SDGym
v0.9.1 - 2024-08-29
Este repositório faz parte do projeto Synthetic Data Vault, um projeto da Datacebo.

O ginásio de dados sintéticos (SDGYM) é uma estrutura de benchmarking para modelar e gerar dados sintéticos. Meça o desempenho e o uso da memória em diferentes técnicas de modelagem de dados sintéticos - estatísticas clássicas, aprendizado profundo e muito mais!
A biblioteca SDGYM se integra ao ecossistema sintético do Vault. Você pode usar qualquer um de seus sintetizadores, conjuntos de dados ou métricas para benchmarking. Você também pode personalizar o processo para incluir seu próprio trabalho.
Instale o SDGYM usando PIP ou CONDA. Recomendamos o uso de um ambiente virtual para evitar conflitos com outro software no seu dispositivo.
pip install sdgymconda install -c pytorch -c conda-forge sdgymPara obter mais informações sobre o uso do SDGYM, visite a documentação do SDGYM.
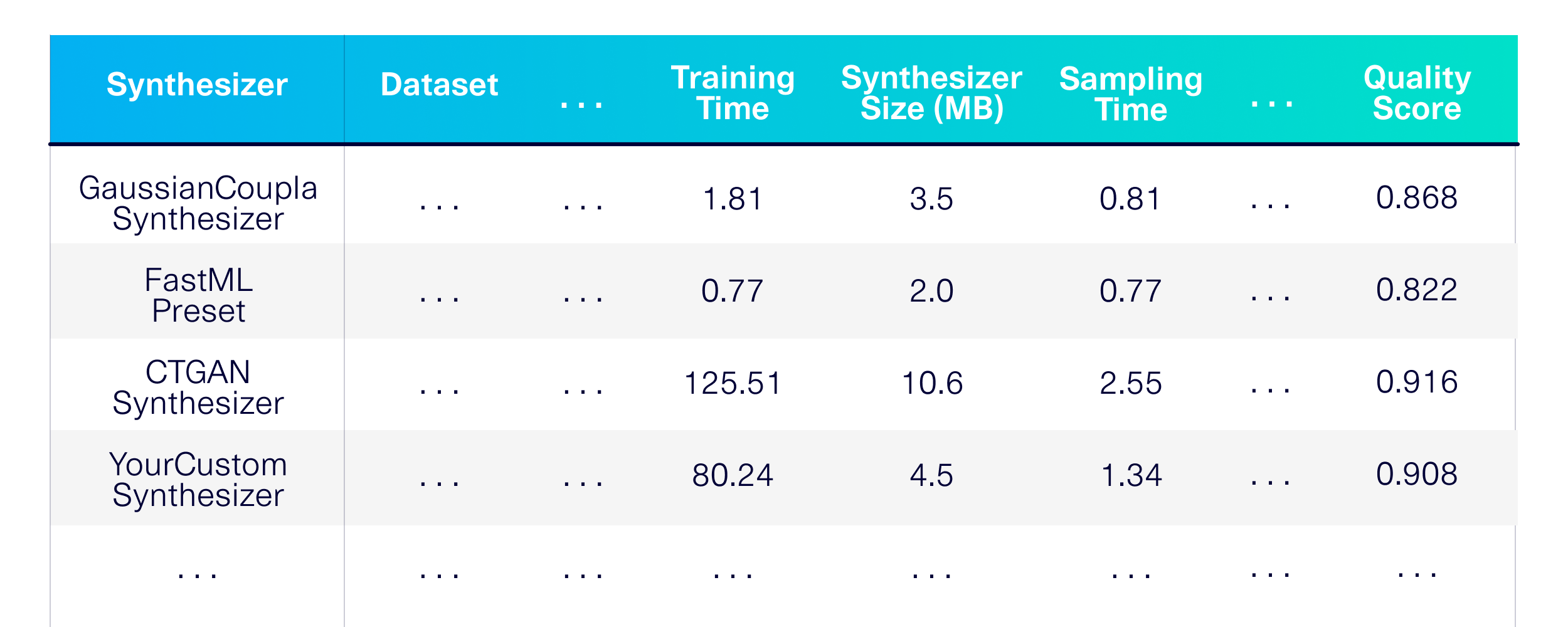
Vamos realizar a geração de dados sintéticos para tabelas únicas. Primeiro, vamos definir quais técnicas de modelagem que queremos usar. Vamos escolher alguns sintetizadores da biblioteca SDV e alguns outros para usar como linhas de base.
# these synthesizers come from the SDV library
# each one uses different modeling techniques
sdv_synthesizers = [ 'GaussianCopulaSynthesizer' , 'CTGANSynthesizer' ]
# these basic synthesizers are available in SDGym
# as baselines
baseline_synthesizers = [ 'UniformSynthesizer' ]Agora, podemos comparar as diferentes técnicas:
import sdgym
sdgym . benchmark_single_table (
synthesizers = ( sdv_synthesizers + baseline_synthesizers )
)O resultado é uma avaliação detalhada de desempenho, memória e qualidade nos sintetizadores em uma variedade de conjuntos de dados disponíveis ao público.
Realize suas próprias técnicas de geração de dados sintéticos. Defina seu sintetizador especificando a lógica de treinamento (usando o aprendizado de máquina) e a lógica de amostragem.
def my_training_logic ( data , metadata ):
# create an object to represent your synthesizer
# train it using the data
return synthesizer
def my_sampling_logic ( trained_synthesizer , num_rows ):
# use the trained synthesizer to create
# num_rows of synthetic data
return synthetic_dataSaiba mais no guia de sintetizadores personalizados.
A biblioteca SDGYM inclui muitos conjuntos de dados disponíveis ao público que você pode incluir imediatamente. Liste -os usando o recurso get_available_datasets .
sdgym . get_available_datasets () dataset_name size_MB num_tables
KRK_v1 0.072128 1
adult 3.907448 1
alarm 4.520128 1
asia 1.280128 1
...
Você também pode incluir quaisquer conjuntos de dados privados personalizados armazenados no seu computador em um balde Amazon S3.
my_datasets_folder = 's3://my-datasets-bucket'
Para obter mais informações, consulte os documentos para conjuntos de dados personalizados.
Visite a documentação do SDGYM para saber mais!

O projeto Synthetic Data Vault foi criado pela primeira vez no MIT Data to AI Lab em 2016. Após 4 anos de pesquisa e tração com a Enterprise, criamos Datacebo em 2020 com o objetivo de aumentar o projeto. Hoje, o Datacebo é o orgulhoso desenvolvedor do SDV, o maior ecossistema para geração e avaliação de dados sintéticos. É o lar de várias bibliotecas que suportam dados sintéticos, incluindo:
Comece a usar o pacote SDV-uma solução totalmente integrada e sua loja única para obter dados sintéticos. Ou use as bibliotecas independentes para necessidades específicas.


