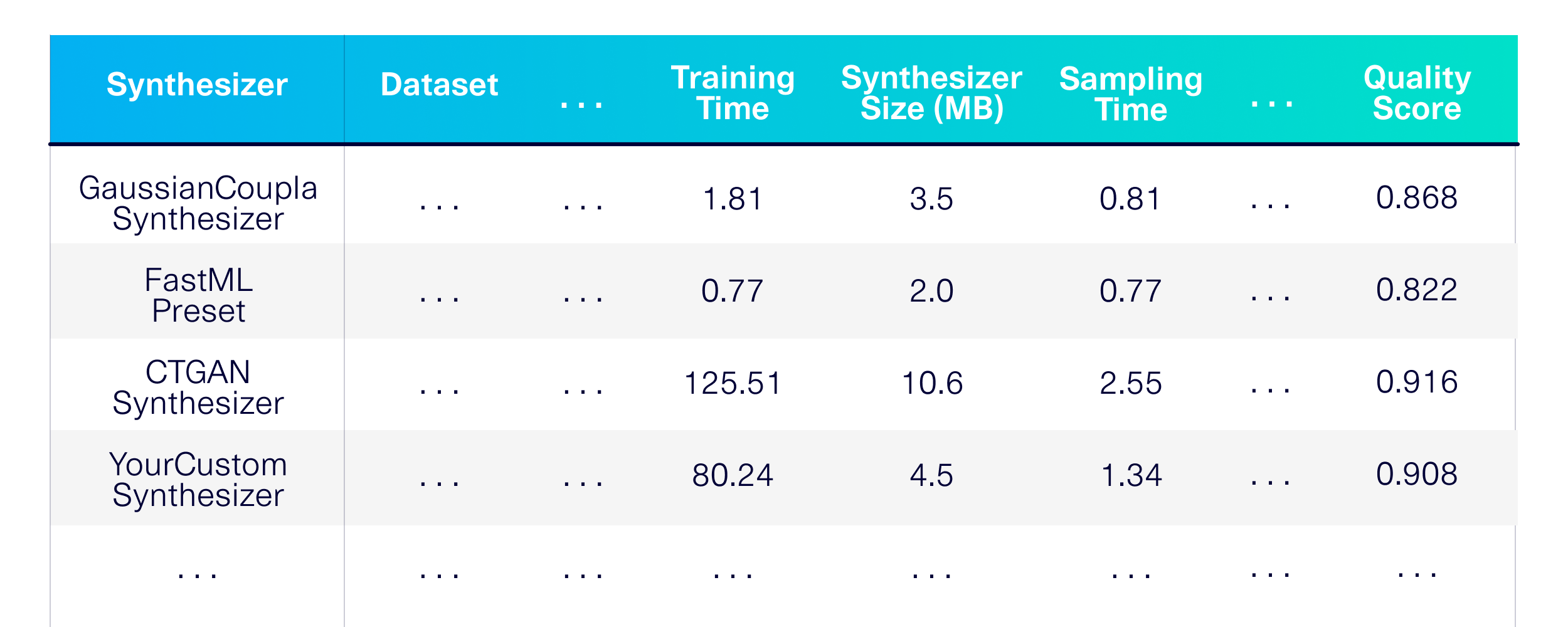
Давайте сравниваем генерацию синтетических данных для отдельных таблиц. Во -первых, давайте определим, какие методы моделирования мы хотим использовать. Давайте выберем несколько синтезаторов из библиотеки SDV и нескольких других, которые можно использовать в качестве базовых линий.
# these synthesizers come from the SDV library
# each one uses different modeling techniques
sdv_synthesizers = [ 'GaussianCopulaSynthesizer' , 'CTGANSynthesizer' ]
# these basic synthesizers are available in SDGym
# as baselines
baseline_synthesizers = [ 'UniformSynthesizer' ]Теперь мы можем сравнить различные методы:
import sdgym
sdgym . benchmark_single_table (
synthesizers = ( sdv_synthesizers + baseline_synthesizers )
)Результатом является подробная оценка производительности, памяти и качества в синтезаторах на различных общедоступных наборах данных.
Считайте свои собственные методы генерации синтетических данных. Определите свой синтезатор, указав логику обучения (с использованием машинного обучения) и логику выборки.
def my_training_logic ( data , metadata ):
# create an object to represent your synthesizer
# train it using the data
return synthesizer
def my_sampling_logic ( trained_synthesizer , num_rows ):
# use the trained synthesizer to create
# num_rows of synthetic data
return synthetic_dataУзнайте больше в руководстве по индивидуальным синтезаторам.
Библиотека SDGYM включает в себя множество общедоступных наборов данных, которые вы можете сразу включить. Перечислите их, используя функцию get_available_datasets .
sdgym . get_available_datasets () dataset_name size_MB num_tables
KRK_v1 0.072128 1
adult 3.907448 1
alarm 4.520128 1
asia 1.280128 1
...
Вы также можете включить любые пользовательские, частные наборы данных, которые хранятся на вашем компьютере на ведре Amazon S3.
my_datasets_folder = 's3://my-datasets-bucket'
Для получения дополнительной информации см. Документы для настраиваемых наборов данных.
Посетите документацию SDGYM, чтобы узнать больше!

Проект хранилища с синтетическими данными был впервые создан в MIT Data To AI Lab в 2016 году. После 4 лет исследований и тяги с предприятием мы создали DataCebo в 2020 году с целью развития проекта. Сегодня DataCebo является гордым разработчиком SDV, крупнейшей экосистемы для генерации и оценки синтетических данных. Он является домом для нескольких библиотек, которые поддерживают синтетические данные, в том числе:
Начните использовать пакет SDV-полностью интегрированное решение и универсальный магазин для синтетических данных. Или используйте отдельные библиотеки для конкретных потребностей.


