SDGym
v0.9.1 - 2024-08-29
Repositori ini adalah bagian dari proyek Data Vault sintetis, proyek dari DataCebo.

Gym Data Sintetis (SDGYM) adalah kerangka pembandingan untuk pemodelan dan menghasilkan data sintetis. Ukur kinerja dan penggunaan memori di berbagai teknik pemodelan data sintetis - statistik klasik, pembelajaran mendalam dan banyak lagi!
Perpustakaan SDGYM terintegrasi dengan ekosistem data sintetis. Anda dapat menggunakan salah satu synthesizer, set data, atau metrik untuk pembandingan. Anda juga dapat menyesuaikan proses untuk memasukkan pekerjaan Anda sendiri.
Pasang SDGYM menggunakan Pip atau Conda. Kami merekomendasikan penggunaan lingkungan virtual untuk menghindari konflik dengan perangkat lunak lain di perangkat Anda.
pip install sdgymconda install -c pytorch -c conda-forge sdgymUntuk informasi lebih lanjut tentang penggunaan SDGYM, kunjungi dokumentasi SDGYM.
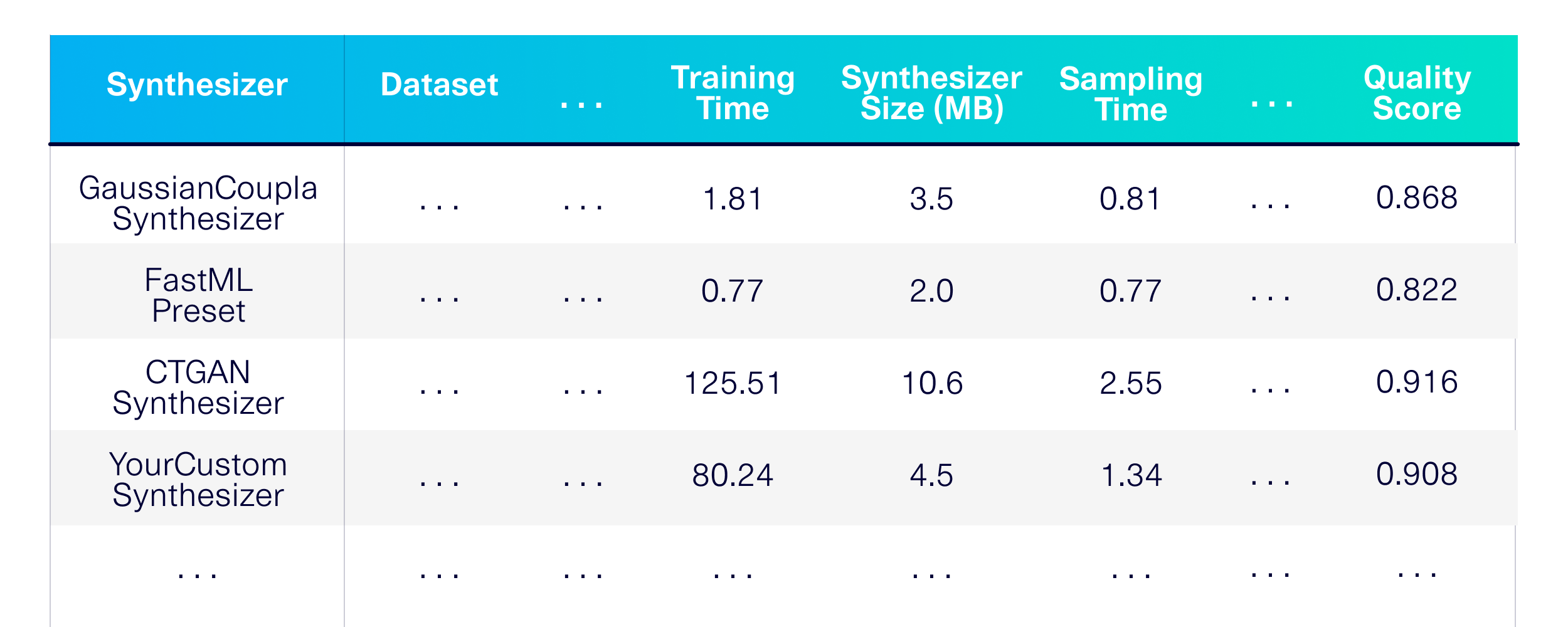
Mari Benchmark Pembuatan Data Sintetis untuk Tabel Tunggal. Pertama, mari kita tentukan teknik pemodelan mana yang ingin kami gunakan. Mari kita pilih beberapa synthesizer dari perpustakaan SDV dan beberapa lainnya untuk digunakan sebagai garis dasar.
# these synthesizers come from the SDV library
# each one uses different modeling techniques
sdv_synthesizers = [ 'GaussianCopulaSynthesizer' , 'CTGANSynthesizer' ]
# these basic synthesizers are available in SDGym
# as baselines
baseline_synthesizers = [ 'UniformSynthesizer' ]Sekarang, kita dapat membandingkan teknik yang berbeda:
import sdgym
sdgym . benchmark_single_table (
synthesizers = ( sdv_synthesizers + baseline_synthesizers )
)Hasilnya adalah kinerja terperinci, memori dan evaluasi kualitas di seluruh synthesizer pada berbagai set data yang tersedia untuk umum.
Benchmark teknik pembuatan data sintetis Anda sendiri. Tentukan synthesizer Anda dengan menentukan logika pelatihan (menggunakan pembelajaran mesin) dan logika pengambilan sampel.
def my_training_logic ( data , metadata ):
# create an object to represent your synthesizer
# train it using the data
return synthesizer
def my_sampling_logic ( trained_synthesizer , num_rows ):
# use the trained synthesizer to create
# num_rows of synthetic data
return synthetic_dataPelajari lebih lanjut di panduan Synthesizers khusus.
Perpustakaan SDGYM mencakup banyak set data yang tersedia untuk umum yang dapat Anda sertakan segera. Sebutkan ini menggunakan fitur get_available_datasets .
sdgym . get_available_datasets () dataset_name size_MB num_tables
KRK_v1 0.072128 1
adult 3.907448 1
alarm 4.520128 1
asia 1.280128 1
...
Anda juga dapat memasukkan dataset kustom, pribadi yang disimpan di komputer Anda pada ember Amazon S3.
my_datasets_folder = 's3://my-datasets-bucket'
Untuk informasi lebih lanjut, lihat dokumen untuk set data yang disesuaikan.
Kunjungi dokumentasi SDGYM untuk mempelajari lebih lanjut!

Proyek Data Vault sintetis pertama kali dibuat di MIT's Data ke AI Lab pada tahun 2016. Setelah 4 tahun penelitian dan traksi dengan Enterprise, kami membuat DataCebo pada tahun 2020 dengan tujuan mengembangkan proyek. Hari ini, DataCebo adalah pengembang bangga SDV, ekosistem terbesar untuk pembuatan & evaluasi data sintetis. Ini adalah rumah bagi beberapa perpustakaan yang mendukung data sintetis, termasuk:
Mulailah menggunakan paket SDV-solusi terintegrasi penuh dan toko serba ada untuk data sintetis. Atau, gunakan pustaka mandiri untuk kebutuhan spesifik.


