SDGym
v0.9.1 - 2024-08-29
يعد هذا المستودع جزءًا من مشروع Vault Data Synthetic ، وهو مشروع من Datacebo.

صالة الألعاب الرياضية الاصطناعية (SDGYM) هي إطار قياسي لنمذجة وتوليد البيانات الاصطناعية. قياس الأداء واستخدام الذاكرة عبر تقنيات نمذجة البيانات الاصطناعية المختلفة - الإحصاءات الكلاسيكية ، والتعلم العميق والمزيد!
تتكامل مكتبة SDGYM مع النظام الإيكولوجي للبيانات الاصطناعية. يمكنك استخدام أي من مجموعات التوليفات أو مجموعات البيانات أو مقاييسها للقياس. يمكنك أيضًا تخصيص العملية لتضمين عملك.
تثبيت SDGYM باستخدام PIP أو Conda. نوصي باستخدام بيئة افتراضية لتجنب التعارض مع البرامج الأخرى على جهازك.
pip install sdgymconda install -c pytorch -c conda-forge sdgymلمزيد من المعلومات حول استخدام SDGYM ، تفضل بزيارة وثائق SDGYM.
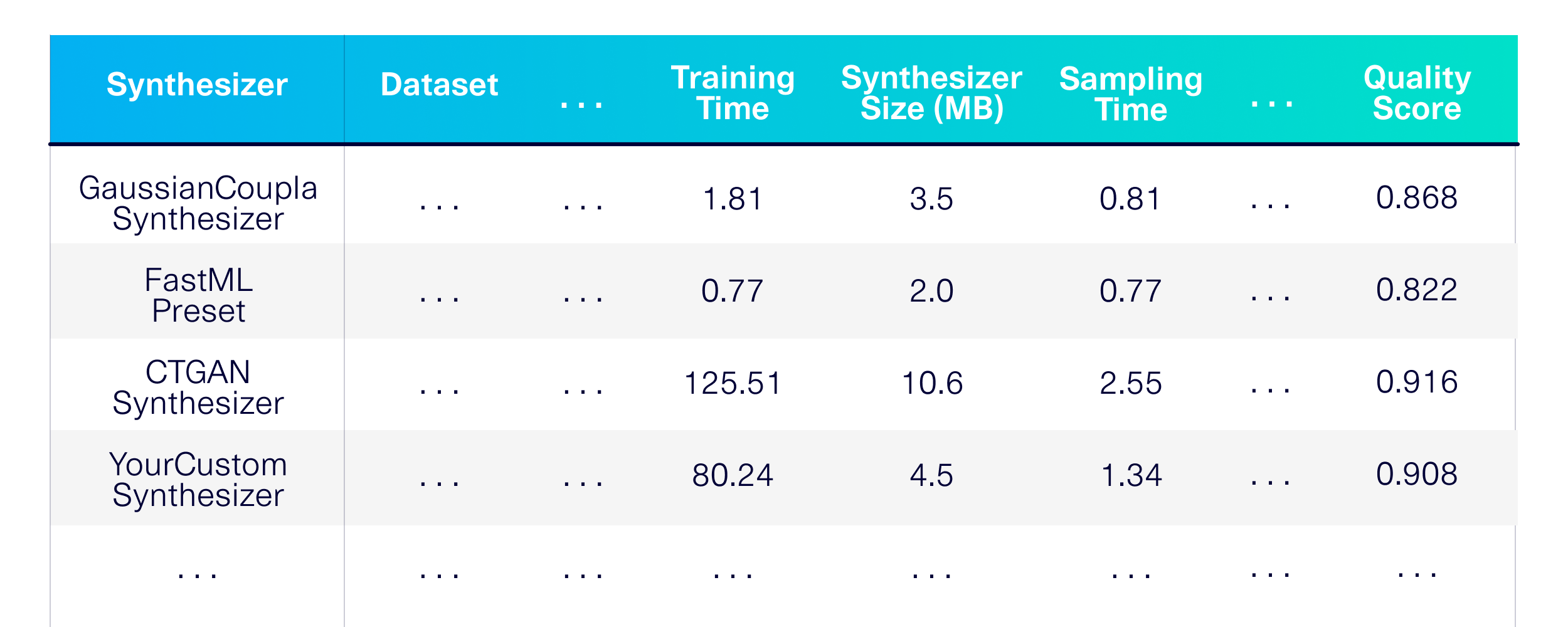
دعنا نرتبط بتوليد البيانات الاصطناعية للجداول الفردية. أولاً ، دعونا نحدد تقنيات النمذجة التي نريد استخدامها. دعنا نختار بعض المزيج من مكتبة SDV وعدد قليل من الآخرين لاستخدامها كخطوط الأساس.
# these synthesizers come from the SDV library
# each one uses different modeling techniques
sdv_synthesizers = [ 'GaussianCopulaSynthesizer' , 'CTGANSynthesizer' ]
# these basic synthesizers are available in SDGym
# as baselines
baseline_synthesizers = [ 'UniformSynthesizer' ]الآن ، يمكننا أن نقترب من التقنيات المختلفة:
import sdgym
sdgym . benchmark_single_table (
synthesizers = ( sdv_synthesizers + baseline_synthesizers )
)والنتيجة هي أداء مفصل وذاكرة وتقييم الجودة عبر المزيج على مجموعة متنوعة من مجموعات البيانات المتاحة للجمهور.
القياس تقنيات توليد البيانات الاصطناعية الخاصة بك. حدد المركب الخاص بك عن طريق تحديد منطق التدريب (باستخدام التعلم الآلي) ومنطق أخذ العينات.
def my_training_logic ( data , metadata ):
# create an object to represent your synthesizer
# train it using the data
return synthesizer
def my_sampling_logic ( trained_synthesizer , num_rows ):
# use the trained synthesizer to create
# num_rows of synthetic data
return synthetic_dataتعرف على المزيد في دليل توليفات مخصص.
تتضمن مكتبة SDGYM العديد من مجموعات البيانات المتاحة للجمهور التي يمكنك تضمينها على الفور. قائمة هذه باستخدام ميزة get_available_datasets .
sdgym . get_available_datasets () dataset_name size_MB num_tables
KRK_v1 0.072128 1
adult 3.907448 1
alarm 4.520128 1
asia 1.280128 1
...
يمكنك أيضًا تضمين أي مجموعات بيانات خاصة مخصصة يتم تخزينها على جهاز الكمبيوتر الخاص بك على دلو Amazon S3.
my_datasets_folder = 's3://my-datasets-bucket'
لمزيد من المعلومات ، راجع مستندات مجموعات البيانات المخصصة.
قم بزيارة وثائق SDGYM لمعرفة المزيد!

تم إنشاء مشروع Vault Data Synthetic لأول مرة في بيانات معهد ماساتشوستس للتكنولوجيا إلى مختبر AI في عام 2016. بعد 4 سنوات من البحث والجر مع Enterprise ، أنشأنا Datacebo في عام 2020 بهدف تنمية المشروع. اليوم ، Datacebo هو المطور الفخور لـ SDV ، أكبر نظام بيئي لتوليد وتقييم البيانات الاصطناعية. إنها موطن لمكتبات متعددة تدعم البيانات الاصطناعية ، بما في ذلك:
ابدأ باستخدام حزمة SDV-حل متكامل بالكامل ومتجر التوقف الخاص بك للبيانات الاصطناعية. أو استخدم المكتبات المستقلة لتلبية الاحتياجات المحددة.


